 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCDepth: A Lightweight Self-supervised Depth Estimation Network with Enhanced Interpretability
Sep 30, 2024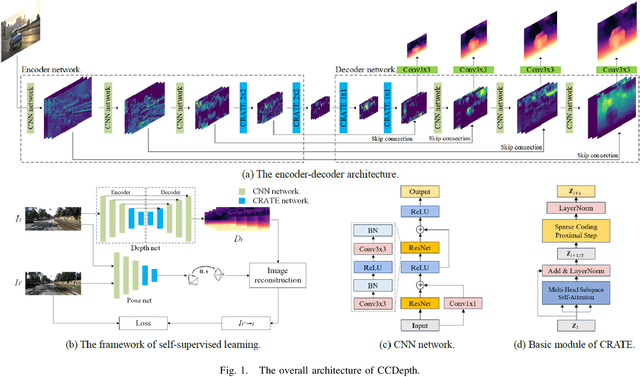

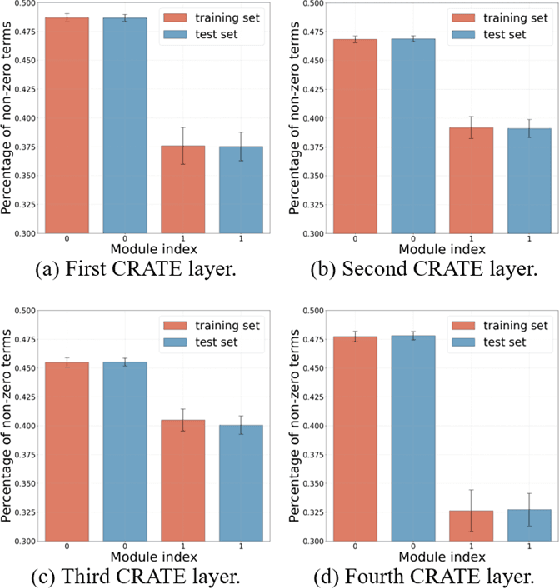

Self-supervised depth estimation, which solely requires monocular image sequence as input, has become increasingly popular and promising in recent years. Current research primarily focuses on enhancing the prediction accuracy of the models. However, the excessive number of parameters impedes the universal deployment of the model on edge devices. Moreover, the emerging neural networks, being black-box models, are difficult to analyze, leading to challenges in understanding the rationales for performance improvements. To mitigate these issues, this study proposes a novel hybrid self-supervised depth estimation network, CCDepth, comprising convolutional neural networks (CNNs) and the white-box CRATE (Coding RAte reduction TransformEr) network. This novel network uses CNNs and the CRATE modules to extract local and global information in images, respectively, thereby boosting learning efficiency and reducing model size. Furthermore, incorporating the CRATE modules into the network enables a mathematically interpretable process in capturing global features. Extensive experiments on the KITTI dataset indicate that the proposed CCDepth network can achieve performance comparable with those state-of-the-art methods, while the model size has been significantly reduced. In addition, a series of quantitative and qualitative analyses on the inner features in the CCDepth network further confirm the effectiveness of the proposed method.
A Novel Neural Network Training Framework with Data Assimilation
Oct 06, 2020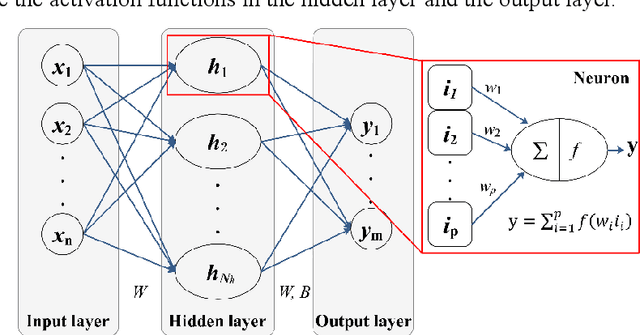
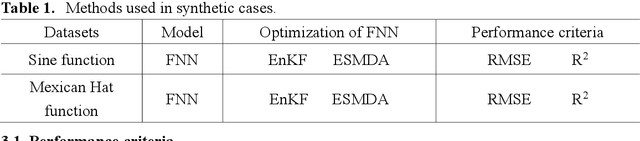
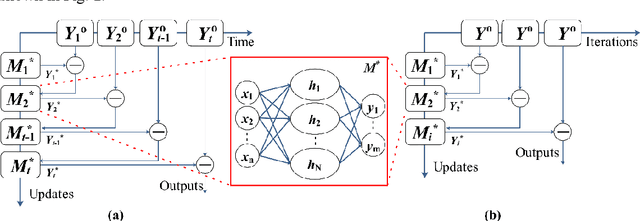
In recent years, the prosperity of deep learning has revolutionized the Artificial Neural Networks. However, the dependence of gradients and the offline training mechanism in the learning algorithms prevents the ANN for further improvement. In this study, a gradient-free training framework based on data assimilation is proposed to avoid the calculation of gradients. In data assimilation algorithms, the error covariance between the forecasts and observations is used to optimize the parameters. Feedforward Neural Networks (FNNs) are trained by gradient decent, data assimilation algorithms (Ensemble Kalman Filter (EnKF) and Ensemble Smoother with Multiple Data Assimilation (ESMDA)), respectively. ESMDA trains FNN with pre-defined iterations by updating the parameters using all the available observations which can be regard as offline learning. EnKF optimize FNN when new observation available by updating parameters which can be regard as online learning. Two synthetic cases with the regression of a Sine Function and a Mexican Hat function are assumed to validate the effectiveness of the proposed framework. The Root Mean Square Error (RMSE) and coefficient of determination (R2) are used as criteria to assess the performance of different methods. The results show that the proposed training framework performed better than the gradient decent method. The proposed framework provides alternatives for online/offline training the existing ANNs (e.g., Convolutional Neural Networks, Recurrent Neural Networks) without the dependence of gradients.