 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Image Compression
Dec 12, 2025
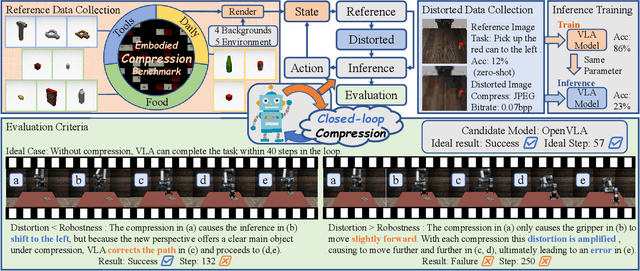
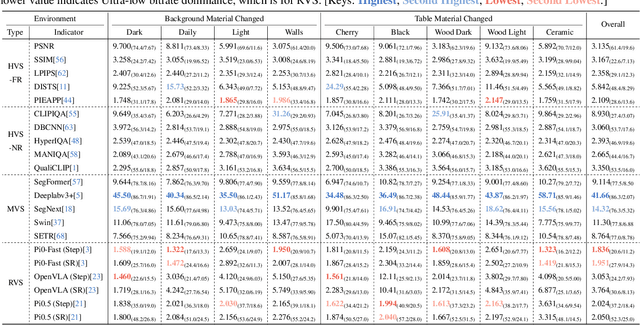
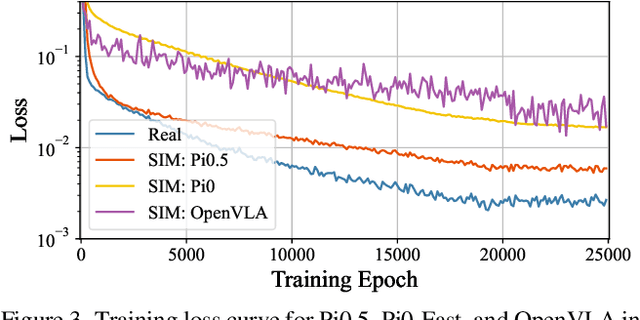
Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
Data Assessment for Embodied Intelligence
Nov 12, 2025In embodied intelligence, datasets play a pivotal role, serving as both a knowledge repository and a conduit for information transfer. The two most critical attributes of a dataset are the amount of information it provides and how easily this information can be learned by models. However, the multimodal nature of embodied data makes evaluating these properties particularly challenging. Prior work has largely focused on diversity, typically counting tasks and scenes or evaluating isolated modalities, which fails to provide a comprehensive picture of dataset diversity. On the other hand, the learnability of datasets has received little attention and is usually assessed post-hoc through model training, an expensive, time-consuming process that also lacks interpretability, offering little guidance on how to improve a dataset. In this work, we address both challenges by introducing two principled, data-driven tools. First, we construct a unified multimodal representation for each data sample and, based on it, propose diversity entropy, a continuous measure that characterizes the amount of information contained in a dataset. Second, we introduce the first interpretable, data-driven algorithm to efficiently quantify dataset learnability without training, enabling researchers to assess a dataset's learnability immediately upon its release. We validate our algorithm on both simulated and real-world embodied datasets, demonstrating that it yields faithful, actionable insights that enable researchers to jointly improve diversity and learnability. We hope this work provides a foundation for designing higher-quality datasets that advance the development of embodied intelligence.
Perceptual Quality Assessment for Embodied AI
May 22, 2025
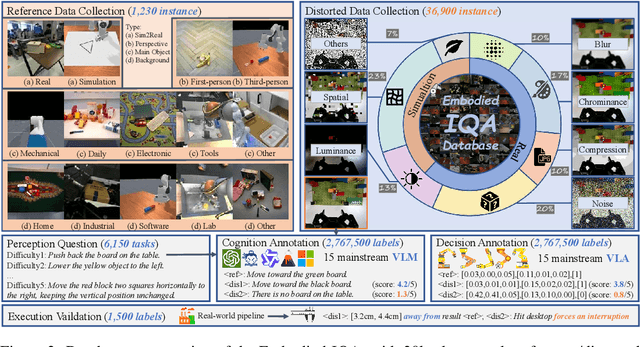


Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA
Embodied Image Quality Assessment for Robotic Intelligence
Dec 25, 2024Image quality assessment (IQA) of user-generated content (UGC) is a critical technique for human quality of experience (QoE). However, for robot-generated content (RGC), will its image quality be consistent with the Moravec paradox and counter to human common sense? Human subjective scoring is more based on the attractiveness of the image. Embodied agent are required to interact and perceive in the environment, and finally perform specific tasks. Visual images as inputs directly influence downstream tasks. In this paper, we first propose an embodied image quality assessment (EIQA) frameworks. We establish assessment metrics for input images based on the downstream tasks of robot. In addition, we construct an Embodied Preference Database (EPD) containing 5,000 reference and distorted image annotations. The performance of mainstream IQA algorithms on EPD dataset is finally verified. The experiments demonstrate that quality assessment of embodied images is different from that of humans. We sincerely hope that the EPD can contribute to the development of embodied AI by focusing on image quality assessment. The benchmark is available at https://github.com/Jianbo-maker/EPD_benchmark.
R-Bench: Are your Large Multimodal Model Robust to Real-world Corruptions?
Oct 07, 2024

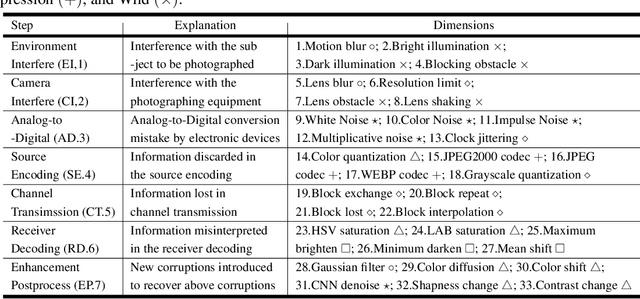

The outstanding performance of Large Multimodal Models (LMMs) has made them widely applied in vision-related tasks. However, various corruptions in the real world mean that images will not be as ideal as in simulations, presenting significant challenges for the practical application of LMMs. To address this issue, we introduce R-Bench, a benchmark focused on the **Real-world Robustness of LMMs**. Specifically, we: (a) model the complete link from user capture to LMMs reception, comprising 33 corruption dimensions, including 7 steps according to the corruption sequence, and 7 groups based on low-level attributes; (b) collect reference/distorted image dataset before/after corruption, including 2,970 question-answer pairs with human labeling; (c) propose comprehensive evaluation for absolute/relative robustness and benchmark 20 mainstream LMMs. Results show that while LMMs can correctly handle the original reference images, their performance is not stable when faced with distorted images, and there is a significant gap in robustness compared to the human visual system. We hope that R-Bench will inspire improving the robustness of LMMs, **extending them from experimental simulations to the real-world application**. Check https://q-future.github.io/R-Bench for details.