 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asynchronous Multi-core Accelerator for SNN inference
Jul 30, 2024



Spiking Neural Networks (SNNs) are extensively utilized in brain-inspired computing and neuroscience research. To enhance the speed and energy efficiency of SNNs, several many-core accelerators have been developed. However, maintaining the accuracy of SNNs often necessitates frequent explicit synchronization among all cores, which presents a challenge to overall efficiency. In this paper, we propose an asynchronous architecture for Spiking Neural Networks (SNNs) that eliminates the need for inter-core synchronization, thus enhancing speed and energy efficiency. This approach leverages the pre-determined dependencies of neuromorphic cores established during compilation. Each core is equipped with a scheduler that monitors the status of its dependencies, allowing it to safely advance to the next timestep without waiting for other cores. This eliminates the necessity for global synchronization and minimizes core waiting time despite inherent workload imbalances. Comprehensive evaluations using five different SNN workloads show that our architecture achieves a 1.86x speedup and a 1.55x increase in energy efficiency compared to state-of-the-art synchronization architectures.
Darwin3: A large-scale neuromorphic chip with a Novel ISA and On-Chip Learning
Dec 29, 2023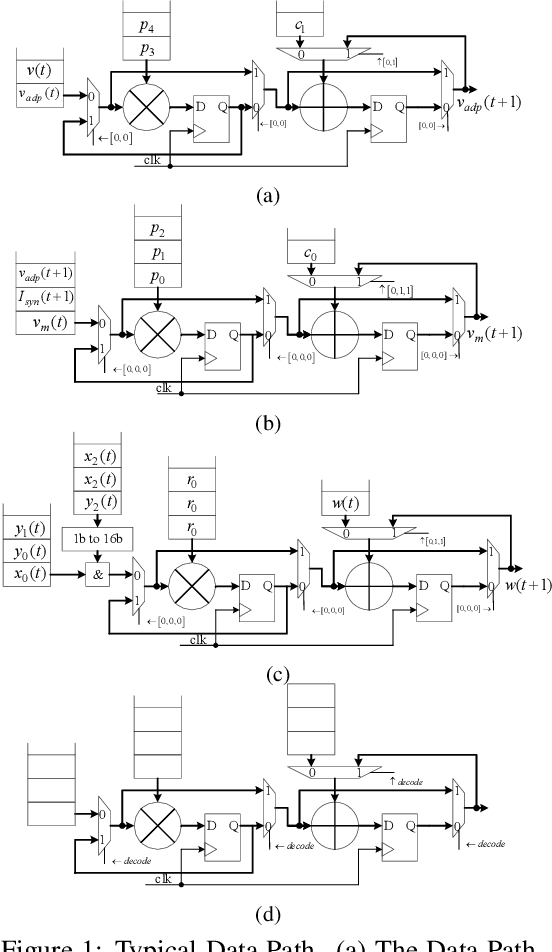
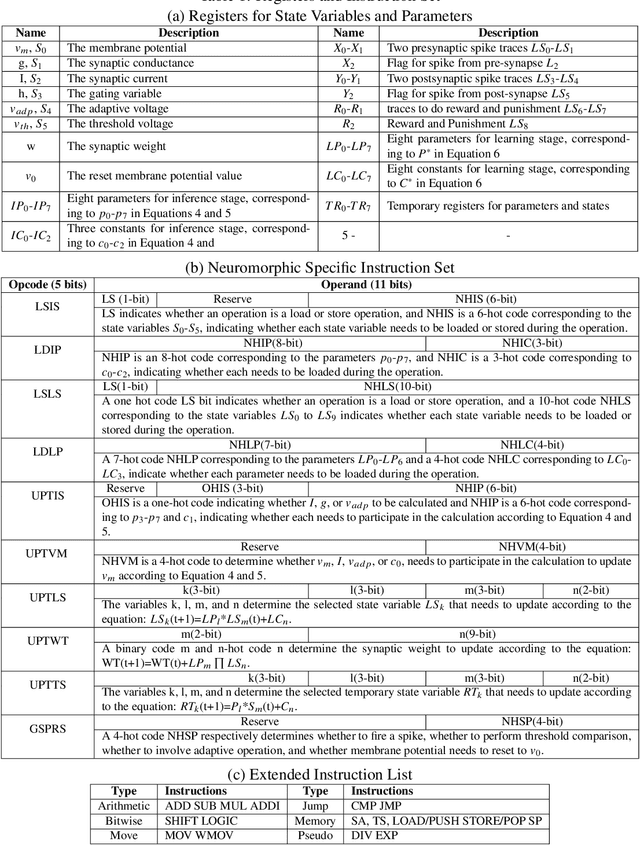
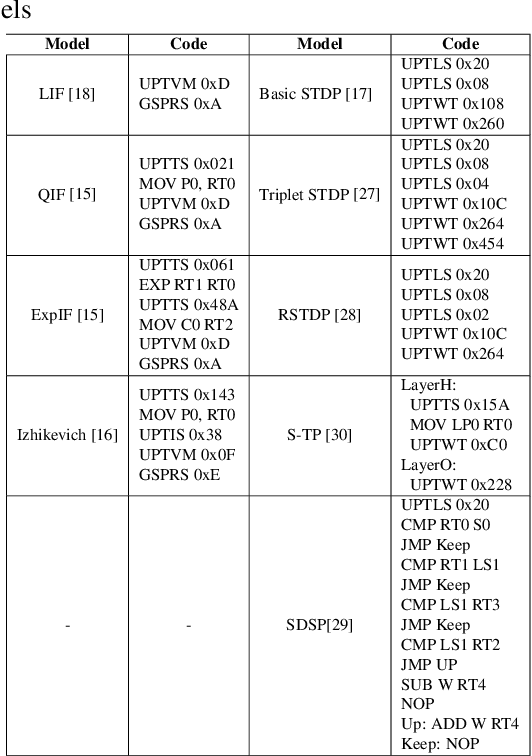
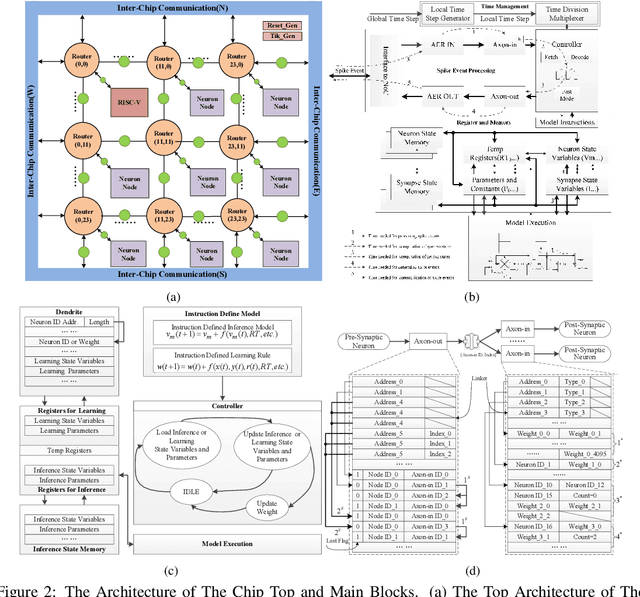
Spiking Neural Networks (SNNs) are gaining increasing attention for their biological plausibility and potential for improved computational efficiency. To match the high spatial-temporal dynamics in SNNs, neuromorphic chips are highly desired to execute SNNs in hardware-based neuron and synapse circuits directly. This paper presents a large-scale neuromorphic chip named Darwin3 with a novel instruction set architecture(ISA), which comprises 10 primary instructions and a few extended instructions. It supports flexible neuron model programming and local learning rule designs. The Darwin3 chip architecture is designed in a mesh of computing nodes with an innovative routing algorithm. We used a compression mechanism to represent synaptic connections, significantly reducing memory usage. The Darwin3 chip supports up to 2.35 million neurons, making it the largest of its kind in neuron scale. The experimental results showed that code density was improved up to 28.3x in Darwin3, and neuron core fan-in and fan-out were improved up to 4096x and 3072x by connection compression compared to the physical memory depth. Our Darwin3 chip also provided memory saving between 6.8X and 200.8X when mapping convolutional spiking neural networks (CSNN) onto the chip, demonstrating state-of-the-art performance in accuracy and latency compared to other neuromorphic chips.