 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixup for Test-Time Training
Oct 04, 2022


Test-time training provides a new approach solving the problem of domain shift. In its framework, a test-time training phase is inserted between training phase and test phase. During test-time training phase, usually parts of the model are updated with test sample(s). Then the updated model will be used in the test phase. However, utilizing test samples for test-time training has some limitations. Firstly, it will lead to overfitting to the test-time procedure thus hurt the performance on the main task. Besides, updating part of the model without changing other parts will induce a mismatch problem. Thus it is hard to perform better on the main task. To relieve above problems, we propose to use mixup in test-time training (MixTTT) which controls the change of model's parameters as well as completing the test-time procedure. We theoretically show its contribution in alleviating the mismatch problem of updated part and static part for the main task as a specific regularization effect for test-time training. MixTTT can be used as an add-on module in general test-time training based methods to further improve their performance. Experimental results show the effectiveness of our method.
Deep Active Learning for Remote Sensing Object Detection
Mar 17, 2020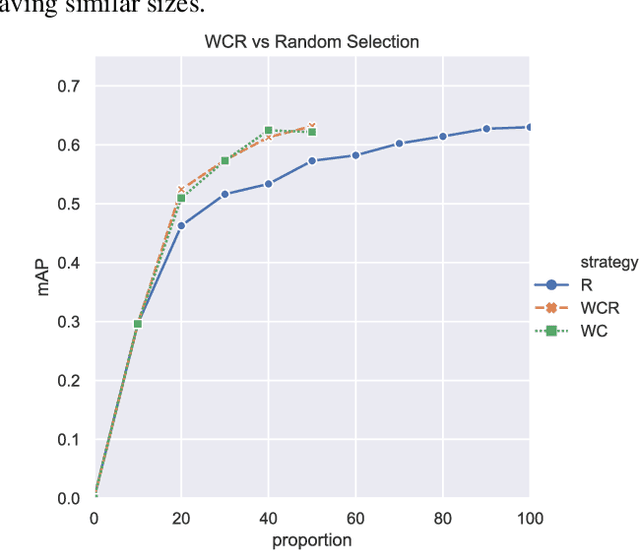
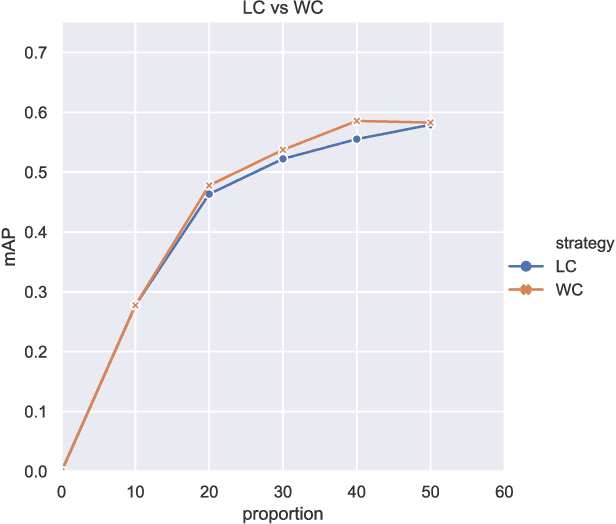
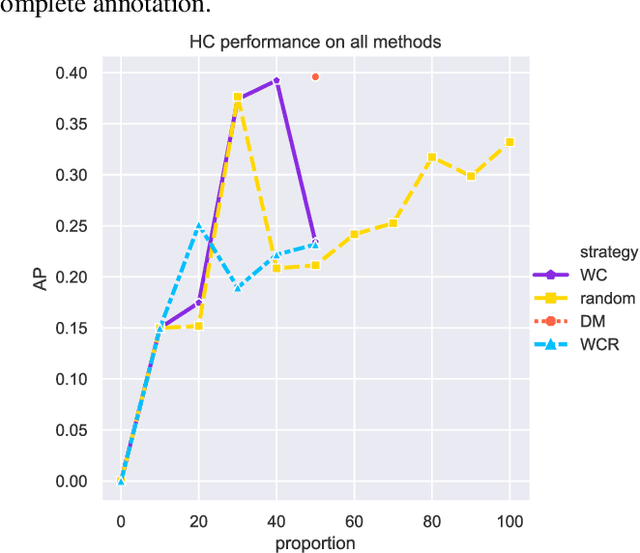
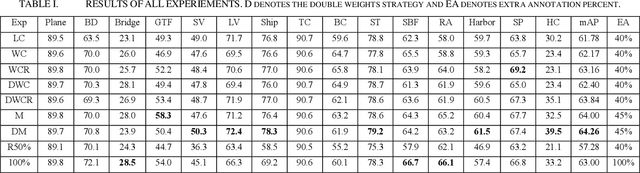
Recently, CNN object detectors have achieved high accuracy on remote sensing images but require huge labor and time costs on annotation. In this paper, we propose a new uncertainty-based active learning which can select images with more information for annotation and detector can still reach high performance with a fraction of the training images. Our method not only analyzes objects' classification uncertainty to find least confident objects but also considers their regression uncertainty to declare outliers. Besides, we bring out two extra weights to overcome two difficulties in remote sensing datasets, class-imbalance and difference in images' objects amount. We experiment our active learning algorithm on DOTA dataset with CenterNet as object detector. We achieve same-level performance as full supervision with only half images. We even override full supervision with 55% images and augmented weights on least confident images.