 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Neural Network Training Framework with Data Assimilation
Oct 06, 2020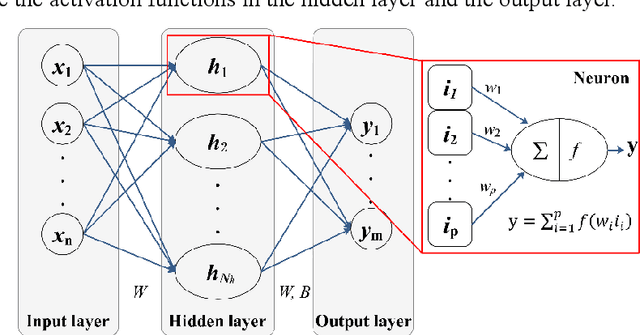
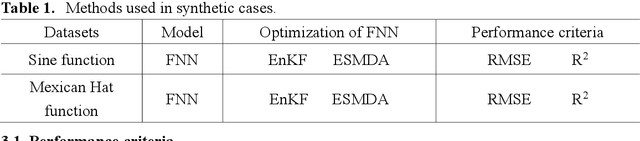
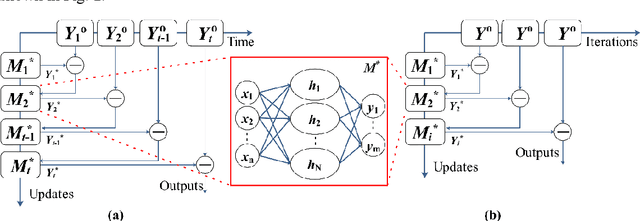
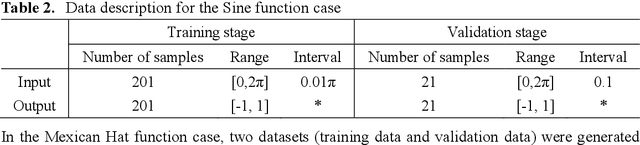
In recent years, the prosperity of deep learning has revolutionized the Artificial Neural Networks. However, the dependence of gradients and the offline training mechanism in the learning algorithms prevents the ANN for further improvement. In this study, a gradient-free training framework based on data assimilation is proposed to avoid the calculation of gradients. In data assimilation algorithms, the error covariance between the forecasts and observations is used to optimize the parameters. Feedforward Neural Networks (FNNs) are trained by gradient decent, data assimilation algorithms (Ensemble Kalman Filter (EnKF) and Ensemble Smoother with Multiple Data Assimilation (ESMDA)), respectively. ESMDA trains FNN with pre-defined iterations by updating the parameters using all the available observations which can be regard as offline learning. EnKF optimize FNN when new observation available by updating parameters which can be regard as online learning. Two synthetic cases with the regression of a Sine Function and a Mexican Hat function are assumed to validate the effectiveness of the proposed framework. The Root Mean Square Error (RMSE) and coefficient of determination (R2) are used as criteria to assess the performance of different methods. The results show that the proposed training framework performed better than the gradient decent method. The proposed framework provides alternatives for online/offline training the existing ANNs (e.g., Convolutional Neural Networks, Recurrent Neural Networks) without the dependence of gradients.