 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Depth Estimation Leveraging Global Perception and Geometric Smoothness Using On-board Videos
Paper and Code
Jun 07, 2021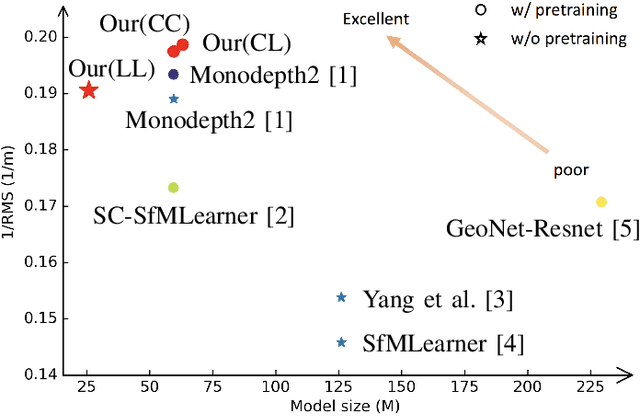
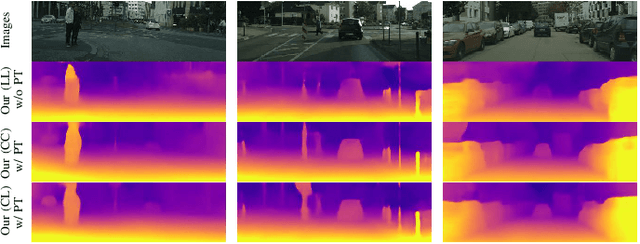
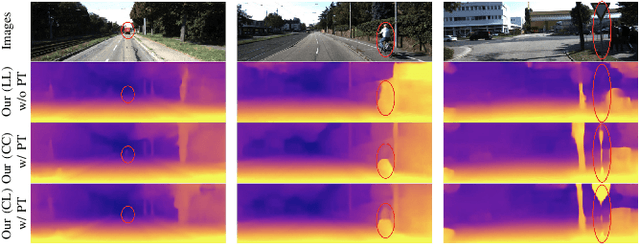
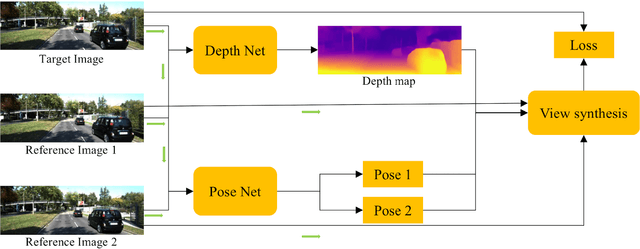
Self-supervised depth estimation has drawn much attention in recent years as it does not require labeled data but image sequences. Moreover, it can be conveniently used in various applications, such as autonomous driving, robotics, realistic navigation, and smart cities. However, extracting global contextual information from images and predicting a geometrically natural depth map remain challenging. In this paper, we present DLNet for pixel-wise depth estimation, which simultaneously extracts global and local features with the aid of our depth Linformer block. This block consists of the Linformer and innovative soft split multi-layer perceptron blocks. Moreover, a three-dimensional geometry smoothness loss is proposed to predict a geometrically natural depth map by imposing the second-order smoothness constraint on the predicted three-dimensional point clouds, thereby realizing improved performance as a byproduct. Finally, we explore the multi-scale prediction strategy and propose the maximum margin dual-scale prediction strategy for further performance improvement. In experiments on the KITTI and Make3D benchmarks, the proposed DLNet achieves performance competitive to those of the state-of-the-art methods, reducing time and space complexities by more than $62\%$ and $56\%$, respectively. Extensive testing on various real-world situations further demonstrates the strong practicality and generalization capability of the proposed model.