 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCDepth: A Lightweight Self-supervised Depth Estimation Network with Enhanced Interpretability
Paper and Code
Sep 30, 2024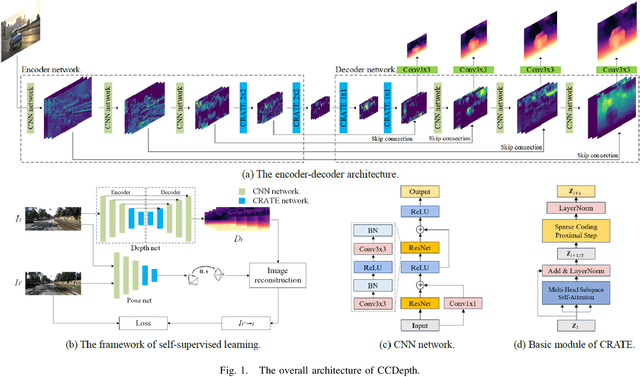

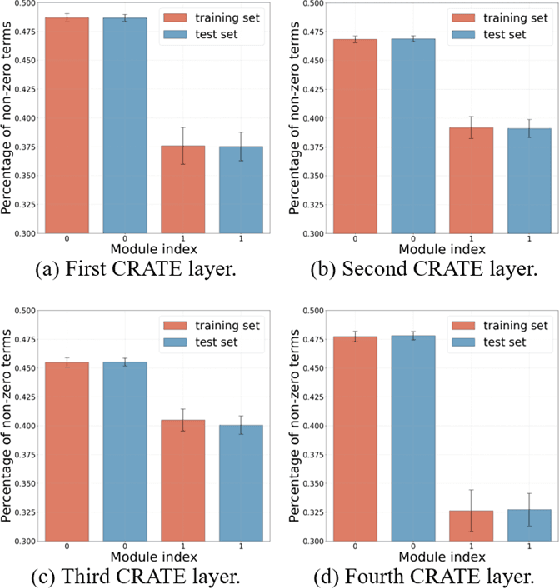

Self-supervised depth estimation, which solely requires monocular image sequence as input, has become increasingly popular and promising in recent years. Current research primarily focuses on enhancing the prediction accuracy of the models. However, the excessive number of parameters impedes the universal deployment of the model on edge devices. Moreover, the emerging neural networks, being black-box models, are difficult to analyze, leading to challenges in understanding the rationales for performance improvements. To mitigate these issues, this study proposes a novel hybrid self-supervised depth estimation network, CCDepth, comprising convolutional neural networks (CNNs) and the white-box CRATE (Coding RAte reduction TransformEr) network. This novel network uses CNNs and the CRATE modules to extract local and global information in images, respectively, thereby boosting learning efficiency and reducing model size. Furthermore, incorporating the CRATE modules into the network enables a mathematically interpretable process in capturing global features. Extensive experiments on the KITTI dataset indicate that the proposed CCDepth network can achieve performance comparable with those state-of-the-art methods, while the model size has been significantly reduced. In addition, a series of quantitative and qualitative analyses on the inner features in the CCDepth network further confirm the effectiveness of the proposed method.