 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManual-Guided Dialogue for Flexible Conversational Agents
Paper and Code
Aug 16, 2022
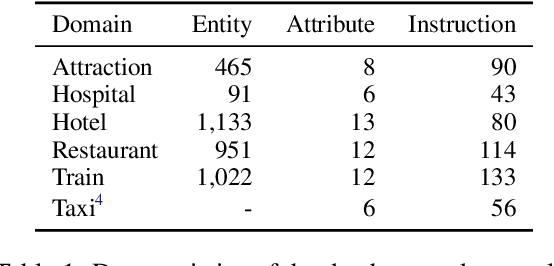


How to build and use dialogue data efficiently, and how to deploy models in different domains at scale can be two critical issues in building a task-oriented dialogue system. In this paper, we propose a novel manual-guided dialogue scheme to alleviate these problems, where the agent learns the tasks from both dialogue and manuals. The manual is an unstructured textual document that guides the agent in interacting with users and the database during the conversation. Our proposed scheme reduces the dependence of dialogue models on fine-grained domain ontology, and makes them more flexible to adapt to various domains. We then contribute a fully-annotated multi-domain dataset MagDial to support our scheme. It introduces three dialogue modeling subtasks: instruction matching, argument filling, and response generation. Modeling these subtasks is consistent with the human agent's behavior patterns. Experiments demonstrate that the manual-guided dialogue scheme improves data efficiency and domain scalability in building dialogue systems. The dataset and benchmark will be publicly available for promoting future research.