 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multimodal vision foundation model for generalizable knee pathology
Jan 26, 2026Musculoskeletal disorders represent a leading cause of global disability, creating an urgent demand for precise interpretation of medical imaging. Current artificial intelligence (AI) approaches in orthopedics predominantly rely on task-specific, supervised learning paradigms. These methods are inherently fragmented, require extensive annotated datasets, and often lack generalizability across different modalities and clinical scenarios. The development of foundation models in this field has been constrained by the scarcity of large-scale, curated, and open-source musculoskeletal datasets. To address these challenges, we introduce OrthoFoundation, a multimodal vision foundation model optimized for musculoskeletal pathology. We constructed a pre-training dataset of 1.2 million unlabeled knee X-ray and MRI images from internal and public databases. Utilizing a Dinov3 backbone, the model was trained via self-supervised contrastive learning to capture robust radiological representations. OrthoFoundation achieves state-of-the-art (SOTA) performance across 14 downstream tasks. It attained superior accuracy in X-ray osteoarthritis diagnosis and ranked first in MRI structural injury detection. The model demonstrated remarkable label efficiency, matching supervised baselines using only 50% of labeled data. Furthermore, despite being pre-trained on knee images, OrthoFoundation exhibited exceptional cross-anatomy generalization to the hip, shoulder, and ankle. OrthoFoundation represents a significant advancement toward general-purpose AI for musculoskeletal imaging. By learning fundamental, joint-agnostic radiological semantics from large-scale multimodal data, it overcomes the limitations of conventional models, which provides a robust framework for reducing annotation burdens and enhancing diagnostic accuracy in clinical practice.
The Illusion of Clinical Reasoning: A Benchmark Reveals the Pervasive Gap in Vision-Language Models for Clinical Competency
Dec 25, 2025Background: The rapid integration of foundation models into clinical practice and public health necessitates a rigorous evaluation of their true clinical reasoning capabilities beyond narrow examination success. Current benchmarks, typically based on medical licensing exams or curated vignettes, fail to capture the integrated, multimodal reasoning essential for real-world patient care. Methods: We developed the Bones and Joints (B&J) Benchmark, a comprehensive evaluation framework comprising 1,245 questions derived from real-world patient cases in orthopedics and sports medicine. This benchmark assesses models across 7 tasks that mirror the clinical reasoning pathway, including knowledge recall, text and image interpretation, diagnosis generation, treatment planning, and rationale provision. We evaluated eleven vision-language models (VLMs) and six large language models (LLMs), comparing their performance against expert-derived ground truth. Results: Our results demonstrate a pronounced performance gap between task types. While state-of-the-art models achieved high accuracy, exceeding 90%, on structured multiple-choice questions, their performance markedly declined on open-ended tasks requiring multimodal integration, with accuracy scarcely reaching 60%. VLMs demonstrated substantial limitations in interpreting medical images and frequently exhibited severe text-driven hallucinations, often ignoring contradictory visual evidence. Notably, models specifically fine-tuned for medical applications showed no consistent advantage over general-purpose counterparts. Conclusions: Current artificial intelligence models are not yet clinically competent for complex, multimodal reasoning. Their safe deployment should currently be limited to supportive, text-based roles. Future advancement in core clinical tasks awaits fundamental breakthroughs in multimodal integration and visual understanding.
Which2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Mar 21, 2025

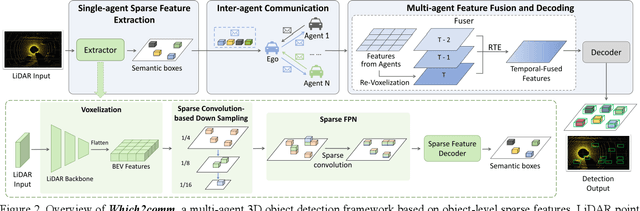

Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.