 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Mixup for Test-Time Training
Oct 04, 2022


Test-time training provides a new approach solving the problem of domain shift. In its framework, a test-time training phase is inserted between training phase and test phase. During test-time training phase, usually parts of the model are updated with test sample(s). Then the updated model will be used in the test phase. However, utilizing test samples for test-time training has some limitations. Firstly, it will lead to overfitting to the test-time procedure thus hurt the performance on the main task. Besides, updating part of the model without changing other parts will induce a mismatch problem. Thus it is hard to perform better on the main task. To relieve above problems, we propose to use mixup in test-time training (MixTTT) which controls the change of model's parameters as well as completing the test-time procedure. We theoretically show its contribution in alleviating the mismatch problem of updated part and static part for the main task as a specific regularization effect for test-time training. MixTTT can be used as an add-on module in general test-time training based methods to further improve their performance. Experimental results show the effectiveness of our method.
Federated Test-Time Adaptive Face Presentation Attack Detection with Dual-Phase Privacy Preservation
Oct 25, 2021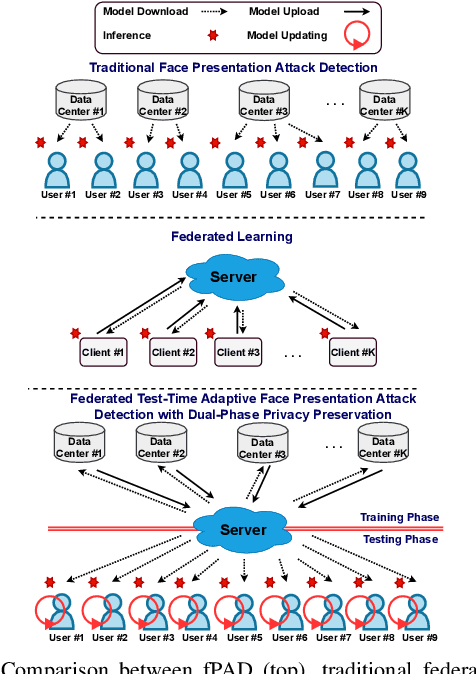
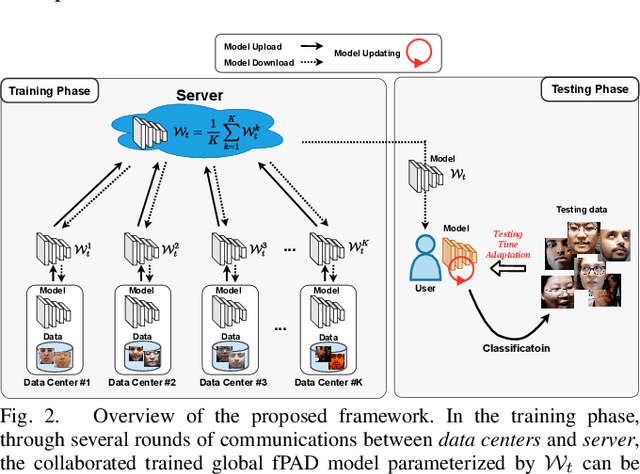
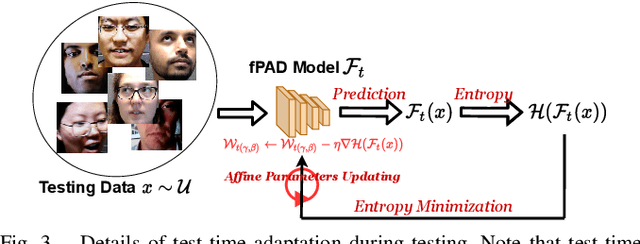

Face presentation attack detection (fPAD) plays a critical role in the modern face recognition pipeline. The generalization ability of face presentation attack detection models to unseen attacks has become a key issue for real-world deployment, which can be improved when models are trained with face images from different input distributions and different types of spoof attacks. In reality, due to legal and privacy issues, training data (both real face images and spoof images) are not allowed to be directly shared between different data sources. In this paper, to circumvent this challenge, we propose a Federated Test-Time Adaptive Face Presentation Attack Detection with Dual-Phase Privacy Preservation framework, with the aim of enhancing the generalization ability of fPAD models in both training and testing phase while preserving data privacy. In the training phase, the proposed framework exploits the federated learning technique, which simultaneously takes advantage of rich fPAD information available at different data sources by aggregating model updates from them without accessing their private data. To further boost the generalization ability, in the testing phase, we explore test-time adaptation by minimizing the entropy of fPAD model prediction on the testing data, which alleviates the domain gap between training and testing data and thus reduces the generalization error of a fPAD model. We introduce the experimental setting to evaluate the proposed framework and carry out extensive experiments to provide various insights about the proposed method for fPAD.