 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Mar 21, 2025

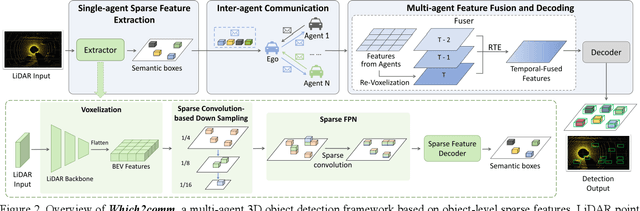

Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.
DMRVisNet: Deep Multi-head Regression Network for Pixel-wise Visibility Estimation Under Foggy Weather
Dec 08, 2021
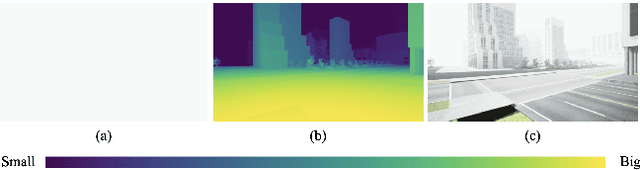
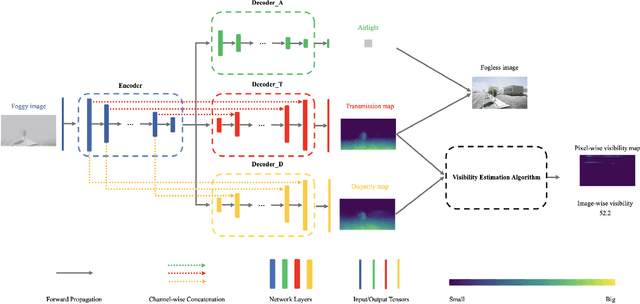
Scene perception is essential for driving decision-making and traffic safety. However, fog, as a kind of common weather, frequently appears in the real world, especially in the mountain areas, making it difficult to accurately observe the surrounding environments. Therefore, precisely estimating the visibility under foggy weather can significantly benefit traffic management and safety. To address this, most current methods use professional instruments outfitted at fixed locations on the roads to perform the visibility measurement; these methods are expensive and less flexible. In this paper, we propose an innovative end-to-end convolutional neural network framework to estimate the visibility leveraging Koschmieder's law exclusively using the image data. The proposed method estimates the visibility by integrating the physical model into the proposed framework, instead of directly predicting the visibility value via the convolutional neural work. Moreover, we estimate the visibility as a pixel-wise visibility map against those of previous visibility measurement methods which solely predict a single value for an entire image. Thus, the estimated result of our method is more informative, particularly in uneven fog scenarios, which can benefit to developing a more precise early warning system for foggy weather, thereby better protecting the intelligent transportation infrastructure systems and promoting its development. To validate the proposed framework, a virtual dataset, FACI, containing 3,000 foggy images in different concentrations, is collected using the AirSim platform. Detailed experiments show that the proposed method achieves performance competitive to those of state-of-the-art methods.