 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional FDR Control for Sub-Gaussian Sparse GLMs
May 02, 2021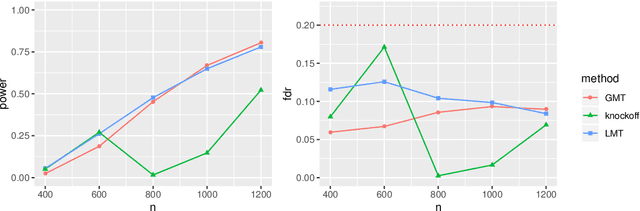
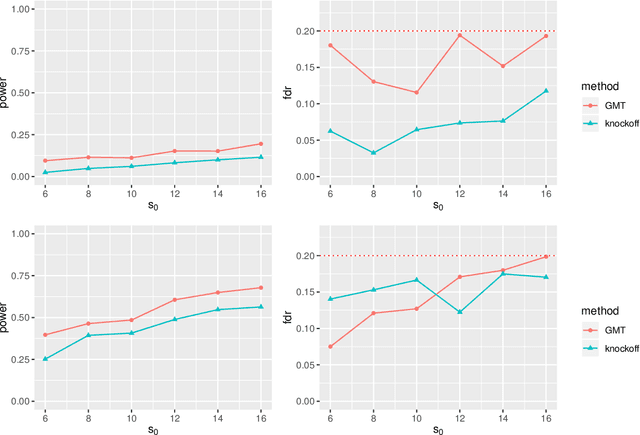
High-dimensional sparse generalized linear models (GLMs) have emerged in the setting that the number of samples and the dimension of variables are large, and even the dimension of variables grows faster than the number of samples. False discovery rate (FDR) control aims to identify some small number of statistically significantly nonzero results after getting the sparse penalized estimation of GLMs. Using the CLIME method for precision matrix estimations, we construct the debiased-Lasso estimator and prove the asymptotical normality by minimax-rate oracle inequalities for sparse GLMs. In practice, it is often needed to accurately judge each regression coefficient's positivity and negativity, which determines whether the predictor variable is positively or negatively related to the response variable conditionally on the rest variables. Using the debiased estimator, we establish multiple testing procedures. Under mild conditions, we show that the proposed debiased statistics can asymptotically control the directional (sign) FDR and directional false discovery variables at a pre-specified significance level. Moreover, it can be shown that our multiple testing procedure can approximately achieve a statistical power of 1. We also extend our methods to the two-sample problems and propose the two-sample test statistics. Under suitable conditions, we can asymptotically achieve directional FDR control and directional FDV control at the specified significance level for two-sample problems. Some numerical simulations have successfully verified the FDR control effects of our proposed testing procedures, which sometimes outperforms the classical knockoff method.
On Hallucination and Predictive Uncertainty in Conditional Language Generation
Mar 28, 2021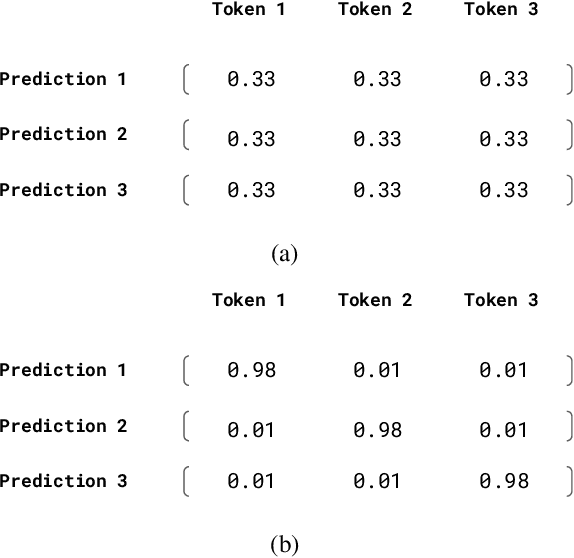
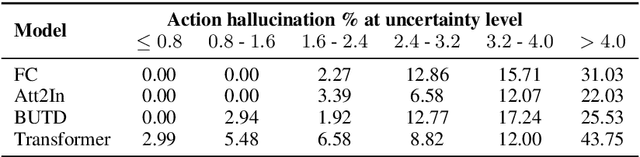
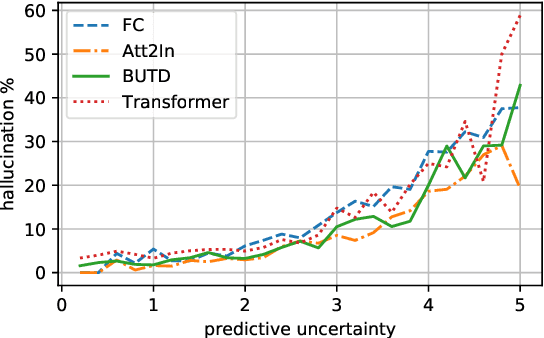
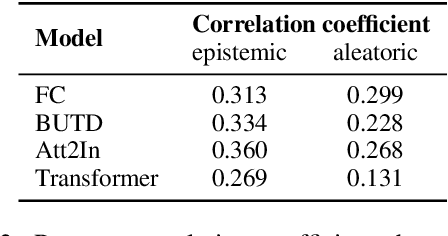
Despite improvements in performances on different natural language generation tasks, deep neural models are prone to hallucinating facts that are incorrect or nonexistent. Different hypotheses are proposed and examined separately for different tasks, but no systematic explanations are available across these tasks. In this study, we draw connections between hallucinations and predictive uncertainty in conditional language generation. We investigate their relationship in both image captioning and data-to-text generation and propose a simple extension to beam search to reduce hallucination. Our analysis shows that higher predictive uncertainty corresponds to a higher chance of hallucination. Epistemic uncertainty is more indicative of hallucination than aleatoric or total uncertainties. It helps to achieve better results of trading performance in standard metric for less hallucination with the proposed beam search variant.
Why Neural Machine Translation Prefers Empty Outputs
Dec 24, 2020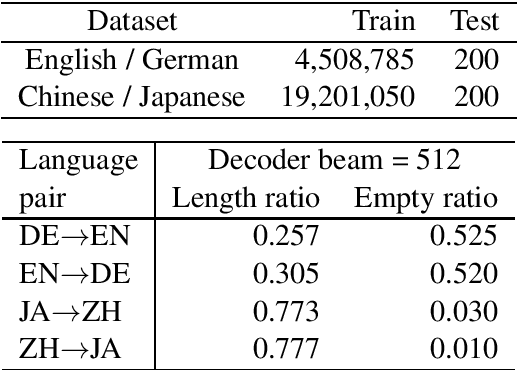
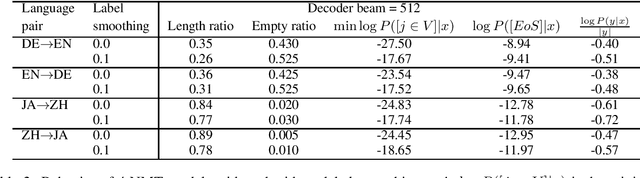
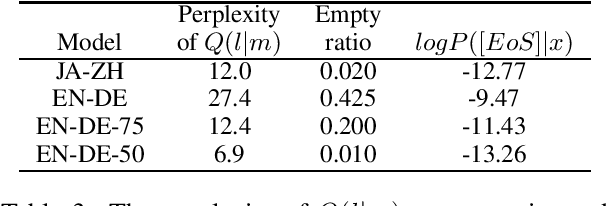
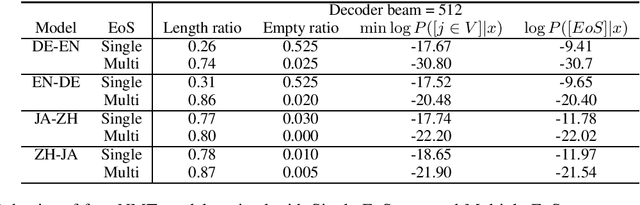
We investigate why neural machine translation (NMT) systems assign high probability to empty translations. We find two explanations. First, label smoothing makes correct-length translations less confident, making it easier for the empty translation to finally outscore them. Second, NMT systems use the same, high-frequency EoS word to end all target sentences, regardless of length. This creates an implicit smoothing that increases zero-length translations. Using different EoS types in target sentences of different lengths exposes and eliminates this implicit smoothing.
Disentangled Representation Learning with Wasserstein Total Correlation
Dec 30, 2019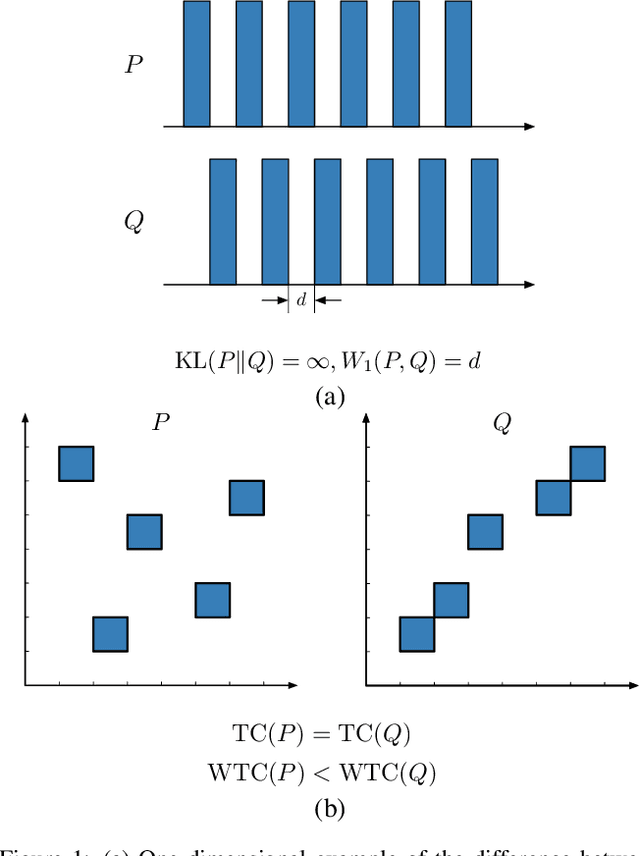
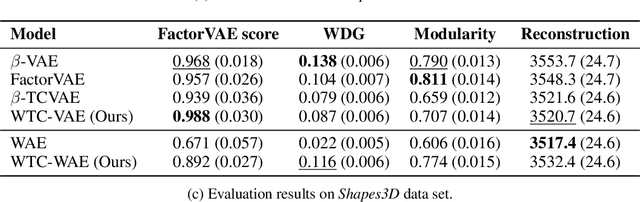
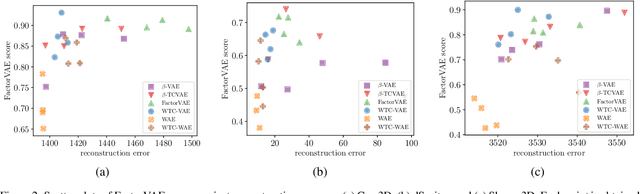
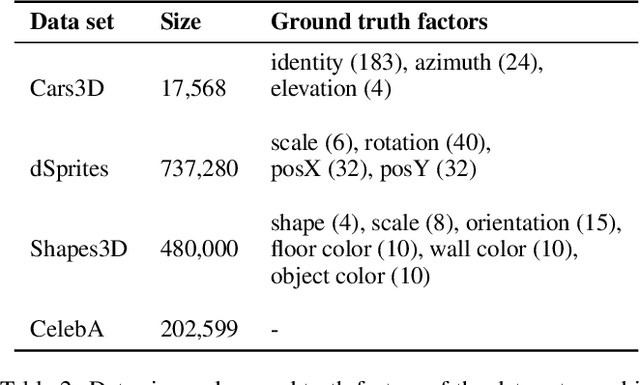
Unsupervised learning of disentangled representations involves uncovering of different factors of variations that contribute to the data generation process. Total correlation penalization has been a key component in recent methods towards disentanglement. However, Kullback-Leibler (KL) divergence-based total correlation is metric-agnostic and sensitive to data samples. In this paper, we introduce Wasserstein total correlation in both variational autoencoder and Wasserstein autoencoder settings to learn disentangled latent representations. A critic is adversarially trained along with the main objective to estimate the Wasserstein total correlation term. We discuss the benefits of using Wasserstein distance over KL divergence to measure independence and conduct quantitative and qualitative experiments on several data sets. Moreover, we introduce a new metric to measure disentanglement. We show that the proposed approach has comparable performances on disentanglement with smaller sacrifices in reconstruction abilities.
Text Modeling with Syntax-Aware Variational Autoencoders
Aug 27, 2019
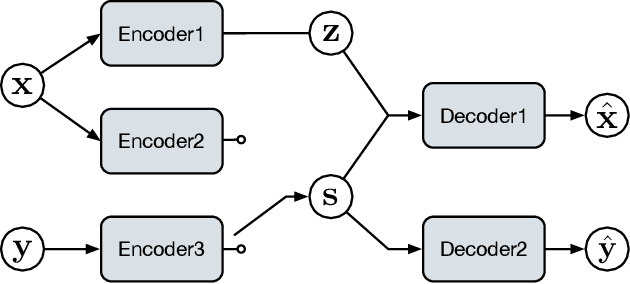
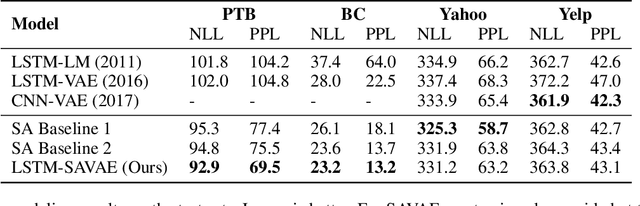
Syntactic information contains structures and rules about how text sentences are arranged. Incorporating syntax into text modeling methods can potentially benefit both representation learning and generation. Variational autoencoders (VAEs) are deep generative models that provide a probabilistic way to describe observations in the latent space. When applied to text data, the latent representations are often unstructured. We propose syntax-aware variational autoencoders (SAVAEs) that dedicate a subspace in the latent dimensions dubbed syntactic latent to represent syntactic structures of sentences. SAVAEs are trained to infer syntactic latent from either text inputs or parsed syntax results as well as reconstruct original text with inferred latent variables. Experiments show that SAVAEs are able to achieve lower reconstruction loss on four different data sets. Furthermore, they are capable of generating examples with modified target syntax.
Quantifying Uncertainties in Natural Language Processing Tasks
Nov 18, 2018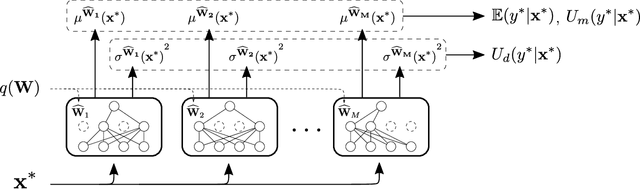

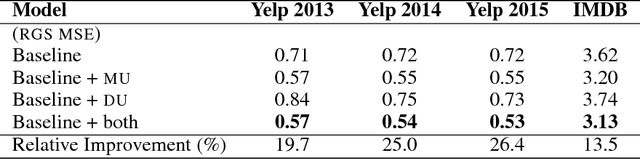
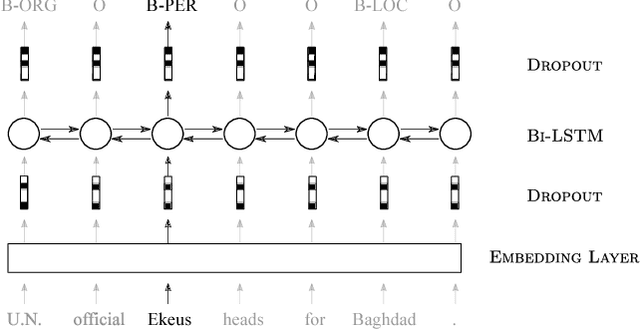
Reliable uncertainty quantification is a first step towards building explainable, transparent, and accountable artificial intelligent systems. Recent progress in Bayesian deep learning has made such quantification realizable. In this paper, we propose novel methods to study the benefits of characterizing model and data uncertainties for natural language processing (NLP) tasks. With empirical experiments on sentiment analysis, named entity recognition, and language modeling using convolutional and recurrent neural network models, we show that explicitly modeling uncertainties is not only necessary to measure output confidence levels, but also useful at enhancing model performances in various NLP tasks.
Implicit Regularization of Stochastic Gradient Descent in Natural Language Processing: Observations and Implications
Nov 01, 2018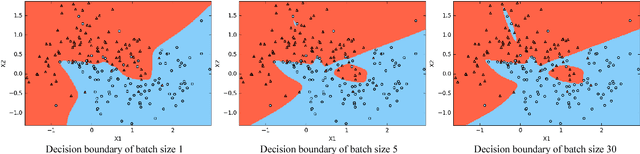
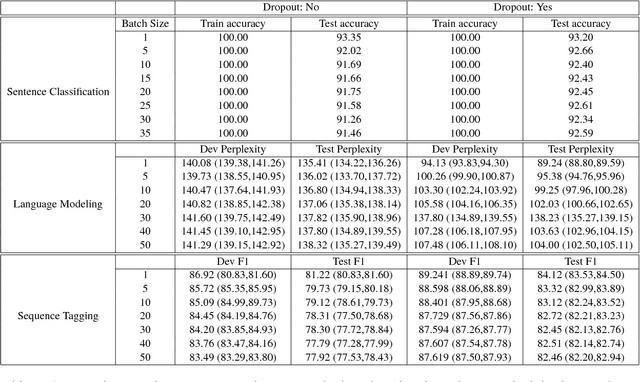
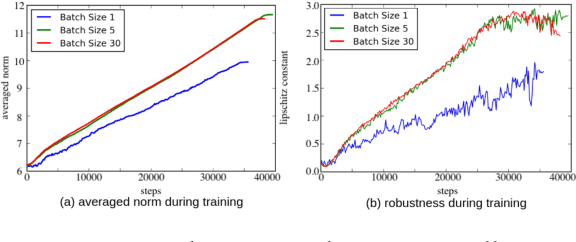

Deep neural networks with remarkably strong generalization performances are usually over-parameterized. Despite explicit regularization strategies are used for practitioners to avoid over-fitting, the impacts are often small. Some theoretical studies have analyzed the implicit regularization effect of stochastic gradient descent (SGD) on simple machine learning models with certain assumptions. However, how it behaves practically in state-of-the-art models and real-world datasets is still unknown. To bridge this gap, we study the role of SGD implicit regularization in deep learning systems. We show pure SGD tends to converge to minimas that have better generalization performances in multiple natural language processing (NLP) tasks. This phenomenon coexists with dropout, an explicit regularizer. In addition, neural network's finite learning capability does not impact the intrinsic nature of SGD's implicit regularization effect. Specifically, under limited training samples or with certain corrupted labels, the implicit regularization effect remains strong. We further analyze the stability by varying the weight initialization range. We corroborate these experimental findings with a decision boundary visualization using a 3-layer neural network for interpretation. Altogether, our work enables a deepened understanding on how implicit regularization affects the deep learning model and sheds light on the future study of the over-parameterized model's generalization ability.
Dirichlet Variational Autoencoder for Text Modeling
Oct 31, 2018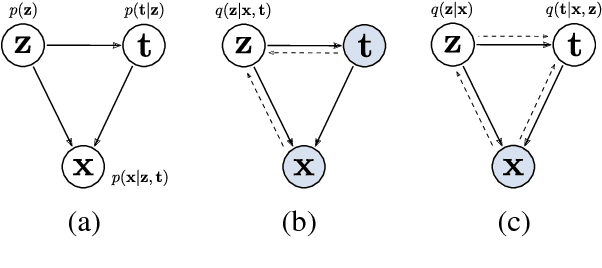
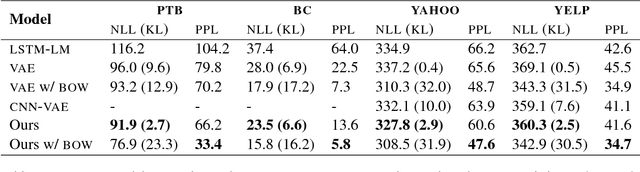
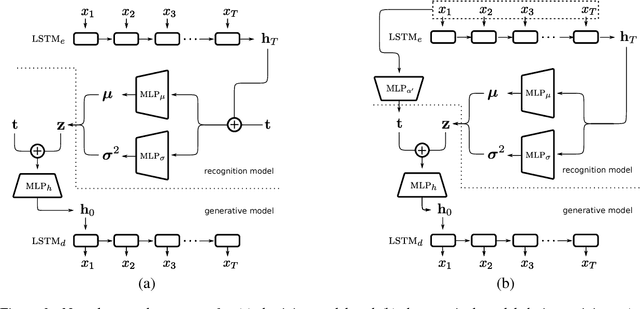
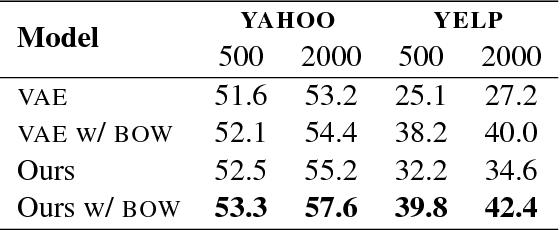
We introduce an improved variational autoencoder (VAE) for text modeling with topic information explicitly modeled as a Dirichlet latent variable. By providing the proposed model topic awareness, it is more superior at reconstructing input texts. Furthermore, due to the inherent interactions between the newly introduced Dirichlet variable and the conventional multivariate Gaussian variable, the model is less prone to KL divergence vanishing. We derive the variational lower bound for the new model and conduct experiments on four different data sets. The results show that the proposed model is superior at text reconstruction across the latent space and classifications on learned representations have higher test accuracies.
Tree-Structured Neural Machine for Linguistics-Aware Sentence Generation
Jan 03, 2018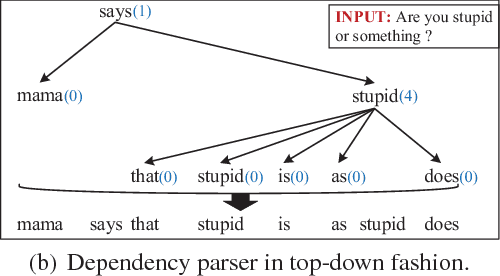
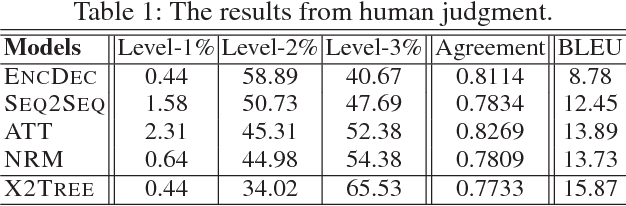
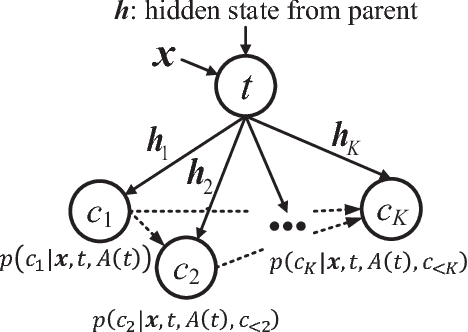
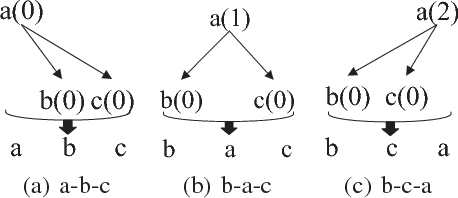
Different from other sequential data, sentences in natural language are structured by linguistic grammars. Previous generative conversational models with chain-structured decoder ignore this structure in human language and might generate plausible responses with less satisfactory relevance and fluency. In this study, we aim to incorporate the results from linguistic analysis into the process of sentence generation for high-quality conversation generation. Specifically, we use a dependency parser to transform each response sentence into a dependency tree and construct a training corpus of sentence-tree pairs. A tree-structured decoder is developed to learn the mapping from a sentence to its tree, where different types of hidden states are used to depict the local dependencies from an internal tree node to its children. For training acceleration, we propose a tree canonicalization method, which transforms trees into equivalent ternary trees. Then, with a proposed tree-structured search method, the model is able to generate the most probable responses in the form of dependency trees, which are finally flattened into sequences as the system output. Experimental results demonstrate that the proposed X2Tree framework outperforms baseline methods over 11.15% increase of acceptance ratio.
Efficient Character-level Document Classification by Combining Convolution and Recurrent Layers
Feb 01, 2016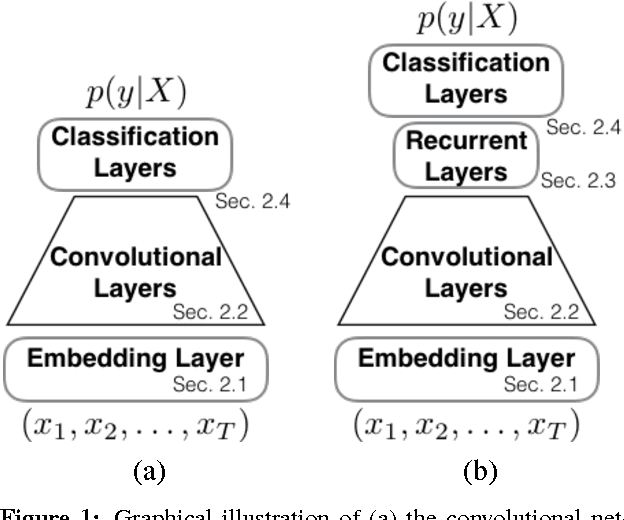
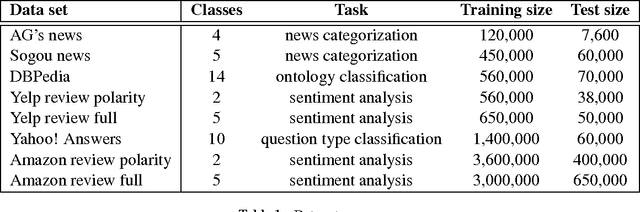
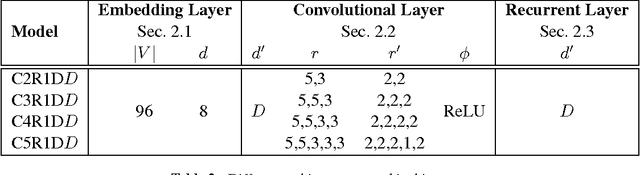
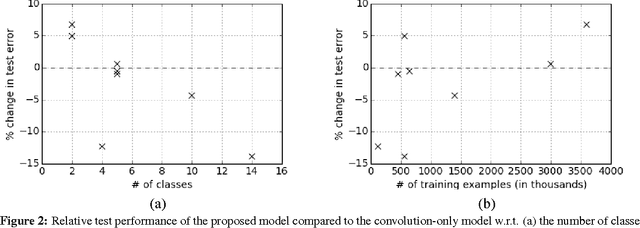
Document classification tasks were primarily tackled at word level. Recent research that works with character-level inputs shows several benefits over word-level approaches such as natural incorporation of morphemes and better handling of rare words. We propose a neural network architecture that utilizes both convolution and recurrent layers to efficiently encode character inputs. We validate the proposed model on eight large scale document classification tasks and compare with character-level convolution-only models. It achieves comparable performances with much less parameters.