 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSpike: Accelerating Spiking Neural Networks on Neuromorphic Systems via Eliminating Address Redundancy
May 22, 2026Many-core neuromorphic systems accelerate Spiking Neural Networks (SNNs), yet their packet-based spike communication can spend substantial traffic and energy repeatedly transmitting destination addresses. This overhead is amplified by the small payload of spike packets: in representative workloads, duplicate address transmissions account for up to 49% of the total traffic. This paper presents UniSpike, a hardware-software co-design that removes address redundancy by aggregating spikes destined for the same core into compact packets. UniSpike combines destination-centric spike scheduling, lightweight runtime packet assembly hardware, and destination-aware SNN partitioning. Across diverse SNN workloads, UniSpike reduces traffic by 1.93$\times$ on average, delivering 1.77$\times$ speedup and 1.50$\times$ energy efficiency improvement over state-of-the-art designs.
An Asynchronous Multi-core Accelerator for SNN inference
Jul 30, 2024



Spiking Neural Networks (SNNs) are extensively utilized in brain-inspired computing and neuroscience research. To enhance the speed and energy efficiency of SNNs, several many-core accelerators have been developed. However, maintaining the accuracy of SNNs often necessitates frequent explicit synchronization among all cores, which presents a challenge to overall efficiency. In this paper, we propose an asynchronous architecture for Spiking Neural Networks (SNNs) that eliminates the need for inter-core synchronization, thus enhancing speed and energy efficiency. This approach leverages the pre-determined dependencies of neuromorphic cores established during compilation. Each core is equipped with a scheduler that monitors the status of its dependencies, allowing it to safely advance to the next timestep without waiting for other cores. This eliminates the necessity for global synchronization and minimizes core waiting time despite inherent workload imbalances. Comprehensive evaluations using five different SNN workloads show that our architecture achieves a 1.86x speedup and a 1.55x increase in energy efficiency compared to state-of-the-art synchronization architectures.
A Novel Neural Network Training Framework with Data Assimilation
Oct 06, 2020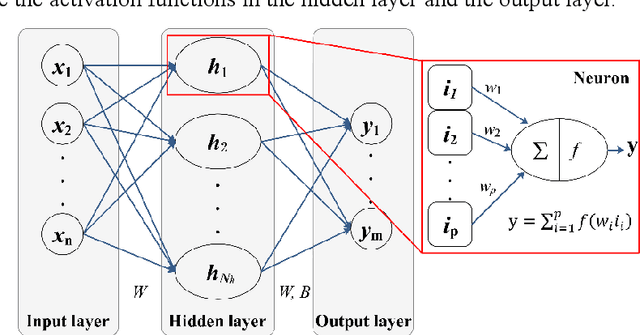
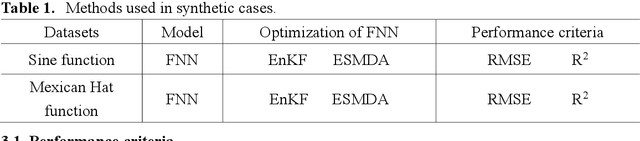
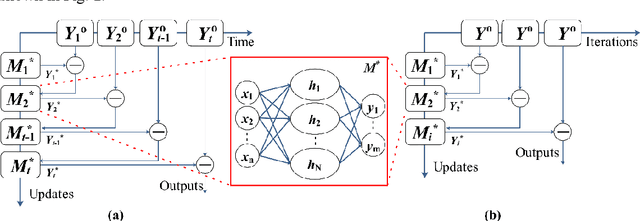
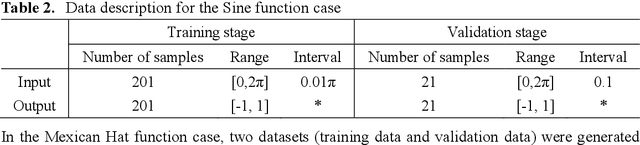
In recent years, the prosperity of deep learning has revolutionized the Artificial Neural Networks. However, the dependence of gradients and the offline training mechanism in the learning algorithms prevents the ANN for further improvement. In this study, a gradient-free training framework based on data assimilation is proposed to avoid the calculation of gradients. In data assimilation algorithms, the error covariance between the forecasts and observations is used to optimize the parameters. Feedforward Neural Networks (FNNs) are trained by gradient decent, data assimilation algorithms (Ensemble Kalman Filter (EnKF) and Ensemble Smoother with Multiple Data Assimilation (ESMDA)), respectively. ESMDA trains FNN with pre-defined iterations by updating the parameters using all the available observations which can be regard as offline learning. EnKF optimize FNN when new observation available by updating parameters which can be regard as online learning. Two synthetic cases with the regression of a Sine Function and a Mexican Hat function are assumed to validate the effectiveness of the proposed framework. The Root Mean Square Error (RMSE) and coefficient of determination (R2) are used as criteria to assess the performance of different methods. The results show that the proposed training framework performed better than the gradient decent method. The proposed framework provides alternatives for online/offline training the existing ANNs (e.g., Convolutional Neural Networks, Recurrent Neural Networks) without the dependence of gradients.