 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuotient Space-Based Keyword Retrieval in Sponsored Search
May 26, 2021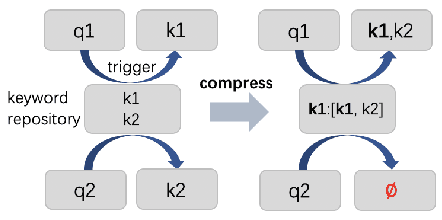
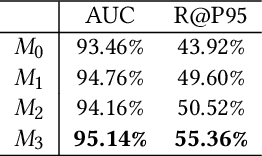
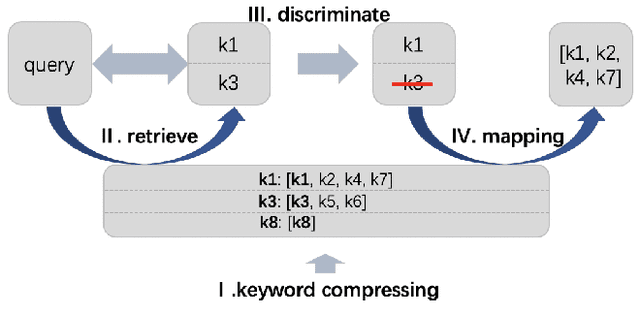
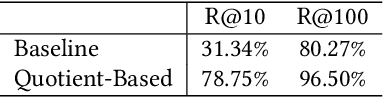
Synonymous keyword retrieval has become an important problem for sponsored search ever since major search engines relax the exact match product's matching requirement to a synonymous level. Since the synonymous relations between queries and keywords are quite scarce, the traditional information retrieval framework is inefficient in this scenario. In this paper, we propose a novel quotient space-based retrieval framework to address this problem. Considering the synonymy among keywords as a mathematical equivalence relation, we can compress the synonymous keywords into one representative, and the corresponding quotient space would greatly reduce the size of the keyword repository. Then an embedding-based retrieval is directly conducted between queries and the keyword representatives. To mitigate the semantic gap of the quotient space-based retrieval, a single semantic siamese model is utilized to detect both the keyword--keyword and query-keyword synonymous relations. The experiments show that with our quotient space-based retrieval method, the synonymous keyword retrieving performance can be greatly improved in terms of memory cost and recall efficiency. This method has been successfully implemented in Baidu's online sponsored search system and has yielded a significant improvement in revenue.
A Concept Knowledge-Driven Keywords Retrieval Framework for Sponsored Search
Feb 21, 2021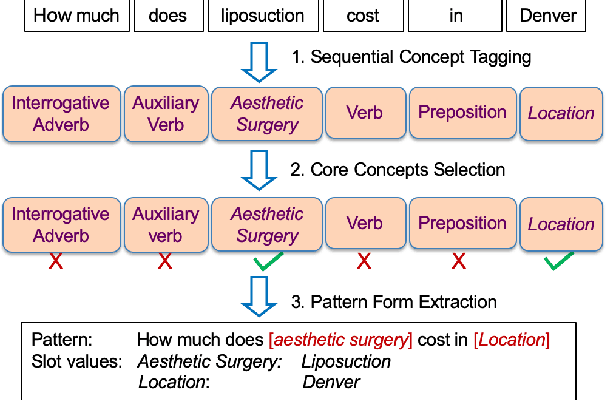

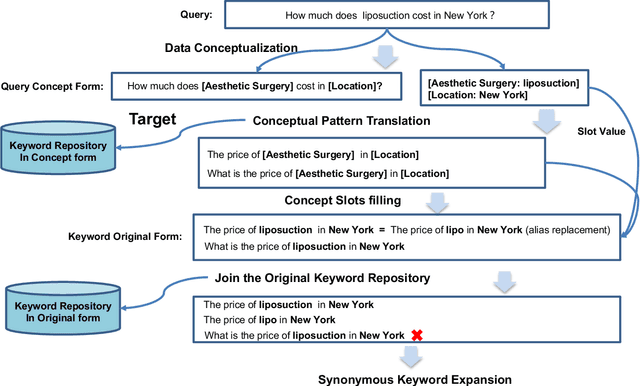
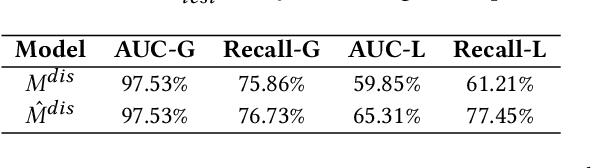
In sponsored search, retrieving synonymous keywords for exact match type is important for accurately targeted advertising. Data-driven deep learning-based method has been proposed to tackle this problem. An apparent disadvantage of this method is its poor generalization performance on entity-level long-tail instances, even though they might share similar concept-level patterns with frequent instances. With the help of a large knowledge base, we find that most commercial synonymous query-keyword pairs can be abstracted into meaningful conceptual patterns through concept tagging. Based on this fact, we propose a novel knowledge-driven conceptual retrieval framework to mitigate this problem, which consists of three parts: data conceptualization, matching via conceptual patterns and concept-augmented discrimination. Both offline and online experiments show that our method is very effective. This framework has been successfully applied to Baidu's sponsored search system, which yields a significant improvement in revenue.
Optimizing AD Pruning of Sponsored Search with Reinforcement Learning
Aug 05, 2020

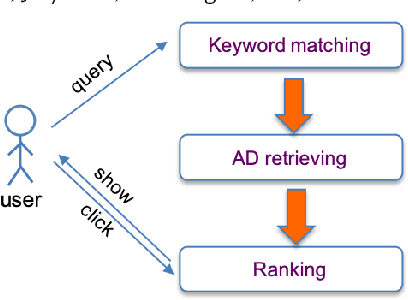
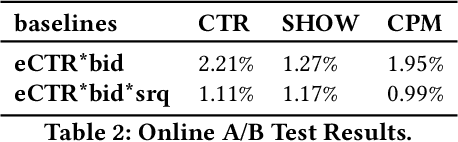
Industrial sponsored search system (SSS) can be logically divided into three modules: keywords matching, ad retrieving, and ranking. During ad retrieving, the ad candidates grow exponentially. A query with high commercial value might retrieve a great deal of ad candidates such that the ranking module could not afford. Due to limited latency and computing resources, the candidates have to be pruned earlier. Suppose we set a pruning line to cut SSS into two parts: upstream and downstream. The problem we are going to address is: how to pick out the best $K$ items from $N$ candidates provided by the upstream to maximize the total system's revenue. Since the industrial downstream is very complicated and updated quickly, a crucial restriction in this problem is that the selection scheme should get adapted to the downstream. In this paper, we propose a novel model-free reinforcement learning approach to fixing this problem. Our approach considers downstream as a black-box environment, and the agent sequentially selects items and finally feeds into the downstream, where revenue would be estimated and used as a reward to improve the selection policy. To the best of our knowledge, this is first time to consider the system optimization from a downstream adaption view. It is also the first time to use reinforcement learning techniques to tackle this problem. The idea has been successfully realized in Baidu's sponsored search system, and online long time A/B test shows remarkable improvements on revenue.