 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
Paper and Code
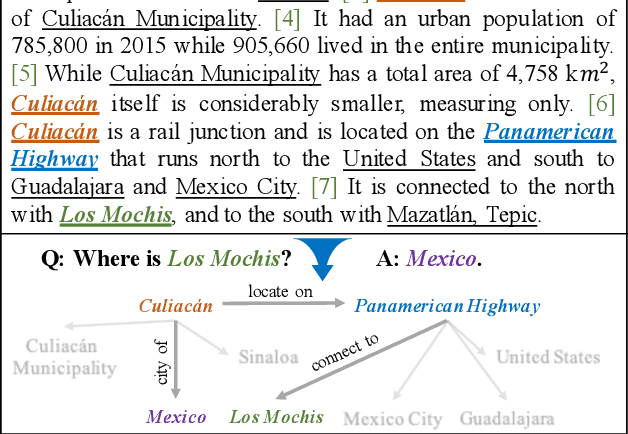
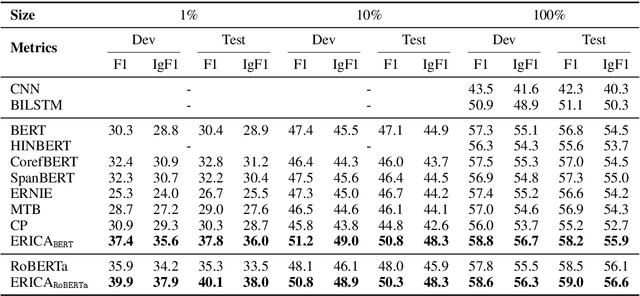
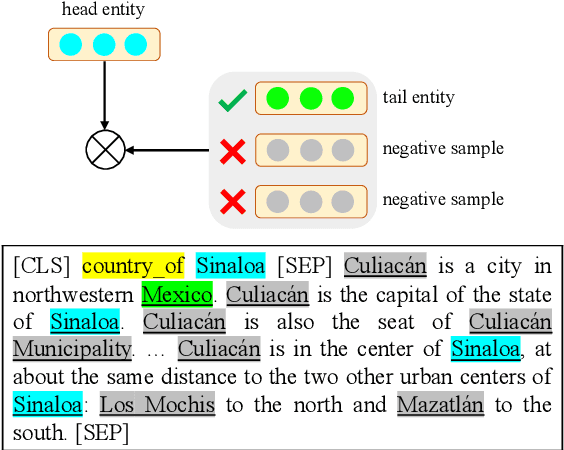
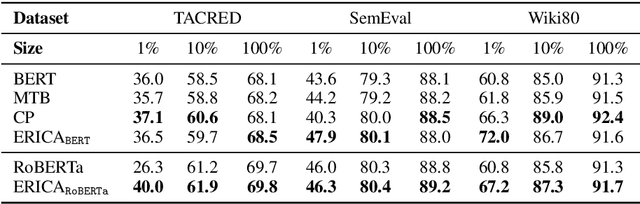
Pre-trained Language Models (PLMs) have shown strong performance in various downstream Natural Language Processing (NLP) tasks. However, PLMs still cannot well capture the factual knowledge in the text, which is crucial for understanding the whole text, especially for document-level language understanding tasks. To address this issue, we propose a novel contrastive learning framework named ERICA in pre-training phase to obtain a deeper understanding of the entities and their relations in text. Specifically, (1) to better understand entities, we propose an entity discrimination task that distinguishes which tail entity can be inferred by the given head entity and relation. (2) Besides, to better understand relations, we employ a relation discrimination task which distinguishes whether two entity pairs are close or not in relational semantics. Experimental results demonstrate that our proposed ERICA framework achieves consistent improvements on several document-level language understanding tasks, including relation extraction and reading comprehension, especially under low resource setting. Meanwhile, ERICA achieves comparable or better performance on sentence-level tasks. We will release the datasets, source codes and pre-trained language models for further research explorations.