 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustered Self-Assessment: A Simple yet Effective Method for Uncertainty Quantification in Large Language Models
Jun 02, 2026Large language models (LLMs) demonstrate remarkable performance across diverse tasks, but they often generate responses that appear plausible while being factually incorrect. This problem is compounded by the lack of explicit uncertainty estimates, which makes it difficult for users to judge the reliability of model outputs. Existing uncertainty quantification methods typically rely on indirect signals, such as entropy across sampled generations. These signals can be difficult to interpret and do not fully leverage the model's ability to assess its own uncertainty. We propose a simple yet effective self-assessment method for uncertainty quantification in LLMs. Our approach groups sampled generations into semantically distinct clusters, converts them into answer options in a structured multiple-choice question, and uses the probability assigned by the LLM to each option as a confidence estimate. Experiments across multiple models and datasets show that our method consistently outperforms baseline approaches. Notably, it achieves competitive performance with as few as two additional samples, demonstrating both its effectiveness and efficiency.
Semantic Token Clustering for Efficient Uncertainty Quantification in Large Language Models
Mar 20, 2026Large language models (LLMs) have demonstrated remarkable capabilities across diverse tasks. However, the truthfulness of their outputs is not guaranteed, and their tendency toward overconfidence further limits reliability. Uncertainty quantification offers a promising way to identify potentially unreliable outputs, but most existing methods rely on repeated sampling or auxiliary models, introducing substantial computational overhead. To address these limitations, we propose Semantic Token Clustering (STC), an efficient uncertainty quantification method that leverages the semantic information inherently encoded in LLMs. Specifically, we group tokens into semantically consistent clusters using embedding clustering and prefix matching, and quantify uncertainty based on the probability mass aggregated over the corresponding semantic cluster. Our approach requires only a single generation and does not depend on auxiliary models. Experimental results show that STC achieves performance comparable to state-of-the-art baselines while substantially reducing computational overhead.
Inconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
May 26, 2025Typical methods for evaluating the performance of language models evaluate their ability to answer questions accurately. These evaluation metrics are acceptable for determining the extent to which language models can understand and reason about text in a general sense, but fail to capture nuanced capabilities, such as the ability of language models to recognize and obey rare grammar points, particularly in languages other than English. We measure the perplexity of language models when confronted with the "first person psych predicate restriction" grammar point in Japanese. Weblab is the only tested open source model in the 7-10B parameter range which consistently assigns higher perplexity to ungrammatical psych predicate sentences than grammatical ones. We give evidence that Weblab's uniformly bad tokenization is a possible root cause for its good performance, and show that Llama 3's perplexity on grammatical psych predicate sentences can be reduced by orders of magnitude (28x difference) by restricting test sentences to those with uniformly well-behaved tokenizations. We show in further experiments on machine translation tasks that language models will use alternative grammar patterns in order to produce grammatical sentences when tokenization issues prevent the most natural sentence from being output.
Which Programming Language and What Features at Pre-training Stage Affect Downstream Logical Inference Performance?
Oct 09, 2024



Recent large language models (LLMs) have demonstrated remarkable generalization abilities in mathematics and logical reasoning tasks. Prior research indicates that LLMs pre-trained with programming language data exhibit high mathematical and reasoning abilities; however, this causal relationship has not been rigorously tested. Our research aims to verify which programming languages and features during pre-training affect logical inference performance. Specifically, we pre-trained decoder-based language models from scratch using datasets from ten programming languages (e.g., Python, C, Java) and three natural language datasets (Wikipedia, Fineweb, C4) under identical conditions. Thereafter, we evaluated the trained models in a few-shot in-context learning setting on logical reasoning tasks: FLD and bAbi, which do not require commonsense or world knowledge. The results demonstrate that nearly all models trained with programming languages consistently outperform those trained with natural languages, indicating that programming languages contain factors that elicit logic inference performance. In addition, we found that models trained with programming languages exhibit a better ability to follow instructions compared to those trained with natural languages. Further analysis reveals that the depth of Abstract Syntax Trees representing parsed results of programs also affects logical reasoning performance. These findings will offer insights into the essential elements of pre-training for acquiring the foundational abilities of LLMs.
Answer When Needed, Forget When Not: Language Models Pretend to Forget via In-Context Knowledge Unlearning
Oct 01, 2024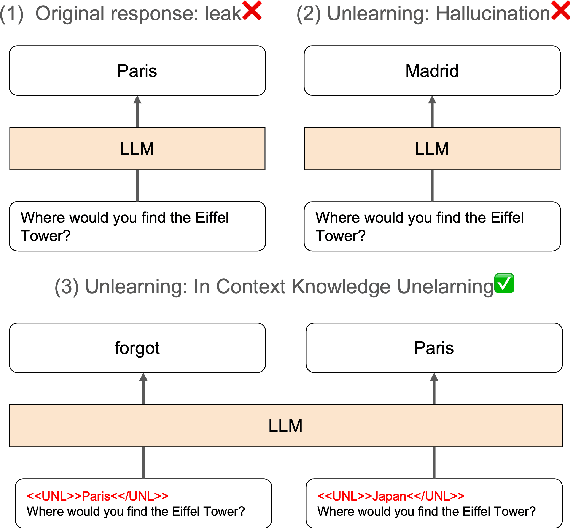

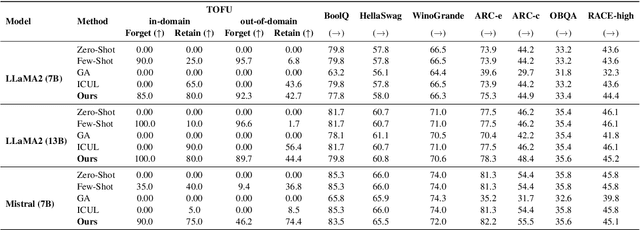
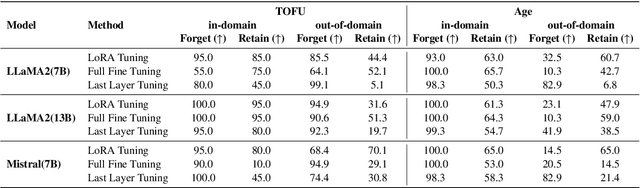
As large language models (LLMs) are applied across diverse domains, the ability to selectively unlearn specific information has become increasingly essential. For instance, LLMs are expected to provide confidential information to authorized internal users, such as employees or trusted partners, while withholding it from external users, including the general public and unauthorized entities. In response to this challenge, we propose a novel method termed ``in-context knowledge unlearning'', which enables the model to selectively forget information in test-time based on the context of the query. Our method fine-tunes pre-trained LLMs to enable prompt unlearning of target knowledge within the context, while preserving other knowledge. Experiments on the TOFU and AGE datasets using Llama2-7B/13B and Mistral-7B models show our method achieves up to 95% forgetting accuracy while retaining 80% of unrelated knowledge, significantly outperforming baselines in both in-domain and out-of-domain scenarios. Further investigation into the model's internal behavior revealed that while fine-tuned LLMs generate correct predictions in the middle layers and maintain them up to the final layer, they make the decision to forget at the last layer, i.e., ``LLMs pretend to forget''. Our findings offer valuable insights into enhancing the robustness of unlearning mechanisms in LLMs, setting a foundation for future research in the field.
Language Models Do Hard Arithmetic Tasks Easily and Hardly Do Easy Arithmetic Tasks
Jun 04, 2024



The ability (and inability) of large language models (LLMs) to perform arithmetic tasks has been the subject of much theoretical and practical debate. We show that LLMs are frequently able to correctly and confidently predict the first digit of n-digit by m-digit multiplication tasks without using chain of thought reasoning, despite these tasks require compounding operations to solve. Simultaneously, LLMs in practice often fail to correctly or confidently predict the last digit of an n-digit by m-digit multiplication, a task equivalent to 1-digit by 1-digit multiplication which can be easily learned or memorized. We show that the latter task can be solved more robustly when the LLM is conditioned on all of the correct higher-order digits, which on average increases the confidence of the correct last digit on 5-digit by 5-digit multiplication tasks using Llama 2-13B by over 230% (0.13 to 0.43) and Mistral-7B by 150% (0.22 to 0.55).
Real-World Robot Applications of Foundation Models: A Review
Feb 08, 2024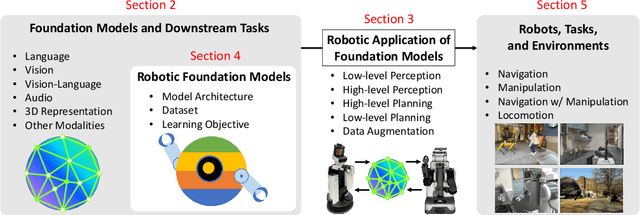
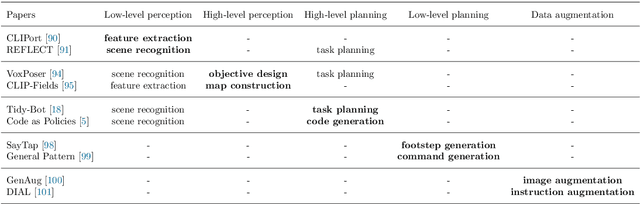
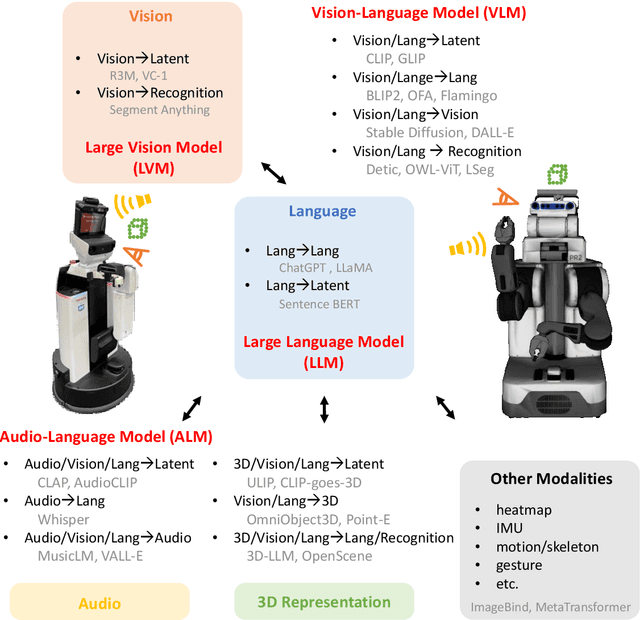
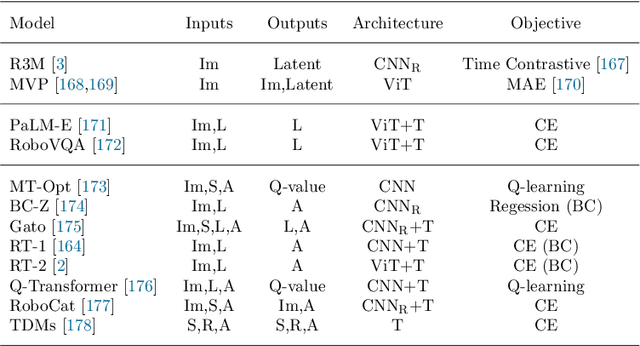
Recent developments in foundation models, like Large Language Models (LLMs) and Vision-Language Models (VLMs), trained on extensive data, facilitate flexible application across different tasks and modalities. Their impact spans various fields, including healthcare, education, and robotics. This paper provides an overview of the practical application of foundation models in real-world robotics, with a primary emphasis on the replacement of specific components within existing robot systems. The summary encompasses the perspective of input-output relationships in foundation models, as well as their role in perception, motion planning, and control within the field of robotics. This paper concludes with a discussion of future challenges and implications for practical robot applications.
Audio Mosaicing with Simulation-based Inference
Oct 26, 2022



Mosaics and collages have been an integral part of art for decades. Particularly important in contemporary media art is the audio mosaic, in which an artist manually combines several audio sources in order to construct one single coherent sound, combining elements from disparate sources. Here we propose an algorithm to automatically create audio mosaics using the simulation-based inference paradigm. Our algorithm takes as input an audio file that one wishes to approximate, and a list of audio files one can use for approximation, finding a posterior distribution from which one can sample reconstructions of the original audio file, using the sources in an interpretable and disentangled manner. We validate our approach by creating an audio mosaic which reconstructs the sound of a traditional Korean funeral using 100 K-pop songs rearranged and overlapped.
Detecting and Quantifying Malicious Activity with Simulation-based Inference
Oct 07, 2021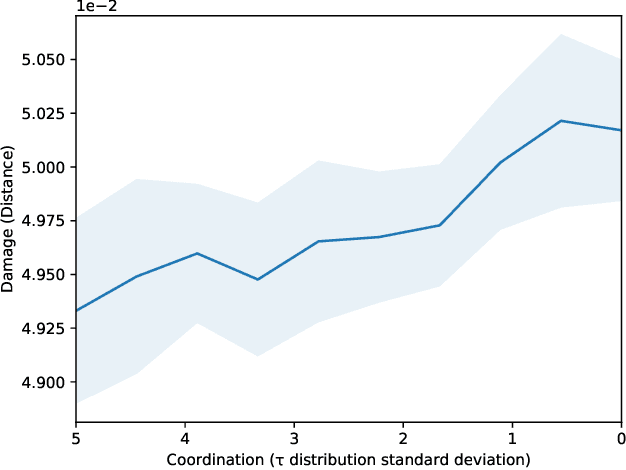
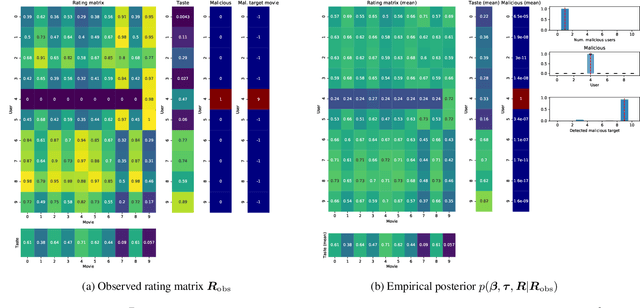
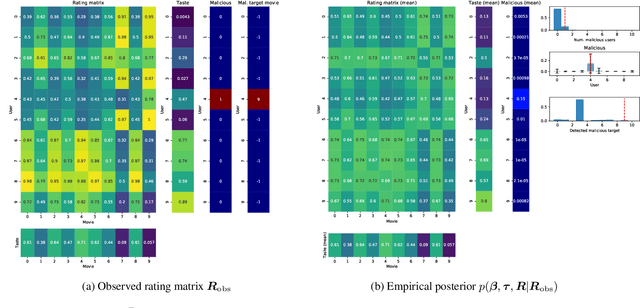
We propose the use of probabilistic programming techniques to tackle the malicious user identification problem in a recommendation algorithm. Probabilistic programming provides numerous advantages over other techniques, including but not limited to providing a disentangled representation of how malicious users acted under a structured model, as well as allowing for the quantification of damage caused by malicious users. We show experiments in malicious user identification using a model of regular and malicious users interacting with a simple recommendation algorithm, and provide a novel simulation-based measure for quantifying the effects of a user or group of users on its dynamics.
Simulation-Based Inference for Global Health Decisions
May 14, 2020
The COVID-19 pandemic has highlighted the importance of in-silico epidemiological modelling in predicting the dynamics of infectious diseases to inform health policy and decision makers about suitable prevention and containment strategies. Work in this setting involves solving challenging inference and control problems in individual-based models of ever increasing complexity. Here we discuss recent breakthroughs in machine learning, specifically in simulation-based inference, and explore its potential as a novel venue for model calibration to support the design and evaluation of public health interventions. To further stimulate research, we are developing software interfaces that turn two cornerstone COVID-19 and malaria epidemiology models COVID-sim, (https://github.com/mrc-ide/covid-sim/) and OpenMalaria (https://github.com/SwissTPH/openmalaria) into probabilistic programs, enabling efficient interpretable Bayesian inference within those simulators.