 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGDiffusion: Faithful Cloth Generation via External Knowledge Assimilation
Nov 29, 2024



Standard clothing asset generation involves creating forward-facing flat-lay garment images displayed on a clear background by extracting clothing information from diverse real-world contexts, which presents significant challenges due to highly standardized sampling distributions and precise structural requirements in the generated images. Existing models have limited spatial perception and often exhibit structural hallucinations in this high-specification generative task. To address this issue, we propose a novel Retrieval-Augmented Generation (RAG) framework, termed RAGDiffusion, to enhance structure determinacy and mitigate hallucinations by assimilating external knowledge from LLM and databases. RAGDiffusion consists of two core processes: (1) Retrieval-based structure aggregation, which employs contrastive learning and a Structure Locally Linear Embedding (SLLE) to derive global structure and spatial landmarks, providing both soft and hard guidance to counteract structural ambiguities; and (2) Omni-level faithful garment generation, which introduces a three-level alignment that ensures fidelity in structural, pattern, and decoding components within the diffusing. Extensive experiments on challenging real-world datasets demonstrate that RAGDiffusion synthesizes structurally and detail-faithful clothing assets with significant performance improvements, representing a pioneering effort in high-specification faithful generation with RAG to confront intrinsic hallucinations and enhance fidelity.
Combining Attention with Flow for Person Image Synthesis
Aug 04, 2021

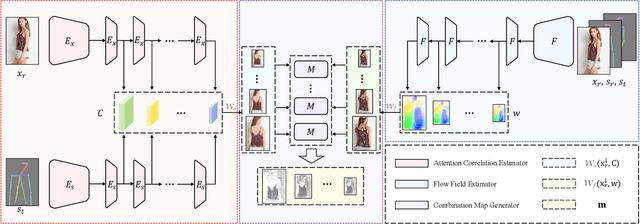
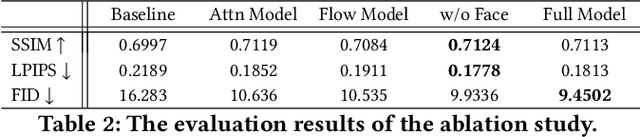
Pose-guided person image synthesis aims to synthesize person images by transforming reference images into target poses. In this paper, we observe that the commonly used spatial transformation blocks have complementary advantages. We propose a novel model by combining the attention operation with the flow-based operation. Our model not only takes the advantage of the attention operation to generate accurate target structures but also uses the flow-based operation to sample realistic source textures. Both objective and subjective experiments demonstrate the superiority of our model. Meanwhile, comprehensive ablation studies verify our hypotheses and show the efficacy of the proposed modules. Besides, additional experiments on the portrait image editing task demonstrate the versatility of the proposed combination.