 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation
May 11, 2026Large Language Models (LLMs) have demonstrated powerful reasoning capabilities through Chain-of-Thought (CoT) in various tasks, yet the inefficiency of token-by-token generation hinders real-world deployment in latency-sensitive recommender systems. Latent reasoning has emerged as an effective paradigm in LLMs, performing multi-step inference in a continuous hidden-state space to achieve stronger reasoning at lower cost. However, this paradigm remains underexplored in mainstream generative recommendation. Adapting it reveals three unique challenges: (1) the gap between prior-less Semantic ID (SID) symbols and continuous latent reasoning - SIDs lack pre-trained semantics, hindering joint optimization; (2) representation drift due to a lack of reasoning chain supervision; and (3) the suboptimality of applying a globally fixed reasoning depth. To address these, we propose LASAR (Latent Adaptive Semantic Aligned Reasoning), an SFT-then-RL framework. First, we bridge this gap via two-stage training: Stage 1 grounds SID semantics before Stage 2 introduces latent reasoning, ensuring efficient convergence. Second, we mitigate representation drift through explicit CoT semantic alignment. Step-wise bidirectional KL divergence constrains the latent reasoning trajectory using hidden-state anchors extracted from CoT text, while a Policy Head predicts per-sample reasoning depth. Third, during the GRPO-based RL phase, terminal-only KL alignment accommodates variable-length reasoning, and REINFORCE optimizes the Policy Head to dynamically allocate steps. This nearly halves the average latent step count while simultaneously improving recommendation quality. Experiments on three real-world datasets demonstrate that LASAR outperforms all baselines. It adds marginal inference latency and is roughly 20 times faster than generating explicit CoT text.
Which2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Mar 21, 2025

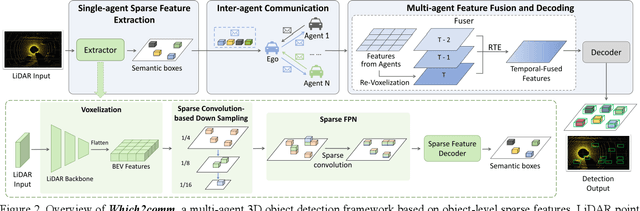

Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.
CCDepth: A Lightweight Self-supervised Depth Estimation Network with Enhanced Interpretability
Sep 30, 2024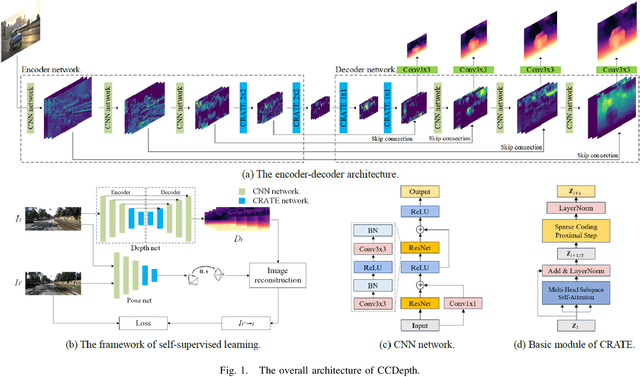

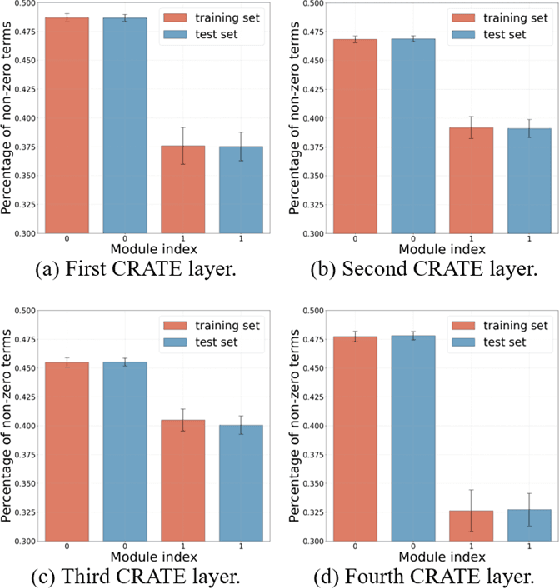

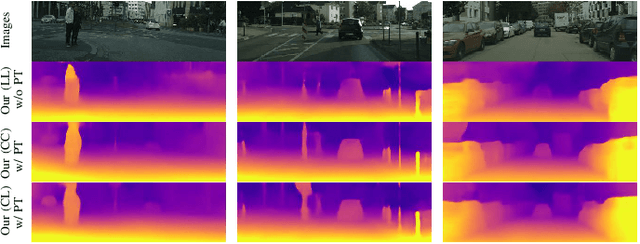
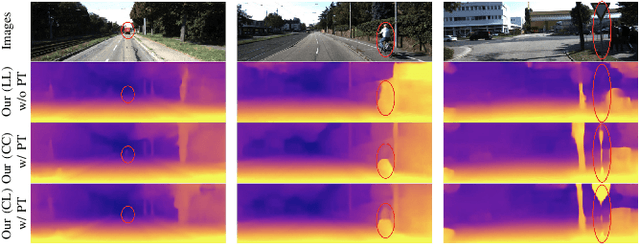
Self-supervised depth estimation, which solely requires monocular image sequence as input, has become increasingly popular and promising in recent years. Current research primarily focuses on enhancing the prediction accuracy of the models. However, the excessive number of parameters impedes the universal deployment of the model on edge devices. Moreover, the emerging neural networks, being black-box models, are difficult to analyze, leading to challenges in understanding the rationales for performance improvements. To mitigate these issues, this study proposes a novel hybrid self-supervised depth estimation network, CCDepth, comprising convolutional neural networks (CNNs) and the white-box CRATE (Coding RAte reduction TransformEr) network. This novel network uses CNNs and the CRATE modules to extract local and global information in images, respectively, thereby boosting learning efficiency and reducing model size. Furthermore, incorporating the CRATE modules into the network enables a mathematically interpretable process in capturing global features. Extensive experiments on the KITTI dataset indicate that the proposed CCDepth network can achieve performance comparable with those state-of-the-art methods, while the model size has been significantly reduced. In addition, a series of quantitative and qualitative analyses on the inner features in the CCDepth network further confirm the effectiveness of the proposed method.
Multi-V2X: A Large Scale Multi-modal Multi-penetration-rate Dataset for Cooperative Perception
Sep 08, 2024
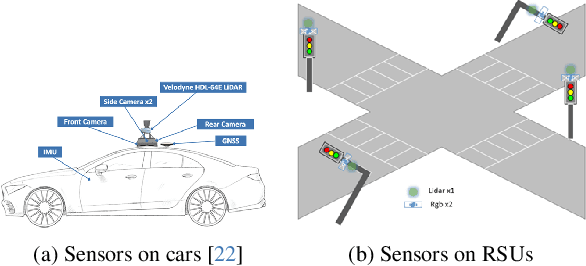
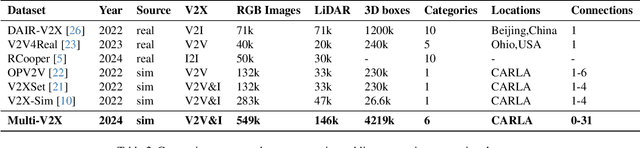
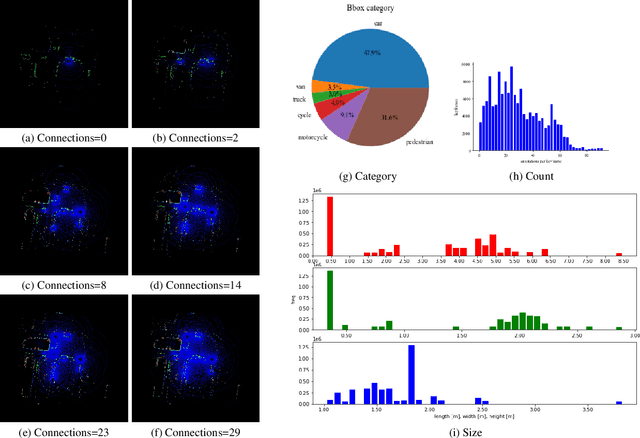
Cooperative perception through vehicle-to-everything (V2X) has garnered significant attention in recent years due to its potential to overcome occlusions and enhance long-distance perception. Great achievements have been made in both datasets and algorithms. However, existing real-world datasets are limited by the presence of few communicable agents, while synthetic datasets typically cover only vehicles. More importantly, the penetration rate of connected and autonomous vehicles (CAVs) , a critical factor for the deployment of cooperative perception technologies, has not been adequately addressed. To tackle these issues, we introduce Multi-V2X, a large-scale, multi-modal, multi-penetration-rate dataset for V2X perception. By co-simulating SUMO and CARLA, we equip a substantial number of cars and roadside units (RSUs) in simulated towns with sensor suites, and collect comprehensive sensing data. Datasets with specified CAV penetration rates can be obtained by masking some equipped cars as normal vehicles. In total, our Multi-V2X dataset comprises 549k RGB frames, 146k LiDAR frames, and 4,219k annotated 3D bounding boxes across six categories. The highest possible CAV penetration rate reaches 86.21%, with up to 31 agents in communication range, posing new challenges in selecting agents to collaborate with. We provide comprehensive benchmarks for cooperative 3D object detection tasks. Our data and code are available at https://github.com/RadetzkyLi/Multi-V2X .
Unify Change Point Detection and Segment Classification in a Regression Task for Transportation Mode Identification
Dec 08, 2023



Identifying travelers' transportation modes is important in transportation science and location-based services. It's appealing for researchers to leverage GPS trajectory data to infer transportation modes with the popularity of GPS-enabled devices, e.g., smart phones. Existing studies frame this problem as classification task. The dominant two-stage studies divide the trip into single-one mode segments first and then categorize these segments. The over segmentation strategy and inevitable error propagation bring difficulties to classification stage and make optimizing the whole system hard. The recent one-stage works throw out trajectory segmentation entirely to avoid these by directly conducting point-wise classification for the trip, whereas leaving predictions dis-continuous. To solve above-mentioned problems, inspired by YOLO and SSD in object detection, we propose to reframe change point detection and segment classification as a unified regression task instead of the existing classification task. We directly regress coordinates of change points and classify associated segments. In this way, our method divides the trip into segments under a supervised manner and leverage more contextual information, obtaining predictions with high accuracy and continuity. Two frameworks, TrajYOLO and TrajSSD, are proposed to solve the regression task and various feature extraction backbones are exploited. Exhaustive experiments on GeoLife dataset show that the proposed method has competitive overall identification accuracy of 0.853 when distinguishing five modes: walk, bike, bus, car, train. As for change point detection, our method increases precision at the cost of drop in recall. All codes are available at https://github.com/RadetzkyLi/TrajYOLO-SSD.
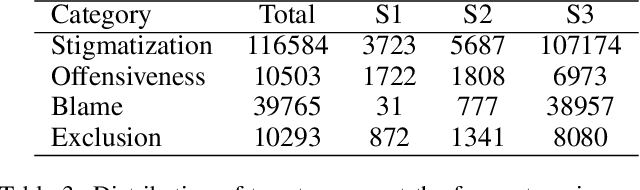
Multi-dimensional Racism Classification during COVID-19: Stigmatization, Offensiveness, Blame, and Exclusion
Aug 29, 2022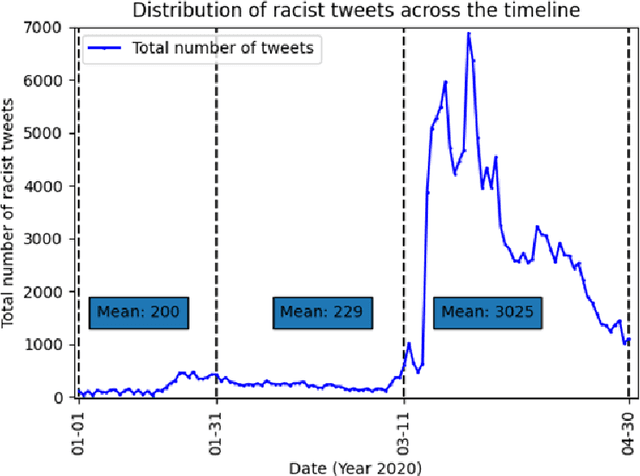
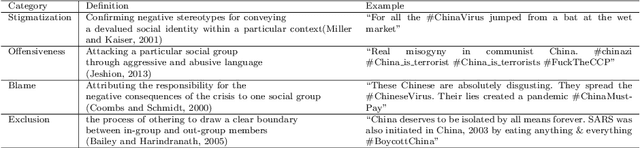
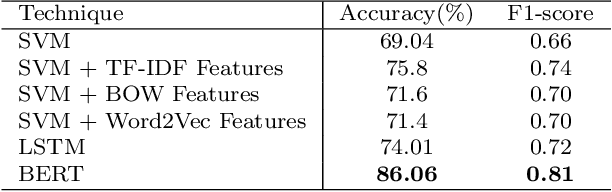
Transcending the binary categorization of racist texts, our study takes cues from social science theories to develop a multi-dimensional model for racism detection, namely stigmatization, offensiveness, blame, and exclusion. With the aid of BERT and topic modeling, this categorical detection enables insights into the underlying subtlety of racist discussion on digital platforms during COVID-19. Our study contributes to enriching the scholarly discussion on deviant racist behaviours on social media. First, a stage-wise analysis is applied to capture the dynamics of the topic changes across the early stages of COVID-19 which transformed from a domestic epidemic to an international public health emergency and later to a global pandemic. Furthermore, mapping this trend enables a more accurate prediction of public opinion evolvement concerning racism in the offline world, and meanwhile, the enactment of specified intervention strategies to combat the upsurge of racism during the global public health crisis like COVID-19. In addition, this interdisciplinary research also points out a direction for future studies on social network analysis and mining. Integration of social science perspectives into the development of computational methods provides insights into more accurate data detection and analytics.
DMRVisNet: Deep Multi-head Regression Network for Pixel-wise Visibility Estimation Under Foggy Weather
Dec 08, 2021
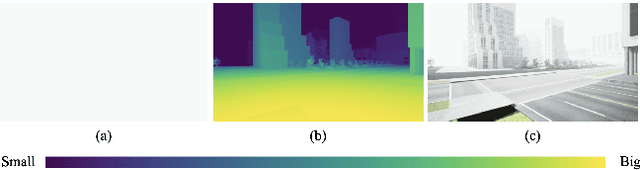
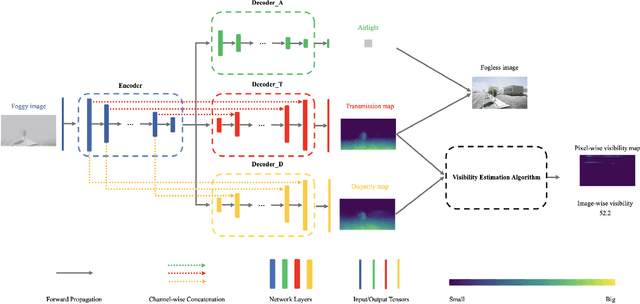
Scene perception is essential for driving decision-making and traffic safety. However, fog, as a kind of common weather, frequently appears in the real world, especially in the mountain areas, making it difficult to accurately observe the surrounding environments. Therefore, precisely estimating the visibility under foggy weather can significantly benefit traffic management and safety. To address this, most current methods use professional instruments outfitted at fixed locations on the roads to perform the visibility measurement; these methods are expensive and less flexible. In this paper, we propose an innovative end-to-end convolutional neural network framework to estimate the visibility leveraging Koschmieder's law exclusively using the image data. The proposed method estimates the visibility by integrating the physical model into the proposed framework, instead of directly predicting the visibility value via the convolutional neural work. Moreover, we estimate the visibility as a pixel-wise visibility map against those of previous visibility measurement methods which solely predict a single value for an entire image. Thus, the estimated result of our method is more informative, particularly in uneven fog scenarios, which can benefit to developing a more precise early warning system for foggy weather, thereby better protecting the intelligent transportation infrastructure systems and promoting its development. To validate the proposed framework, a virtual dataset, FACI, containing 3,000 foggy images in different concentrations, is collected using the AirSim platform. Detailed experiments show that the proposed method achieves performance competitive to those of state-of-the-art methods.
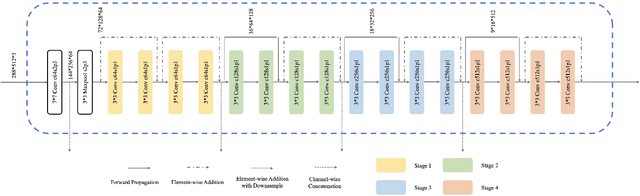
Beyond a binary of racist tweets: A four-dimensional categorical detection and analysis of racist and xenophobic opinions on Twitter in early Covid-19
Jul 18, 2021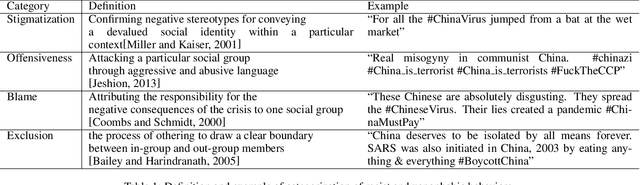
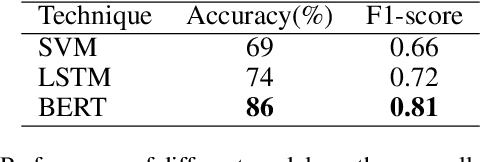
Transcending the binary categorization of racist and xenophobic texts, this research takes cues from social science theories to develop a four dimensional category for racism and xenophobia detection, namely stigmatization, offensiveness, blame, and exclusion. With the aid of deep learning techniques, this categorical detection enables insights into the nuances of emergent topics reflected in racist and xenophobic expression on Twitter. Moreover, a stage wise analysis is applied to capture the dynamic changes of the topics across the stages of early development of Covid-19 from a domestic epidemic to an international public health emergency, and later to a global pandemic. The main contributions of this research include, first the methodological advancement. By bridging the state-of-the-art computational methods with social science perspective, this research provides a meaningful approach for future research to gain insight into the underlying subtlety of racist and xenophobic discussion on digital platforms. Second, by enabling a more accurate comprehension and even prediction of public opinions and actions, this research paves the way for the enactment of effective intervention policies to combat racist crimes and social exclusion under Covid-19.
Self-supervised Depth Estimation Leveraging Global Perception and Geometric Smoothness Using On-board Videos
Jun 07, 2021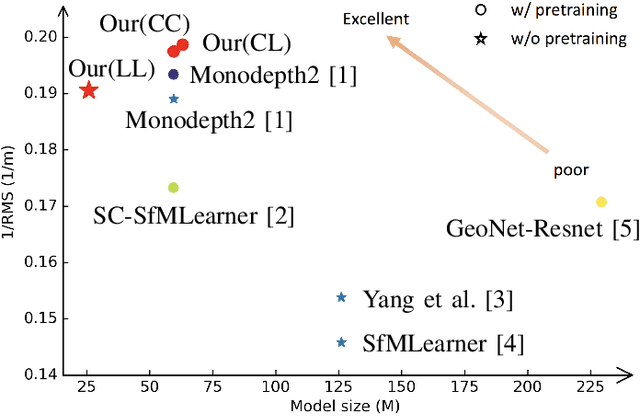
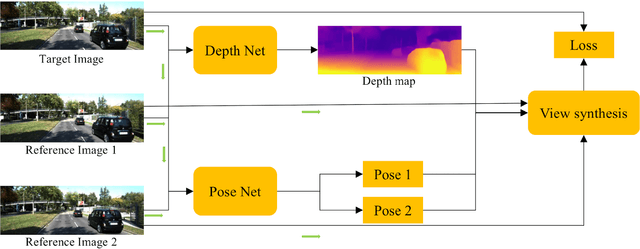
Self-supervised depth estimation has drawn much attention in recent years as it does not require labeled data but image sequences. Moreover, it can be conveniently used in various applications, such as autonomous driving, robotics, realistic navigation, and smart cities. However, extracting global contextual information from images and predicting a geometrically natural depth map remain challenging. In this paper, we present DLNet for pixel-wise depth estimation, which simultaneously extracts global and local features with the aid of our depth Linformer block. This block consists of the Linformer and innovative soft split multi-layer perceptron blocks. Moreover, a three-dimensional geometry smoothness loss is proposed to predict a geometrically natural depth map by imposing the second-order smoothness constraint on the predicted three-dimensional point clouds, thereby realizing improved performance as a byproduct. Finally, we explore the multi-scale prediction strategy and propose the maximum margin dual-scale prediction strategy for further performance improvement. In experiments on the KITTI and Make3D benchmarks, the proposed DLNet achieves performance competitive to those of the state-of-the-art methods, reducing time and space complexities by more than $62\%$ and $56\%$, respectively. Extensive testing on various real-world situations further demonstrates the strong practicality and generalization capability of the proposed model.
Optimizing AD Pruning of Sponsored Search with Reinforcement Learning
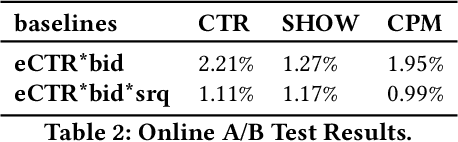
Aug 05, 2020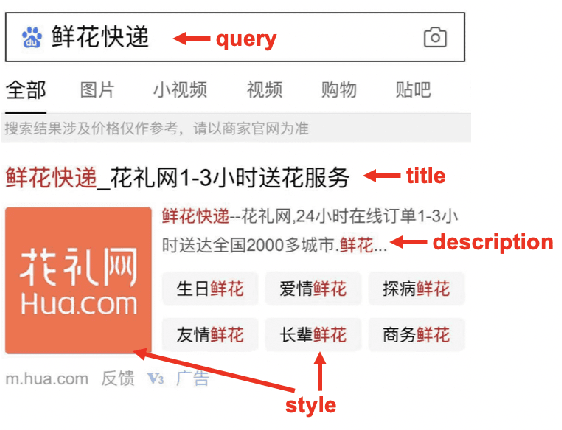

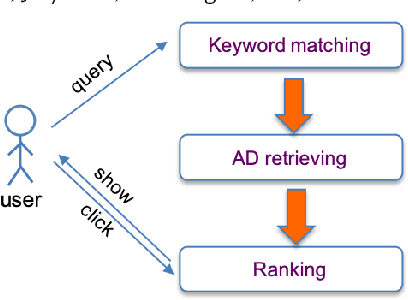
Industrial sponsored search system (SSS) can be logically divided into three modules: keywords matching, ad retrieving, and ranking. During ad retrieving, the ad candidates grow exponentially. A query with high commercial value might retrieve a great deal of ad candidates such that the ranking module could not afford. Due to limited latency and computing resources, the candidates have to be pruned earlier. Suppose we set a pruning line to cut SSS into two parts: upstream and downstream. The problem we are going to address is: how to pick out the best $K$ items from $N$ candidates provided by the upstream to maximize the total system's revenue. Since the industrial downstream is very complicated and updated quickly, a crucial restriction in this problem is that the selection scheme should get adapted to the downstream. In this paper, we propose a novel model-free reinforcement learning approach to fixing this problem. Our approach considers downstream as a black-box environment, and the agent sequentially selects items and finally feeds into the downstream, where revenue would be estimated and used as a reward to improve the selection policy. To the best of our knowledge, this is first time to consider the system optimization from a downstream adaption view. It is also the first time to use reinforcement learning techniques to tackle this problem. The idea has been successfully realized in Baidu's sponsored search system, and online long time A/B test shows remarkable improvements on revenue.