 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich2comm: An Efficient Collaborative Perception Framework for 3D Object Detection
Paper and Code
Mar 21, 2025

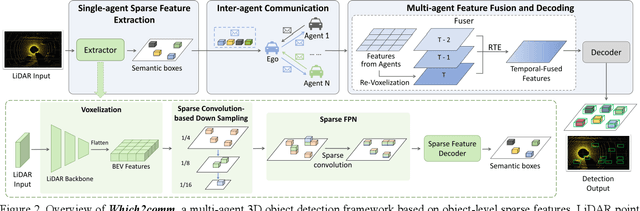

Collaborative perception allows real-time inter-agent information exchange and thus offers invaluable opportunities to enhance the perception capabilities of individual agents. However, limited communication bandwidth in practical scenarios restricts the inter-agent data transmission volume, consequently resulting in performance declines in collaborative perception systems. This implies a trade-off between perception performance and communication cost. To address this issue, we propose Which2comm, a novel multi-agent 3D object detection framework leveraging object-level sparse features. By integrating semantic information of objects into 3D object detection boxes, we introduce semantic detection boxes (SemDBs). Innovatively transmitting these information-rich object-level sparse features among agents not only significantly reduces the demanding communication volume, but also improves 3D object detection performance. Specifically, a fully sparse network is constructed to extract SemDBs from individual agents; a temporal fusion approach with a relative temporal encoding mechanism is utilized to obtain the comprehensive spatiotemporal features. Extensive experiments on the V2XSet and OPV2V datasets demonstrate that Which2comm consistently outperforms other state-of-the-art methods on both perception performance and communication cost, exhibiting better robustness to real-world latency. These results present that for multi-agent collaborative 3D object detection, transmitting only object-level sparse features is sufficient to achieve high-precision and robust performance.