 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Mar 21, 2025

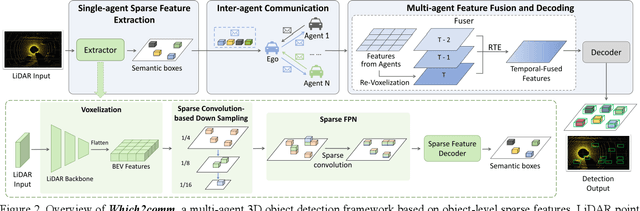

Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.
CCDepth: A Lightweight Self-supervised Depth Estimation Network with Enhanced Interpretability
Sep 30, 2024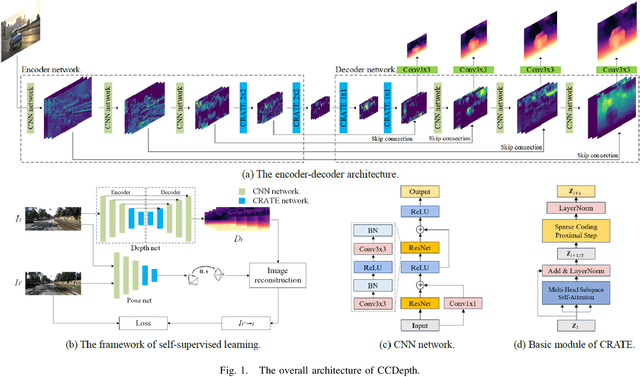

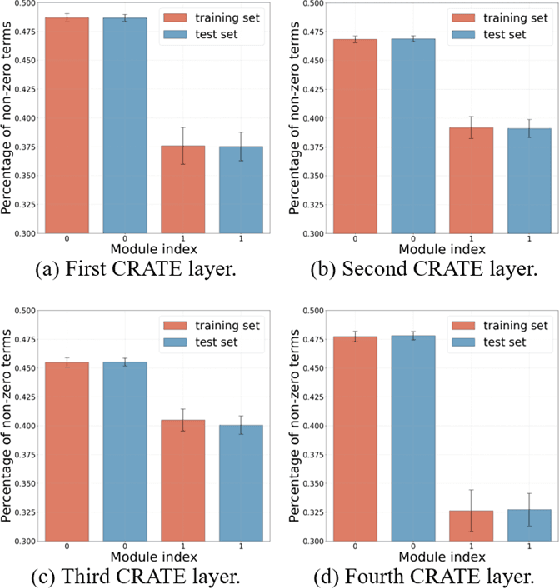

Self-supervised depth estimation, which solely requires monocular image sequence as input, has become increasingly popular and promising in recent years. Current research primarily focuses on enhancing the prediction accuracy of the models. However, the excessive number of parameters impedes the universal deployment of the model on edge devices. Moreover, the emerging neural networks, being black-box models, are difficult to analyze, leading to challenges in understanding the rationales for performance improvements. To mitigate these issues, this study proposes a novel hybrid self-supervised depth estimation network, CCDepth, comprising convolutional neural networks (CNNs) and the white-box CRATE (Coding RAte reduction TransformEr) network. This novel network uses CNNs and the CRATE modules to extract local and global information in images, respectively, thereby boosting learning efficiency and reducing model size. Furthermore, incorporating the CRATE modules into the network enables a mathematically interpretable process in capturing global features. Extensive experiments on the KITTI dataset indicate that the proposed CCDepth network can achieve performance comparable with those state-of-the-art methods, while the model size has been significantly reduced. In addition, a series of quantitative and qualitative analyses on the inner features in the CCDepth network further confirm the effectiveness of the proposed method.
Self-supervised Multi-task Learning Framework for Safety and Health-Oriented Connected Driving Environment Perception using Onboard Camera
Jun 20, 2023Cutting-edge connected vehicle (CV) technologies have drawn much attention in recent years. The real-time traffic data captured by a CV can be shared with other CVs and data centers so as to open new possibilities for solving diverse transportation problems. However, imagery captured by onboard cameras in a connected environment, are not sufficiently investigated, especially for safety and health-oriented visual perception. In this paper, a bidirectional process of image synthesis and decomposition (BPISD) approach is proposed, and thus a novel self-supervised multi-task learning framework, to simultaneously estimate depth map, atmospheric visibility, airlight, and PM2.5 mass concentration, in which depth map and visibility are considered highly associated with traffic safety, while airlight and PM2.5 mass concentration are directly correlated with human health. Both the training and testing phases of the proposed system solely require a single image as input. Due to the innovative training pipeline, the depth estimation network can manage various levels of visibility conditions and overcome inherent problems in current image-synthesis-based depth estimation, thereby generating high-quality depth maps even in low-visibility situations and further benefiting accurate estimations of visibility, airlight, and PM2.5 mass concentration. Extensive experiments on the synthesized data from the KITTI and real-world data collected in Beijing demonstrate that the proposed method can (1) achieve performance competitive in depth estimation as compared with state-of-the-art methods when taking clear images as input; (2) predict vivid depth map for images contaminated by various levels of haze; and (3) accurately estimate visibility, airlight, and PM2.5 mass concentrations. Beneficial applications can be developed based on the presented work to improve traffic safety, air quality, and public health.
Joint Learning of Frequency and Spatial Domains for Dense Predictions
Feb 18, 2022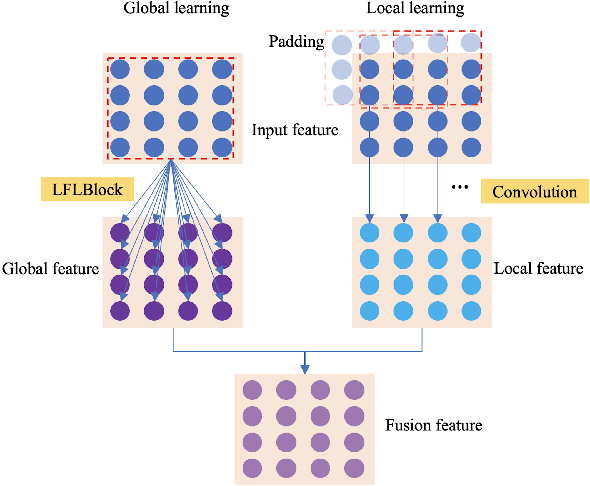
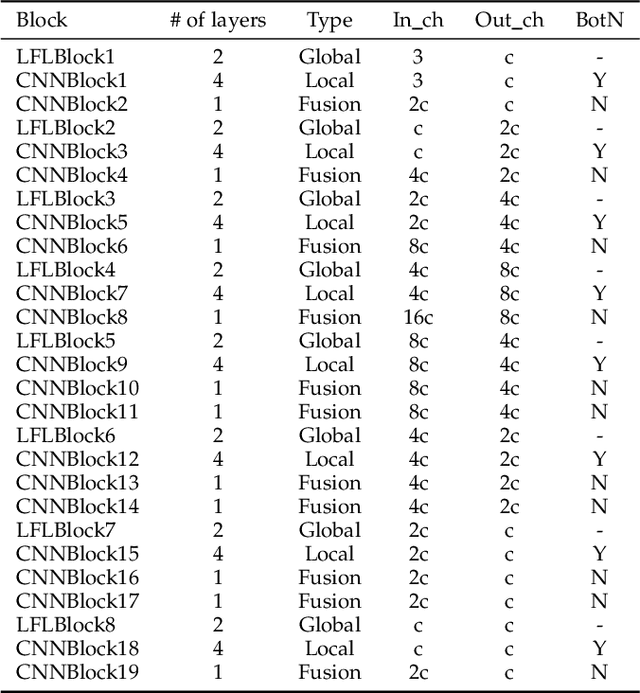
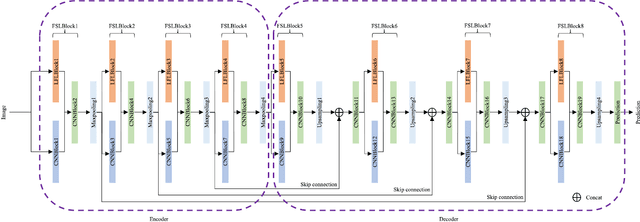
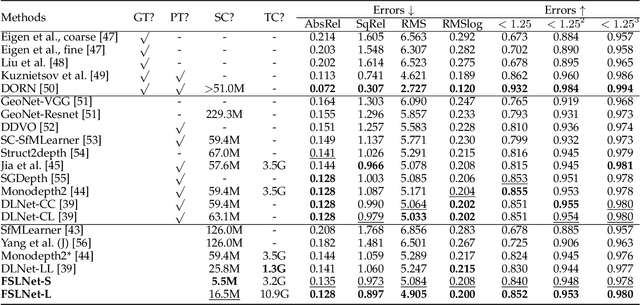
Current artificial neural networks mainly conduct the learning process in the spatial domain but neglect the frequency domain learning. However, the learning course performed in the frequency domain can be more efficient than that in the spatial domain. In this paper, we fully explore frequency domain learning and propose a joint learning paradigm of frequency and spatial domains. This paradigm can take full advantage of the preponderances of frequency learning and spatial learning; specifically, frequency and spatial domain learning can effectively capture global and local information, respectively. Exhaustive experiments on two dense prediction tasks, i.e., self-supervised depth estimation and semantic segmentation, demonstrate that the proposed joint learning paradigm can 1) achieve performance competitive to those of state-of-the-art methods in both depth estimation and semantic segmentation tasks, even without pretraining; and 2) significantly reduce the number of parameters compared to other state-of-the-art methods, which provides more chance to develop real-world applications. We hope that the proposed method can encourage more research in cross-domain learning.
DMRVisNet: Deep Multi-head Regression Network for Pixel-wise Visibility Estimation Under Foggy Weather
Dec 08, 2021
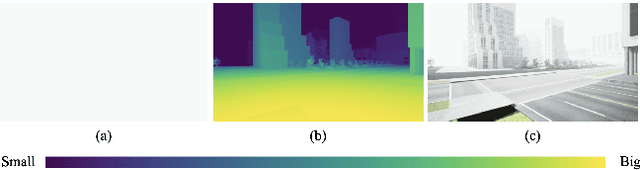
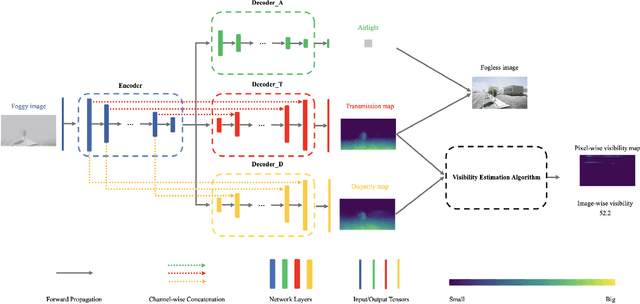
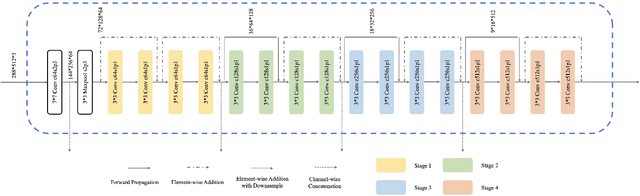
Scene perception is essential for driving decision-making and traffic safety. However, fog, as a kind of common weather, frequently appears in the real world, especially in the mountain areas, making it difficult to accurately observe the surrounding environments. Therefore, precisely estimating the visibility under foggy weather can significantly benefit traffic management and safety. To address this, most current methods use professional instruments outfitted at fixed locations on the roads to perform the visibility measurement; these methods are expensive and less flexible. In this paper, we propose an innovative end-to-end convolutional neural network framework to estimate the visibility leveraging Koschmieder's law exclusively using the image data. The proposed method estimates the visibility by integrating the physical model into the proposed framework, instead of directly predicting the visibility value via the convolutional neural work. Moreover, we estimate the visibility as a pixel-wise visibility map against those of previous visibility measurement methods which solely predict a single value for an entire image. Thus, the estimated result of our method is more informative, particularly in uneven fog scenarios, which can benefit to developing a more precise early warning system for foggy weather, thereby better protecting the intelligent transportation infrastructure systems and promoting its development. To validate the proposed framework, a virtual dataset, FACI, containing 3,000 foggy images in different concentrations, is collected using the AirSim platform. Detailed experiments show that the proposed method achieves performance competitive to those of state-of-the-art methods.
Self-supervised Depth Estimation Leveraging Global Perception and Geometric Smoothness Using On-board Videos
Jun 07, 2021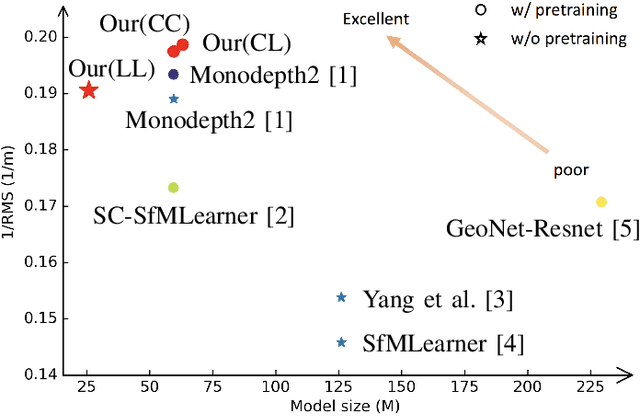
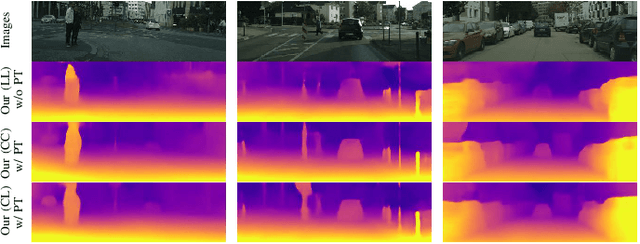
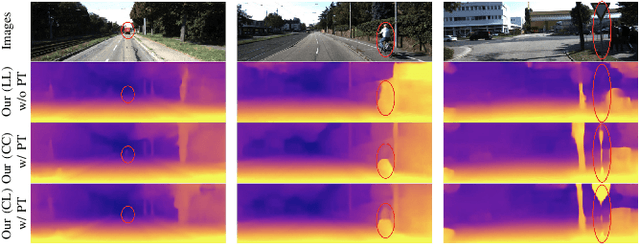
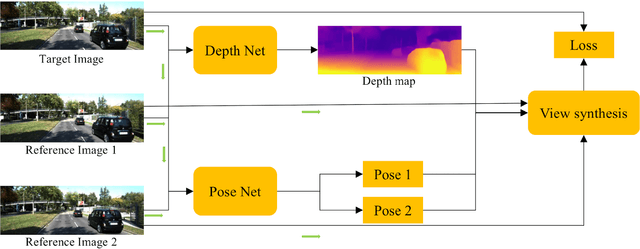
Self-supervised depth estimation has drawn much attention in recent years as it does not require labeled data but image sequences. Moreover, it can be conveniently used in various applications, such as autonomous driving, robotics, realistic navigation, and smart cities. However, extracting global contextual information from images and predicting a geometrically natural depth map remain challenging. In this paper, we present DLNet for pixel-wise depth estimation, which simultaneously extracts global and local features with the aid of our depth Linformer block. This block consists of the Linformer and innovative soft split multi-layer perceptron blocks. Moreover, a three-dimensional geometry smoothness loss is proposed to predict a geometrically natural depth map by imposing the second-order smoothness constraint on the predicted three-dimensional point clouds, thereby realizing improved performance as a byproduct. Finally, we explore the multi-scale prediction strategy and propose the maximum margin dual-scale prediction strategy for further performance improvement. In experiments on the KITTI and Make3D benchmarks, the proposed DLNet achieves performance competitive to those of the state-of-the-art methods, reducing time and space complexities by more than $62\%$ and $56\%$, respectively. Extensive testing on various real-world situations further demonstrates the strong practicality and generalization capability of the proposed model.