 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
ColorizeDiffusion v2: Enhancing Reference-based Sketch Colorization Through Separating Utilities
Apr 09, 2025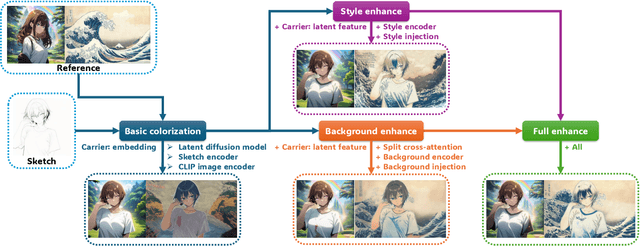


Reference-based sketch colorization methods have garnered significant attention due to their potential applications in the animation production industry. However, most existing methods are trained with image triplets of sketch, reference, and ground truth that are semantically and spatially well-aligned, while real-world references and sketches often exhibit substantial misalignment. This mismatch in data distribution between training and inference leads to overfitting, consequently resulting in spatial artifacts and significant degradation in overall colorization quality, limiting potential applications of current methods for general purposes. To address this limitation, we conduct an in-depth analysis of the \textbf{carrier}, defined as the latent representation facilitating information transfer from reference to sketch. Based on this analysis, we propose a novel workflow that dynamically adapts the carrier to optimize distinct aspects of colorization. Specifically, for spatially misaligned artifacts, we introduce a split cross-attention mechanism with spatial masks, enabling region-specific reference injection within the diffusion process. To mitigate semantic neglect of sketches, we employ dedicated background and style encoders to transfer detailed reference information in the latent feature space, achieving enhanced spatial control and richer detail synthesis. Furthermore, we propose character-mask merging and background bleaching as preprocessing steps to improve foreground-background integration and background generation. Extensive qualitative and quantitative evaluations, including a user study, demonstrate the superior performance of our proposed method compared to existing approaches. An ablation study further validates the efficacy of each proposed component.
Image Referenced Sketch Colorization Based on Animation Creation Workflow
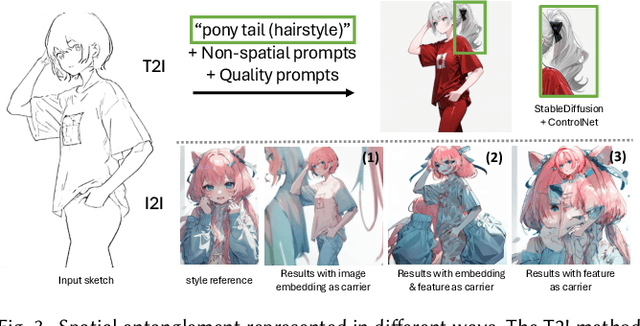
Feb 27, 2025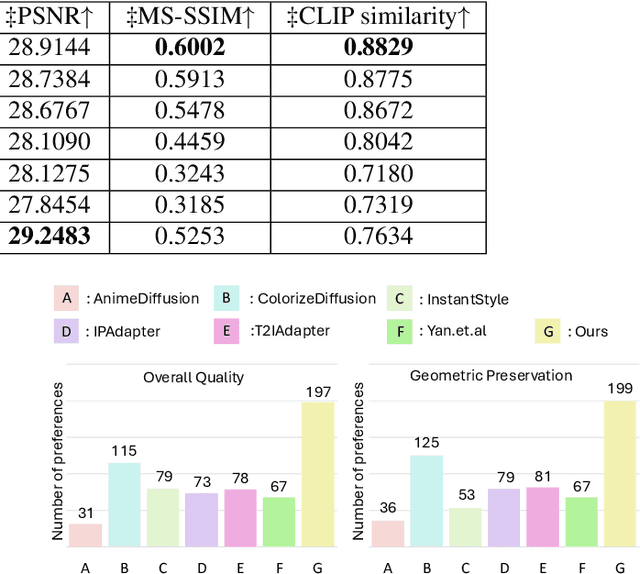
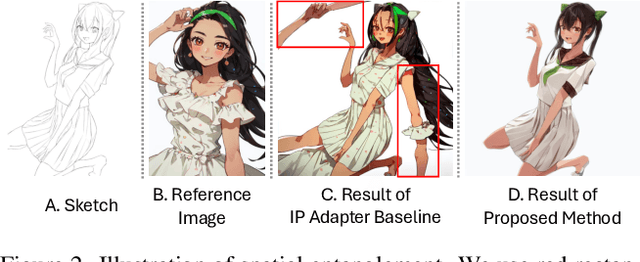

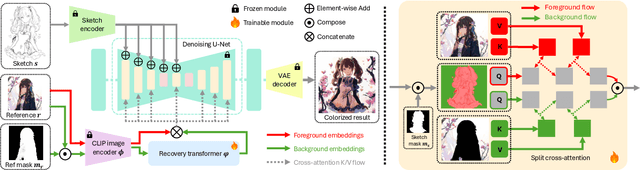
Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
ColorizeDiffusion: Adjustable Sketch Colorization with Reference Image and Text
Jan 02, 2024Recently, diffusion models have demonstrated their effectiveness in generating extremely high-quality images and have found wide-ranging applications, including automatic sketch colorization. However, most existing models use text to guide the conditional generation, with fewer attempts exploring the potential advantages of using image tokens as conditional inputs for networks. As such, this paper exhaustively investigates image-guided models, specifically targeting reference-based sketch colorization, which aims to colorize sketch images using reference color images. We investigate three critical aspects of reference-based diffusion models: the shortcomings compared to text-based counterparts, the training strategies, and the capability in zero-shot, sequential text-based manipulation. We introduce two variations of an image-guided latent diffusion model using different image tokens from the pre-trained CLIP image encoder, and we propose corresponding manipulation methods to adjust their results sequentially using weighted text inputs. We conduct comprehensive evaluations of our models through qualitative and quantitative experiments, as well as a user study.