 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Asymmetric Heterogeneous Federated Learning with Corrupted Clients
Mar 12, 2025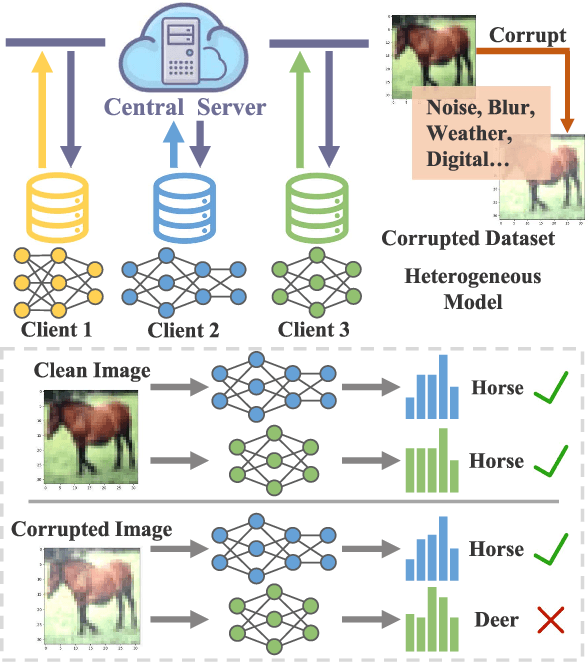
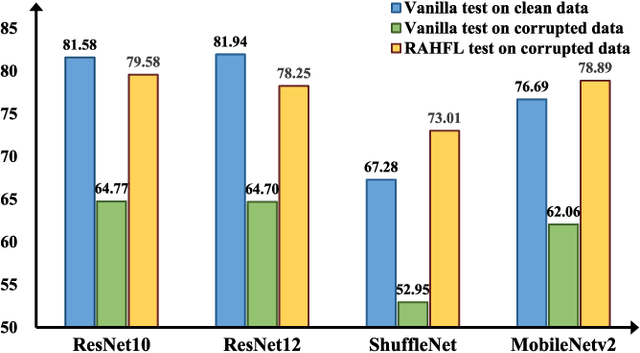
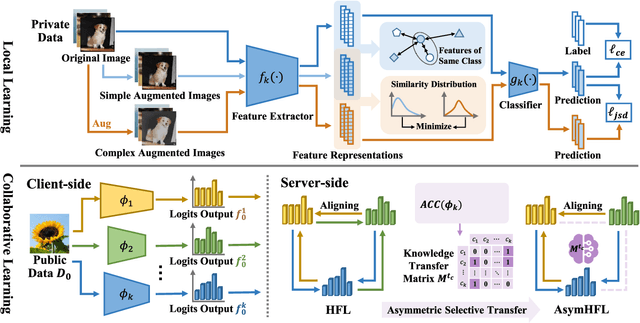

This paper studies a challenging robust federated learning task with model heterogeneous and data corrupted clients, where the clients have different local model structures. Data corruption is unavoidable due to factors such as random noise, compression artifacts, or environmental conditions in real-world deployment, drastically crippling the entire federated system. To address these issues, this paper introduces a novel Robust Asymmetric Heterogeneous Federated Learning (RAHFL) framework. We propose a Diversity-enhanced supervised Contrastive Learning technique to enhance the resilience and adaptability of local models on various data corruption patterns. Its basic idea is to utilize complex augmented samples obtained by the mixed-data augmentation strategy for supervised contrastive learning, thereby enhancing the ability of the model to learn robust and diverse feature representations. Furthermore, we design an Asymmetric Heterogeneous Federated Learning strategy to resist corrupt feedback from external clients. The strategy allows clients to perform selective one-way learning during collaborative learning phase, enabling clients to refrain from incorporating lower-quality information from less robust or underperforming collaborators. Extensive experimental results demonstrate the effectiveness and robustness of our approach in diverse, challenging federated learning environments. Our code and models are public available at https://github.com/FangXiuwen/RAHFL.
Heterogeneous Federated Learning: State-of-the-art and Research Challenges
Jul 20, 2023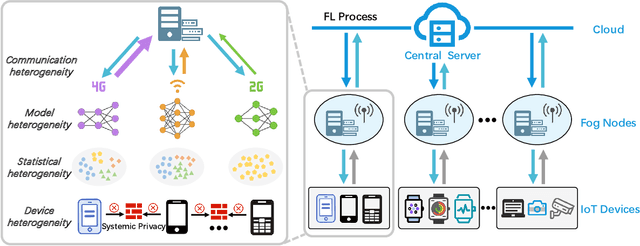
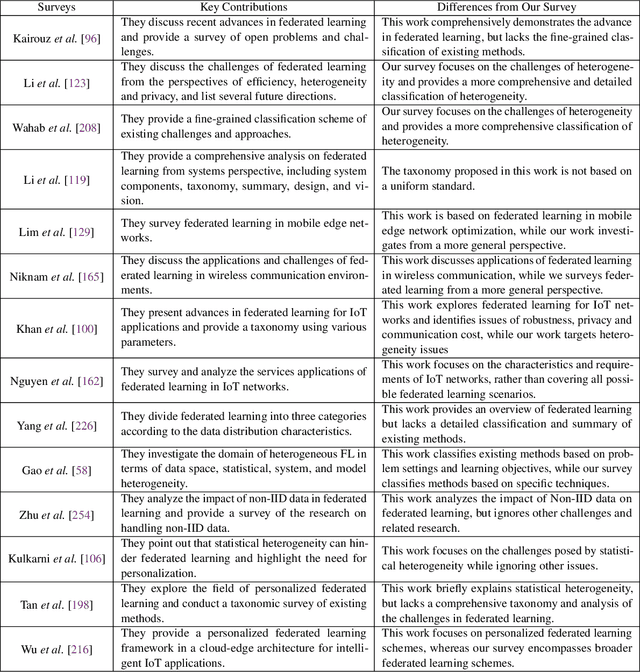
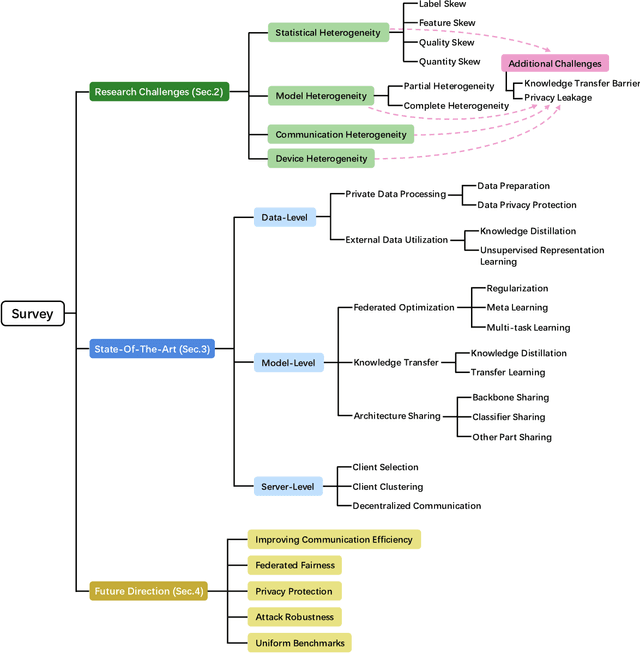
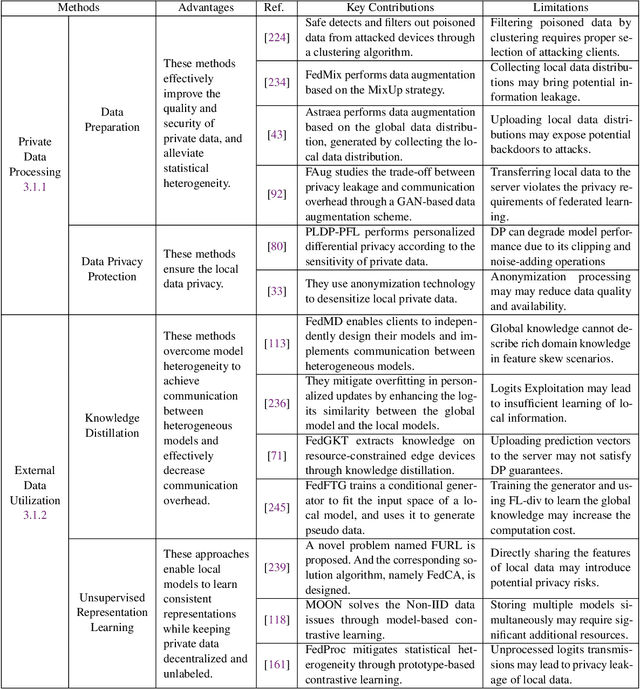
Federated learning (FL) has drawn increasing attention owing to its potential use in large-scale industrial applications. Existing federated learning works mainly focus on model homogeneous settings. However, practical federated learning typically faces the heterogeneity of data distributions, model architectures, network environments, and hardware devices among participant clients. Heterogeneous Federated Learning (HFL) is much more challenging, and corresponding solutions are diverse and complex. Therefore, a systematic survey on this topic about the research challenges and state-of-the-art is essential. In this survey, we firstly summarize the various research challenges in HFL from five aspects: statistical heterogeneity, model heterogeneity, communication heterogeneity, device heterogeneity, and additional challenges. In addition, recent advances in HFL are reviewed and a new taxonomy of existing HFL methods is proposed with an in-depth analysis of their pros and cons. We classify existing methods from three different levels according to the HFL procedure: data-level, model-level, and server-level. Finally, several critical and promising future research directions in HFL are discussed, which may facilitate further developments in this field. A periodically updated collection on HFL is available at https://github.com/marswhu/HFL_Survey.