 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Temporal Discriminative Learning for Video Representation Learning
Paper and Code
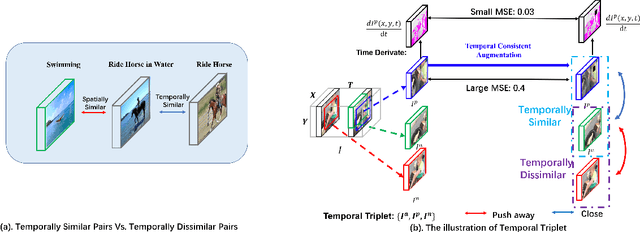
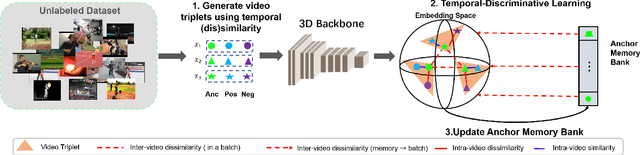
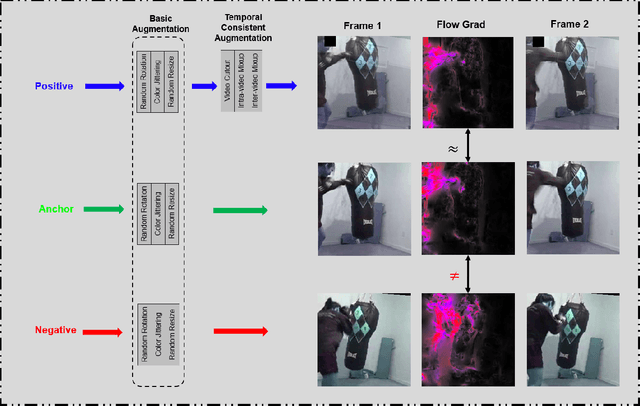
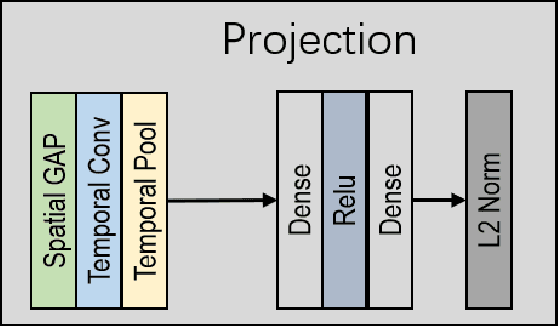
Temporal cues in videos provide important information for recognizing actions accurately. However, temporal-discriminative features can hardly be extracted without using an annotated large-scale video action dataset for training. This paper proposes a novel Video-based Temporal-Discriminative Learning (VTDL) framework in self-supervised manner. Without labelled data for network pretraining, temporal triplet is generated for each anchor video by using segment of the same or different time interval so as to enhance the capacity for temporal feature representation. Measuring temporal information by time derivative, Temporal Consistent Augmentation (TCA) is designed to ensure that the time derivative (in any order) of the augmented positive is invariant except for a scaling constant. Finally, temporal-discriminative features are learnt by minimizing the distance between each anchor and its augmented positive, while the distance between each anchor and its augmented negative as well as other videos saved in the memory bank is maximized to enrich the representation diversity. In the downstream action recognition task, the proposed method significantly outperforms existing related works. Surprisingly, the proposed self-supervised approach is better than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training. The code has been made publicly available on https://github.com/FingerRec/Self-Supervised-Temporal-Discriminative-Representation-Learning-for-Video-Action-Recognition.