 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoD: Loss-difference OOD Detection by Intentionally Label-Noisifying Unlabeled Wild Data
May 19, 2025Using unlabeled wild data containing both in-distribution (ID) and out-of-distribution (OOD) data to improve the safety and reliability of models has recently received increasing attention. Existing methods either design customized losses for labeled ID and unlabeled wild data then perform joint optimization, or first filter out OOD data from the latter then learn an OOD detector. While achieving varying degrees of success, two potential issues remain: (i) Labeled ID data typically dominates the learning of models, inevitably making models tend to fit OOD data as IDs; (ii) The selection of thresholds for identifying OOD data in unlabeled wild data usually faces dilemma due to the unavailability of pure OOD samples. To address these issues, we propose a novel loss-difference OOD detection framework (LoD) by \textit{intentionally label-noisifying} unlabeled wild data. Such operations not only enable labeled ID data and OOD data in unlabeled wild data to jointly dominate the models' learning but also ensure the distinguishability of the losses between ID and OOD samples in unlabeled wild data, allowing the classic clustering technique (e.g., K-means) to filter these OOD samples without requiring thresholds any longer. We also provide theoretical foundation for LoD's viability, and extensive experiments verify its superiority.
Vertical Federated Learning for Effectiveness, Security, Applicability: A Survey
May 25, 2024



Vertical Federated Learning (VFL) is a privacy-preserving distributed learning paradigm where different parties collaboratively learn models using partitioned features of shared samples, without leaking private data. Recent research has shown promising results addressing various challenges in VFL, highlighting its potential for practical applications in cross-domain collaboration. However, the corresponding research is scattered and lacks organization. To advance VFL research, this survey offers a systematic overview of recent developments. First, we provide a history and background introduction, along with a summary of the general training protocol of VFL. We then revisit the taxonomy in recent reviews and analyze limitations in-depth. For a comprehensive and structured discussion, we synthesize recent research from three fundamental perspectives: effectiveness, security, and applicability. Finally, we discuss several critical future research directions in VFL, which will facilitate the developments in this field. We provide a collection of research lists and periodically update them at https://github.com/shentt67/VFL_Survey.
Heterogeneous Federated Learning: State-of-the-art and Research Challenges
Jul 20, 2023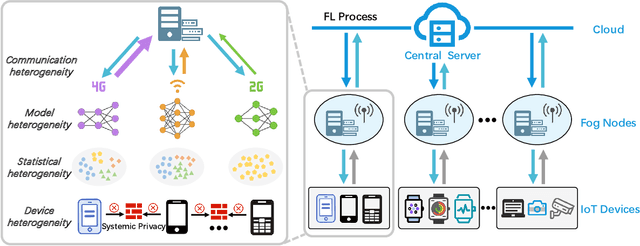
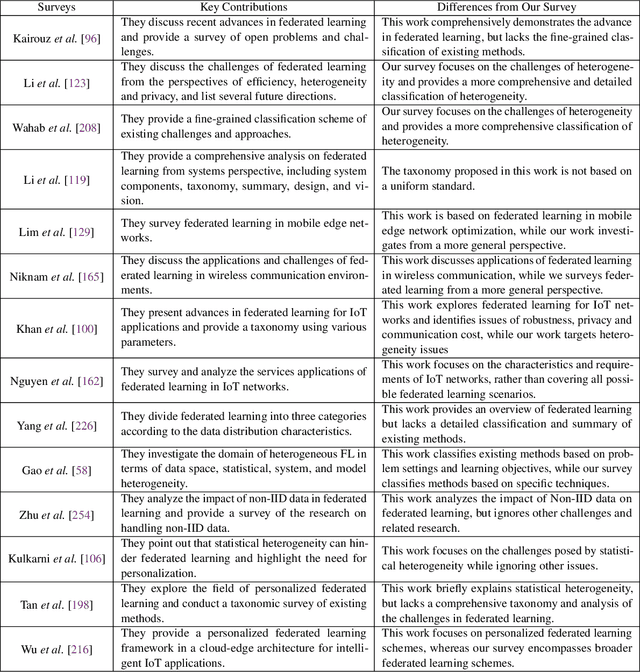
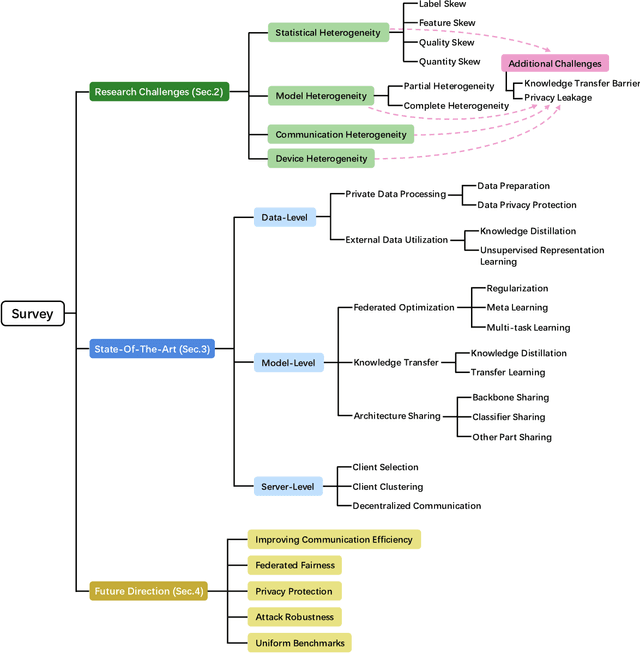
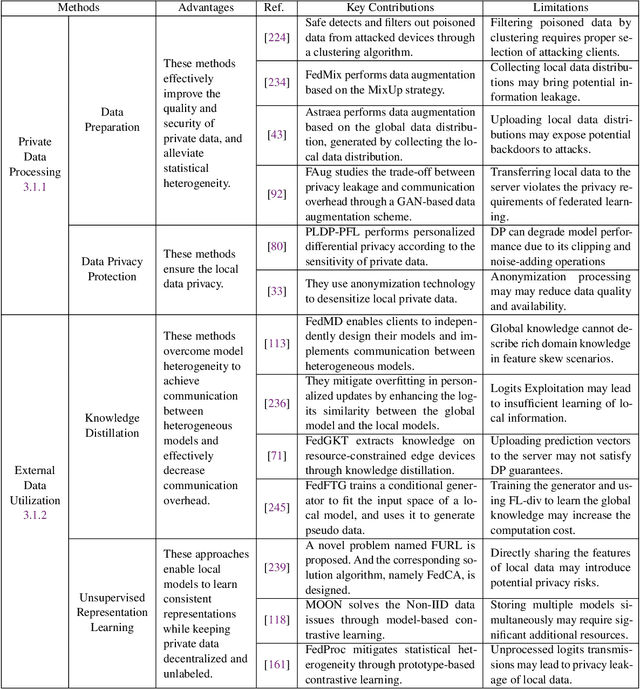
Federated learning (FL) has drawn increasing attention owing to its potential use in large-scale industrial applications. Existing federated learning works mainly focus on model homogeneous settings. However, practical federated learning typically faces the heterogeneity of data distributions, model architectures, network environments, and hardware devices among participant clients. Heterogeneous Federated Learning (HFL) is much more challenging, and corresponding solutions are diverse and complex. Therefore, a systematic survey on this topic about the research challenges and state-of-the-art is essential. In this survey, we firstly summarize the various research challenges in HFL from five aspects: statistical heterogeneity, model heterogeneity, communication heterogeneity, device heterogeneity, and additional challenges. In addition, recent advances in HFL are reviewed and a new taxonomy of existing HFL methods is proposed with an in-depth analysis of their pros and cons. We classify existing methods from three different levels according to the HFL procedure: data-level, model-level, and server-level. Finally, several critical and promising future research directions in HFL are discussed, which may facilitate further developments in this field. A periodically updated collection on HFL is available at https://github.com/marswhu/HFL_Survey.
Open-set Adversarial Defense with Clean-Adversarial Mutual Learning
Feb 12, 2022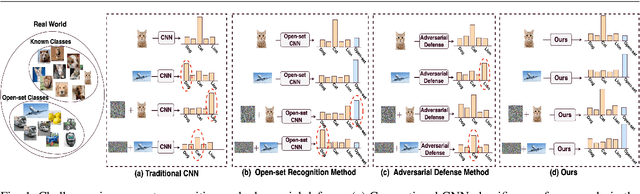

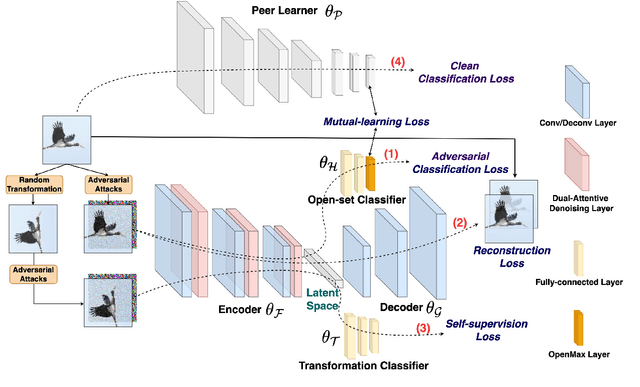
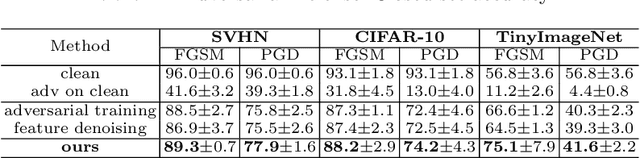
Open-set recognition and adversarial defense study two key aspects of deep learning that are vital for real-world deployment. The objective of open-set recognition is to identify samples from open-set classes during testing, while adversarial defense aims to robustify the network against images perturbed by imperceptible adversarial noise. This paper demonstrates that open-set recognition systems are vulnerable to adversarial samples. Furthermore, this paper shows that adversarial defense mechanisms trained on known classes are unable to generalize well to open-set samples. Motivated by these observations, we emphasize the necessity of an Open-Set Adversarial Defense (OSAD) mechanism. This paper proposes an Open-Set Defense Network with Clean-Adversarial Mutual Learning (OSDN-CAML) as a solution to the OSAD problem. The proposed network designs an encoder with dual-attentive feature-denoising layers coupled with a classifier to learn a noise-free latent feature representation, which adaptively removes adversarial noise guided by channel and spatial-wise attentive filters. Several techniques are exploited to learn a noise-free and informative latent feature space with the aim of improving the performance of adversarial defense and open-set recognition. First, we incorporate a decoder to ensure that clean images can be well reconstructed from the obtained latent features. Then, self-supervision is used to ensure that the latent features are informative enough to carry out an auxiliary task. Finally, to exploit more complementary knowledge from clean image classification to facilitate feature denoising and search for a more generalized local minimum for open-set recognition, we further propose clean-adversarial mutual learning, where a peer network (classifying clean images) is further introduced to mutually learn with the classifier (classifying adversarial images).
Federated Test-Time Adaptive Face Presentation Attack Detection with Dual-Phase Privacy Preservation
Oct 25, 2021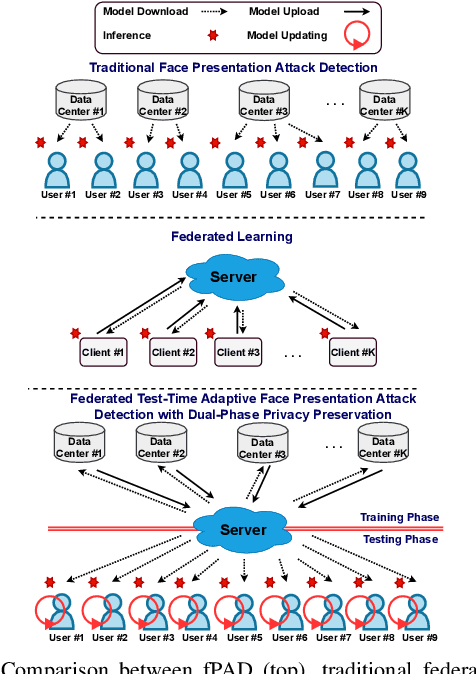
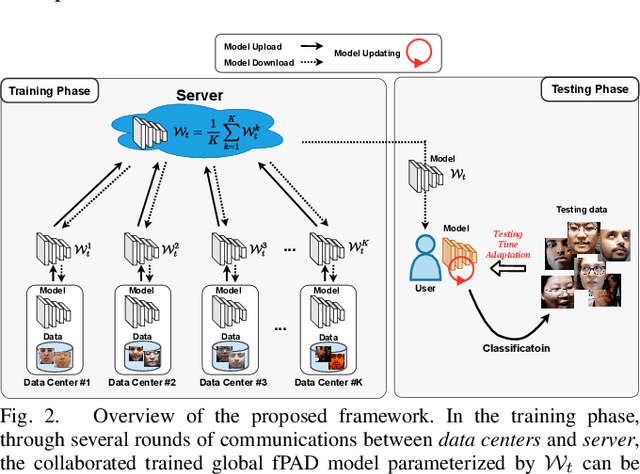
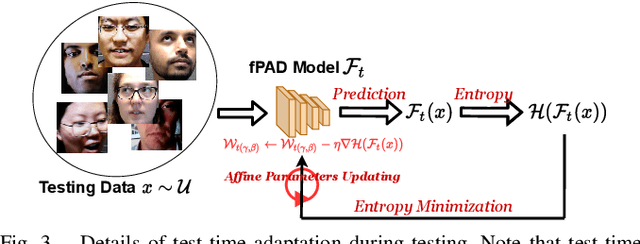

Face presentation attack detection (fPAD) plays a critical role in the modern face recognition pipeline. The generalization ability of face presentation attack detection models to unseen attacks has become a key issue for real-world deployment, which can be improved when models are trained with face images from different input distributions and different types of spoof attacks. In reality, due to legal and privacy issues, training data (both real face images and spoof images) are not allowed to be directly shared between different data sources. In this paper, to circumvent this challenge, we propose a Federated Test-Time Adaptive Face Presentation Attack Detection with Dual-Phase Privacy Preservation framework, with the aim of enhancing the generalization ability of fPAD models in both training and testing phase while preserving data privacy. In the training phase, the proposed framework exploits the federated learning technique, which simultaneously takes advantage of rich fPAD information available at different data sources by aggregating model updates from them without accessing their private data. To further boost the generalization ability, in the testing phase, we explore test-time adaptation by minimizing the entropy of fPAD model prediction on the testing data, which alleviates the domain gap between training and testing data and thus reduces the generalization error of a fPAD model. We introduce the experimental setting to evaluate the proposed framework and carry out extensive experiments to provide various insights about the proposed method for fPAD.
Federated Generalized Face Presentation Attack Detection
Apr 14, 2021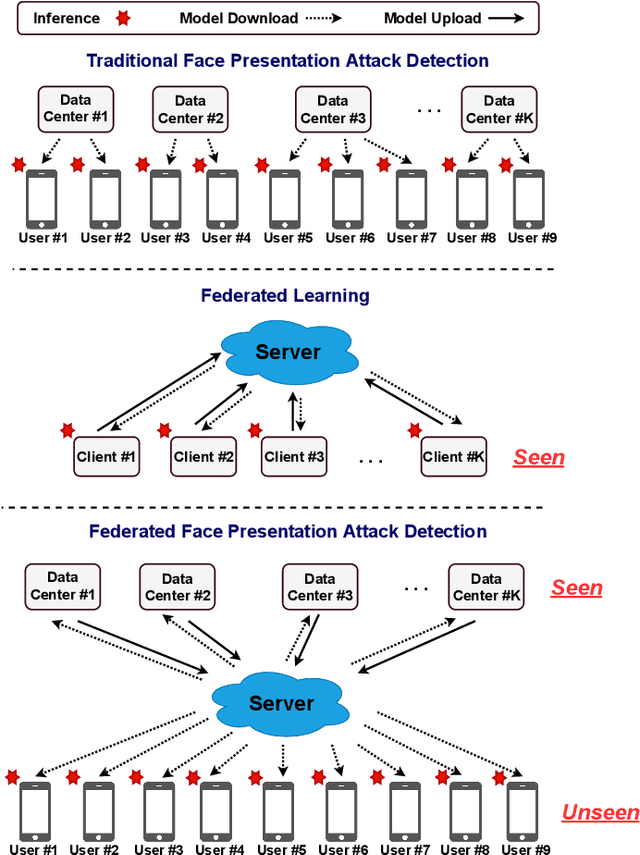
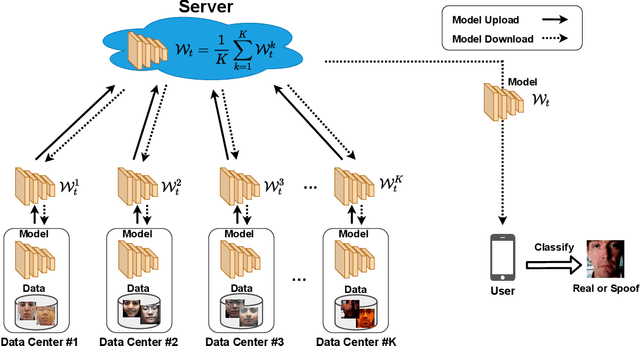
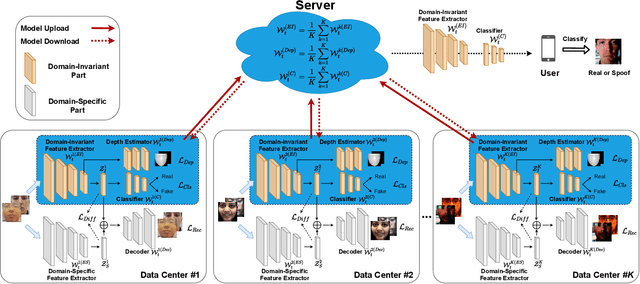

Face presentation attack detection plays a critical role in the modern face recognition pipeline. A face presentation attack detection model with good generalization can be obtained when it is trained with face images from different input distributions and different types of spoof attacks. In reality, training data (both real face images and spoof images) are not directly shared between data owners due to legal and privacy issues. In this paper, with the motivation of circumventing this challenge, we propose a Federated Face Presentation Attack Detection (FedPAD) framework that simultaneously takes advantage of rich fPAD information available at different data owners while preserving data privacy. In the proposed framework, each data center locally trains its own fPAD model. A server learns a global fPAD model by iteratively aggregating model updates from all data centers without accessing private data in each of them. To equip the aggregated fPAD model in the server with better generalization ability to unseen attacks from users, following the basic idea of FedPAD, we further propose a Federated Generalized Face Presentation Attack Detection (FedGPAD) framework. A federated domain disentanglement strategy is introduced in FedGPAD, which treats each data center as one domain and decomposes the fPAD model into domain-invariant and domain-specific parts in each data center. Two parts disentangle the domain-invariant and domain-specific features from images in each local data center, respectively. A server learns a global fPAD model by only aggregating domain-invariant parts of the fPAD models from data centers and thus a more generalized fPAD model can be aggregated in server. We introduce the experimental setting to evaluate the proposed FedPAD and FedGPAD frameworks and carry out extensive experiments to provide various insights about federated learning for fPAD.
Open-set Adversarial Defense
Sep 02, 2020

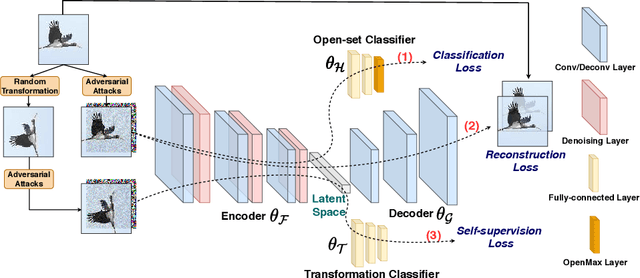
Open-set recognition and adversarial defense study two key aspects of deep learning that are vital for real-world deployment. The objective of open-set recognition is to identify samples from open-set classes during testing, while adversarial defense aims to defend the network against images with imperceptible adversarial perturbations. In this paper, we show that open-set recognition systems are vulnerable to adversarial attacks. Furthermore, we show that adversarial defense mechanisms trained on known classes do not generalize well to open-set samples. Motivated by this observation, we emphasize the need of an Open-Set Adversarial Defense (OSAD) mechanism. This paper proposes an Open-Set Defense Network (OSDN) as a solution to the OSAD problem. The proposed network uses an encoder with feature-denoising layers coupled with a classifier to learn a noise-free latent feature representation. Two techniques are employed to obtain an informative latent feature space with the objective of improving open-set performance. First, a decoder is used to ensure that clean images can be reconstructed from the obtained latent features. Then, self-supervision is used to ensure that the latent features are informative enough to carry out an auxiliary task. We introduce a testing protocol to evaluate OSAD performance and show the effectiveness of the proposed method in multiple object classification datasets. The implementation code of the proposed method is available at: https://github.com/rshaojimmy/ECCV2020-OSAD.
Self-supervised Temporal Discriminative Learning for Video Representation Learning
Aug 05, 2020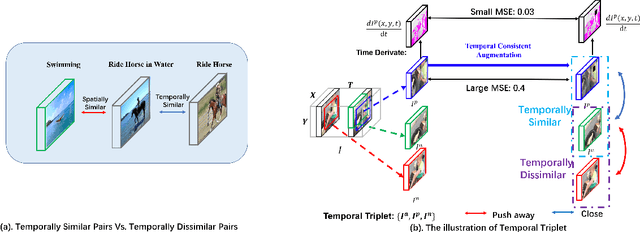
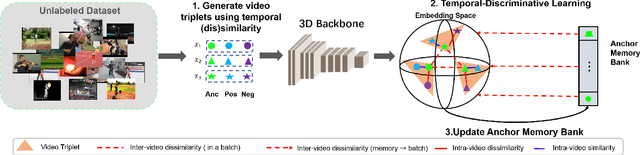
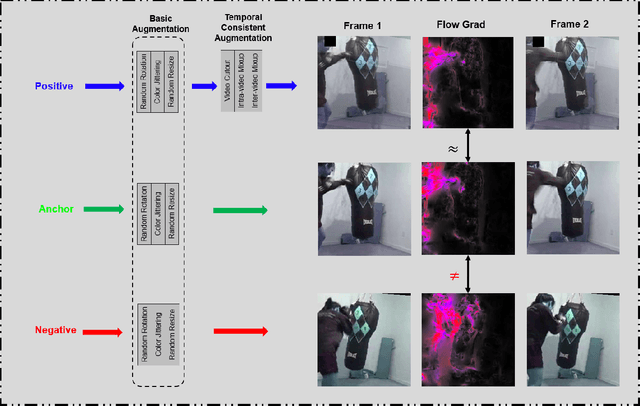
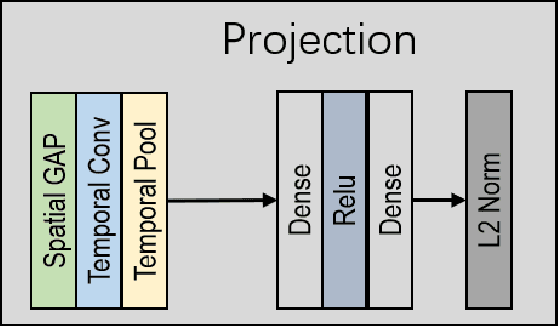
Temporal cues in videos provide important information for recognizing actions accurately. However, temporal-discriminative features can hardly be extracted without using an annotated large-scale video action dataset for training. This paper proposes a novel Video-based Temporal-Discriminative Learning (VTDL) framework in self-supervised manner. Without labelled data for network pretraining, temporal triplet is generated for each anchor video by using segment of the same or different time interval so as to enhance the capacity for temporal feature representation. Measuring temporal information by time derivative, Temporal Consistent Augmentation (TCA) is designed to ensure that the time derivative (in any order) of the augmented positive is invariant except for a scaling constant. Finally, temporal-discriminative features are learnt by minimizing the distance between each anchor and its augmented positive, while the distance between each anchor and its augmented negative as well as other videos saved in the memory bank is maximized to enrich the representation diversity. In the downstream action recognition task, the proposed method significantly outperforms existing related works. Surprisingly, the proposed self-supervised approach is better than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training. The code has been made publicly available on https://github.com/FingerRec/Self-Supervised-Temporal-Discriminative-Representation-Learning-for-Video-Action-Recognition.
Federated Face Anti-spoofing
May 29, 2020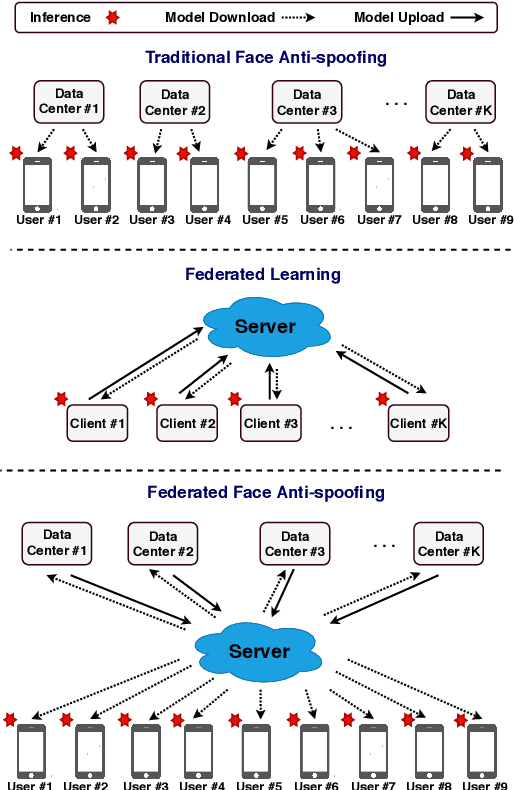
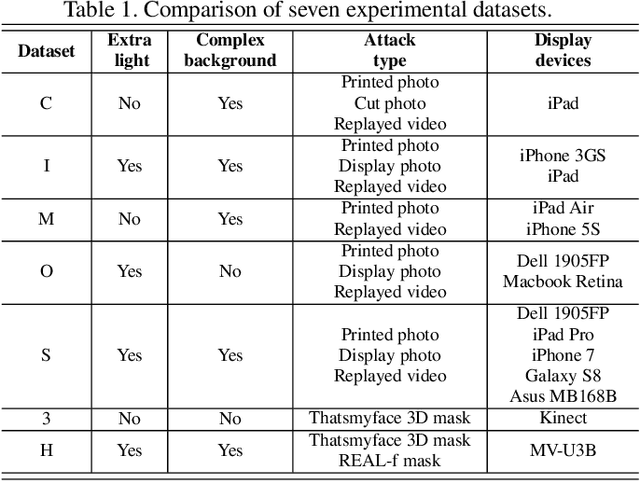
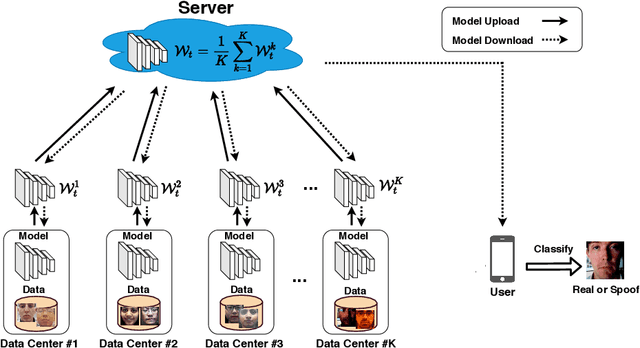
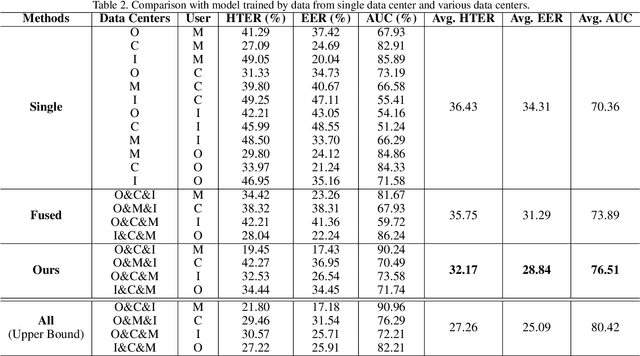
Face presentation attack detection plays a critical role in the modern face recognition pipeline. A face anti-spoofing (FAS) model with good generalization can be obtained when it is trained with face images from different input distributions and different types of spoof attacks. In reality, training data (both real face images and spoof images) are not directly shared between data owners due to legal and privacy issues. In this paper, with the motivation of circumventing this challenge, we propose Federated Face Anti-spoofing (FedFAS) framework. FedFAS simultaneously takes advantage of rich FAS information available at different data owners while preserving data privacy. In the proposed framework, each data owner (referred to as \textit{data centers}) locally trains its own FAS model. A server learns a global FAS model by iteratively aggregating model updates from all data centers without accessing private data in each of them. Once the learned global model converges, it is used for FAS inference. We introduce the experimental setting to evaluate the proposed FedFAS framework and carry out extensive experiments to provide various insights about federated learning for FAS.
Regularized Fine-grained Meta Face Anti-spoofing
Nov 25, 2019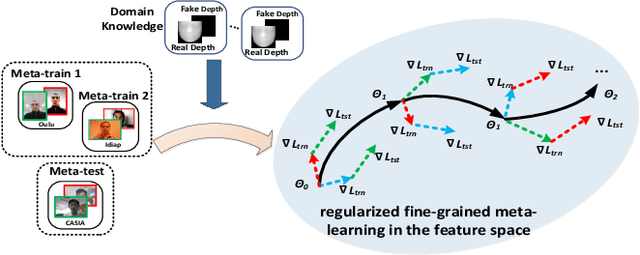
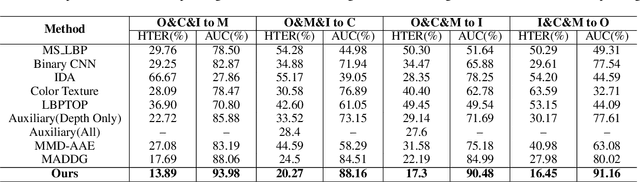
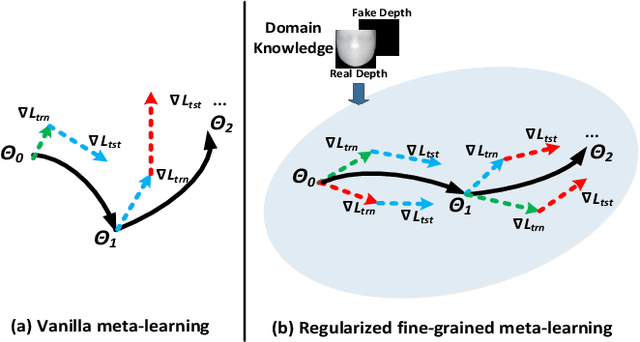

Face presentation attacks have become an increasingly critical concern when face recognition is widely applied. Many face anti-spoofing methods have been proposed, but most of them ignore the generalization ability to unseen attacks. To overcome the limitation, this work casts face anti-spoofing as a domain generalization (DG) problem, and attempts to address this problem by developing a new meta-learning framework called Regularized Fine-grained Meta-learning. To let our face anti-spoofing model generalize well to unseen attacks, the proposed framework trains our model to perform well in the simulated domain shift scenarios, which is achieved by finding generalized learning directions in the meta-learning process. Specifically, the proposed framework incorporates the domain knowledge of face anti-spoofing as the regularization so that meta-learning is conducted in the feature space regularized by the supervision of domain knowledge. This enables our model more likely to find generalized learning directions with the regularized meta-learning for face anti-spoofing task. Besides, to further enhance the generalization ability of our model, the proposed framework adopts a fine-grained learning strategy that simultaneously conducts meta-learning in a variety of domain shift scenarios in each iteration. Extensive experiments on four public datasets validate the effectiveness of the proposed method.