 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Mesh Saliency GT Acquisition in VR via View Cone Sampling and Geometric Smoothing
Jan 06, 2026Reliable 3D mesh saliency ground truth (GT) is essential for human-centric visual modeling in virtual reality (VR). However, current 3D mesh saliency GT acquisition methods are generally consistent with 2D image methods, ignoring the differences between 3D geometry topology and 2D image array. Current VR eye-tracking pipelines rely on single ray sampling and Euclidean smoothing, triggering texture attention and signal leakage across gaps. This paper proposes a robust framework to address these limitations. We first introduce a view cone sampling (VCS) strategy, which simulates the human foveal receptive field via Gaussian-distributed ray bundles to improve sampling robustness for complex topologies. Furthermore, a hybrid Manifold-Euclidean constrained diffusion (HCD) algorithm is developed, fusing manifold geodesic constraints with Euclidean scales to ensure topologically-consistent saliency propagation. By mitigating "topological short-circuits" and aliasing, our framework provides a high-fidelity 3D attention acquisition paradigm that aligns with natural human perception, offering a more accurate and robust baseline for 3D mesh saliency research.
CLAP: Coreference-Linked Augmentation for Passage Retrieval
Aug 09, 2025Large Language Model (LLM)-based passage expansion has shown promise for enhancing first-stage retrieval, but often underperforms with dense retrievers due to semantic drift and misalignment with their pretrained semantic space. Beyond this, only a portion of a passage is typically relevant to a query, while the rest introduces noise--an issue compounded by chunking techniques that break coreference continuity. We propose Coreference-Linked Augmentation for Passage Retrieval (CLAP), a lightweight LLM-based expansion framework that segments passages into coherent chunks, resolves coreference chains, and generates localized pseudo-queries aligned with dense retriever representations. A simple fusion of global topical signals and fine-grained subtopic signals achieves robust performance across domains. CLAP yields consistent gains even as retriever strength increases, enabling dense retrievers to match or surpass second-stage rankers such as BM25 + MonoT5-3B, with up to 20.68% absolute nDCG@10 improvement. These improvements are especially notable in out-of-domain settings, where conventional LLM-based expansion methods relying on domain knowledge often falter. CLAP instead adopts a logic-centric pipeline that enables robust, domain-agnostic generalization.
Embodied Image Quality Assessment for Robotic Intelligence
Dec 25, 2024Image quality assessment (IQA) of user-generated content (UGC) is a critical technique for human quality of experience (QoE). However, for robot-generated content (RGC), will its image quality be consistent with the Moravec paradox and counter to human common sense? Human subjective scoring is more based on the attractiveness of the image. Embodied agent are required to interact and perceive in the environment, and finally perform specific tasks. Visual images as inputs directly influence downstream tasks. In this paper, we first propose an embodied image quality assessment (EIQA) frameworks. We establish assessment metrics for input images based on the downstream tasks of robot. In addition, we construct an Embodied Preference Database (EPD) containing 5,000 reference and distorted image annotations. The performance of mainstream IQA algorithms on EPD dataset is finally verified. The experiments demonstrate that quality assessment of embodied images is different from that of humans. We sincerely hope that the EPD can contribute to the development of embodied AI by focusing on image quality assessment. The benchmark is available at https://github.com/Jianbo-maker/EPD_benchmark.
ColorizeDiffusion: Adjustable Sketch Colorization with Reference Image and Text
Jan 02, 2024Recently, diffusion models have demonstrated their effectiveness in generating extremely high-quality images and have found wide-ranging applications, including automatic sketch colorization. However, most existing models use text to guide the conditional generation, with fewer attempts exploring the potential advantages of using image tokens as conditional inputs for networks. As such, this paper exhaustively investigates image-guided models, specifically targeting reference-based sketch colorization, which aims to colorize sketch images using reference color images. We investigate three critical aspects of reference-based diffusion models: the shortcomings compared to text-based counterparts, the training strategies, and the capability in zero-shot, sequential text-based manipulation. We introduce two variations of an image-guided latent diffusion model using different image tokens from the pre-trained CLIP image encoder, and we propose corresponding manipulation methods to adjust their results sequentially using weighted text inputs. We conduct comprehensive evaluations of our models through qualitative and quantitative experiments, as well as a user study.
An Accurate and Efficient Large-scale Regression Method through Best Friend Clustering
Apr 22, 2021

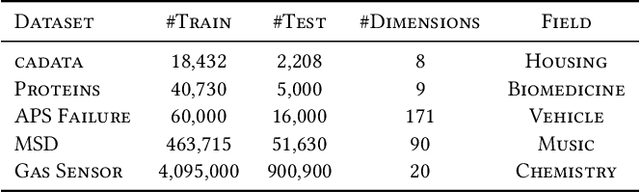
As the data size in Machine Learning fields grows exponentially, it is inevitable to accelerate the computation by utilizing the ever-growing large number of available cores provided by high-performance computing hardware. However, existing parallel methods for clustering or regression often suffer from problems of low accuracy, slow convergence, and complex hyperparameter-tuning. Furthermore, the parallel efficiency is usually difficult to improve while striking a balance between preserving model properties and partitioning computing workloads on distributed systems. In this paper, we propose a novel and simple data structure capturing the most important information among data samples. It has several advantageous properties supporting a hierarchical clustering strategy that is irrelevant to the hardware parallelism, well-defined metrics for determining optimal clustering, balanced partition for maintaining the compactness property, and efficient parallelization for accelerating computation phases. Then we combine the clustering with regression techniques as a parallel library and utilize a hybrid structure of data and model parallelism to make predictions. Experiments illustrate that our library obtains remarkable performance on convergence, accuracy, and scalability.
A Concept Knowledge-Driven Keywords Retrieval Framework for Sponsored Search
Feb 21, 2021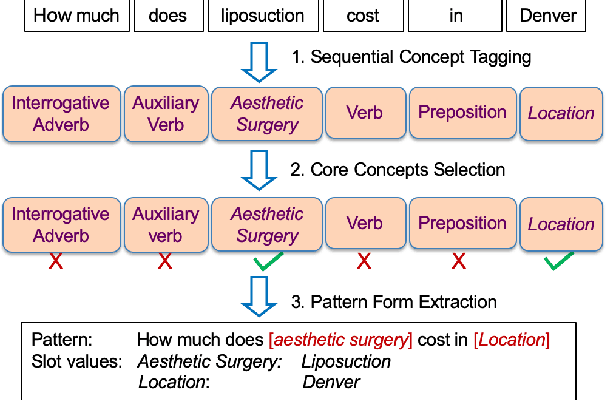

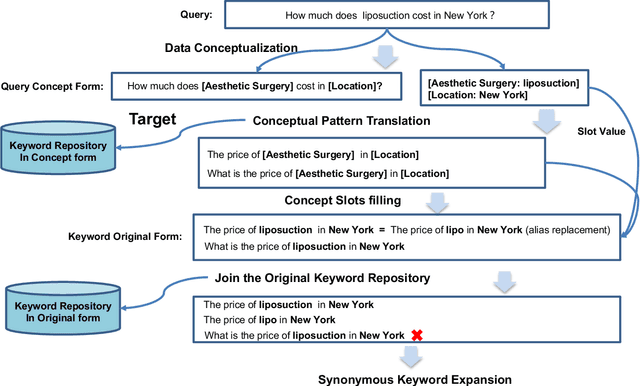
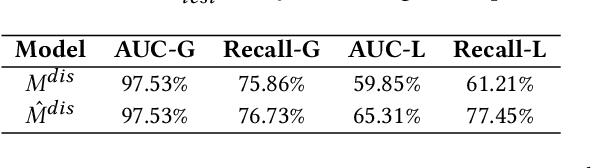
In sponsored search, retrieving synonymous keywords for exact match type is important for accurately targeted advertising. Data-driven deep learning-based method has been proposed to tackle this problem. An apparent disadvantage of this method is its poor generalization performance on entity-level long-tail instances, even though they might share similar concept-level patterns with frequent instances. With the help of a large knowledge base, we find that most commercial synonymous query-keyword pairs can be abstracted into meaningful conceptual patterns through concept tagging. Based on this fact, we propose a novel knowledge-driven conceptual retrieval framework to mitigate this problem, which consists of three parts: data conceptualization, matching via conceptual patterns and concept-augmented discrimination. Both offline and online experiments show that our method is very effective. This framework has been successfully applied to Baidu's sponsored search system, which yields a significant improvement in revenue.
Optimizing AD Pruning of Sponsored Search with Reinforcement Learning
Aug 05, 2020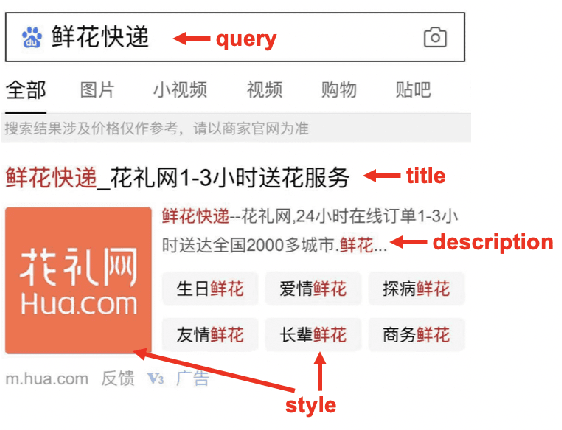

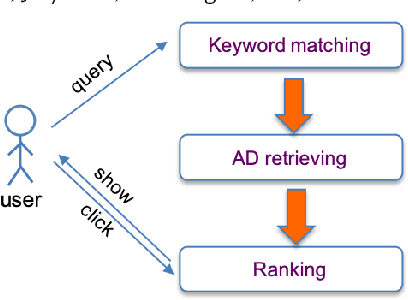
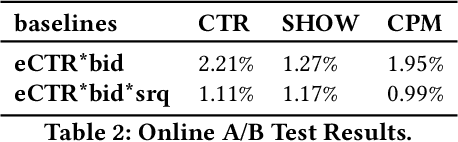
Industrial sponsored search system (SSS) can be logically divided into three modules: keywords matching, ad retrieving, and ranking. During ad retrieving, the ad candidates grow exponentially. A query with high commercial value might retrieve a great deal of ad candidates such that the ranking module could not afford. Due to limited latency and computing resources, the candidates have to be pruned earlier. Suppose we set a pruning line to cut SSS into two parts: upstream and downstream. The problem we are going to address is: how to pick out the best $K$ items from $N$ candidates provided by the upstream to maximize the total system's revenue. Since the industrial downstream is very complicated and updated quickly, a crucial restriction in this problem is that the selection scheme should get adapted to the downstream. In this paper, we propose a novel model-free reinforcement learning approach to fixing this problem. Our approach considers downstream as a black-box environment, and the agent sequentially selects items and finally feeds into the downstream, where revenue would be estimated and used as a reward to improve the selection policy. To the best of our knowledge, this is first time to consider the system optimization from a downstream adaption view. It is also the first time to use reinforcement learning techniques to tackle this problem. The idea has been successfully realized in Baidu's sponsored search system, and online long time A/B test shows remarkable improvements on revenue.
Enhancement of land-use change modeling using convolutional neural networks and convolutional denoising autoencoders
Mar 03, 2018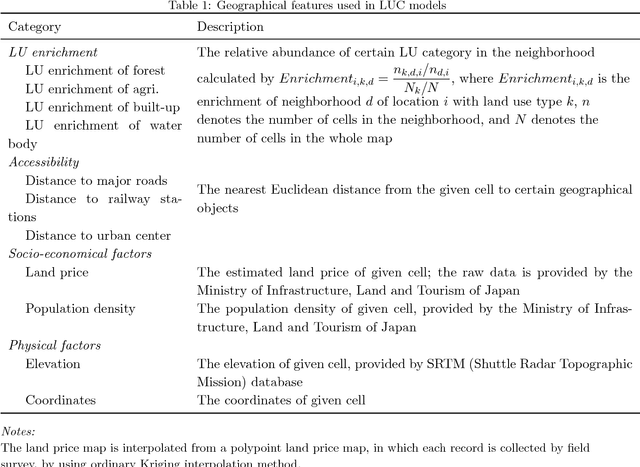
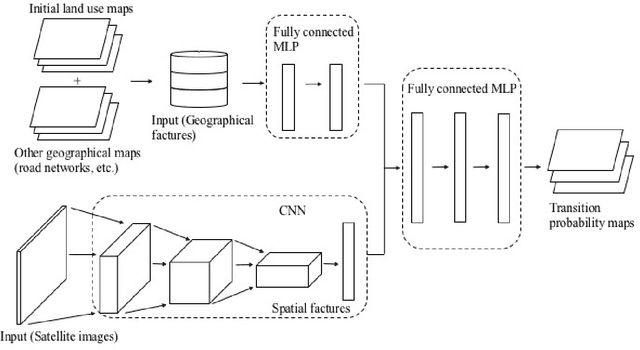
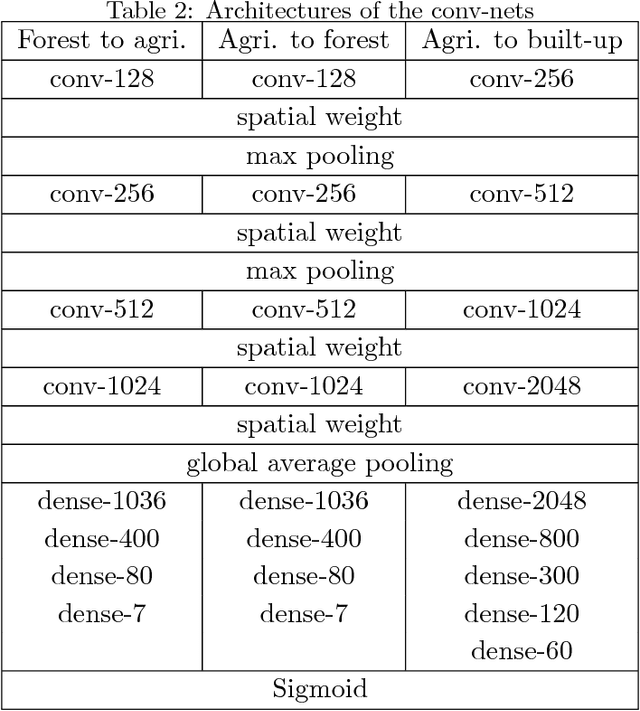
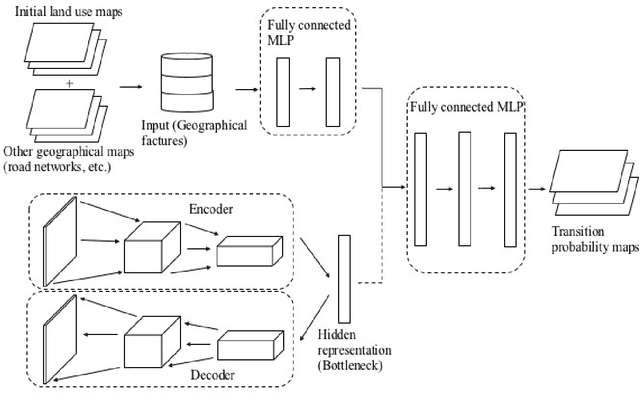
The neighborhood effect is a key driving factor for the land-use change (LUC) process. This study applies convolutional neural networks (CNN) to capture neighborhood characteristics from satellite images and to enhance the performance of LUC modeling. We develop a hybrid CNN model (conv-net) to predict the LU transition probability by combining satellite images and geographical features. A spatial weight layer is designed to incorporate the distance-decay characteristics of neighborhood effect into conv-net. As an alternative model, we also develop a hybrid convolutional denoising autoencoder and multi-layer perceptron model (CDAE-net), which specifically learns latent representations from satellite images and denoises the image data. Finally, a DINAMICA-based cellular automata (CA) model simulates the LU pattern. The results show that the convolutional-based models improve the modeling performances compared with a model that accepts only the geographical features. Overall, conv-net outperforms CDAE-net in terms of LUC predictive performance. Nonetheless, CDAE-net performs better when the data are noisy.