 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Is This?: Context-Aware Object Ownership Inference with Uncertainty-Guided Questioning
May 27, 2026Service robots must infer object ownership to correctly interpret instructions such as "bring me my cup." However, ownership is a latent attribute that cannot be directly observed, and existing methods often rely on limited cues such as recent usage, making them unreliable in scenarios such as temporary sharing. We propose a framework for context-aware ownership inference with uncertainty-guided interaction (COIN). The method integrates user background information and object usage history using a large language model (LLM) to estimate ownership scores. To handle uncertainty, we apply conformal prediction to construct a set of plausible owners and selectively generate user queries when the prediction is uncertain. Experiments in a simulated home environment show that the proposed method consistently outperforms baseline approaches, achieving a Subset Accuracy of 0.988 and a Mean Jaccard index of 0.991. The method also maintains high performance in scenarios involving temporary use and shared ownership. The results demonstrate that combining contextual reasoning with uncertainty-aware interaction improves both estimation accuracy and robustness. The project page is available at https://emergentsystemlabstudent.github.io/COIN/.
Reducing Mental Workload through On-Demand Human Assistance for Physical Action Failures in LLM-based Multi-Robot Coordination
Mar 30, 2026Multi-robot coordination based on large language models (LLMs) has attracted growing attention, since LLMs enable the direct translation of natural language instructions into robot action plans by decomposing tasks and generating high-level plans. However, recovering from physical execution failures remains difficult, and tasks often stagnate due to the repetition of the same unsuccessful actions. While frameworks for remote robot operation using Mixed Reality were proposed, there have been few attempts to implement remote error resolution specifically for physical failures in multi-robot environments. In this study, we propose REPAIR (Robot Execution with Planned And Interactive Recovery), a human-in-the-loop framework that integrates remote error resolution into LLM-based multi-robot planning. In this method, robots execute tasks autonomously; however, when an irrecoverable failure occurs, the LLM requests assistance from an operator, enabling task continuity through remote intervention. Evaluations using a multi-robot trash collection task in a real-world environment confirmed that REPAIR significantly improves task progress (the number of items cleared within a time limit) compared to fully autonomous methods. Furthermore, for easily collectable items, it achieved task progress equivalent to full remote control. The results also suggested that the mental workload on the operator may differ in terms of physical demand and effort. The project website is https://emergentsystemlabstudent.github.io/REPAIR/.
Multi-Robot Task Planning for Multi-Object Retrieval Tasks with Distributed On-Site Knowledge via Large Language Models
Sep 16, 2025



It is crucial to efficiently execute instructions such as "Find an apple and a banana" or "Get ready for a field trip," which require searching for multiple objects or understanding context-dependent commands. This study addresses the challenging problem of determining which robot should be assigned to which part of a task when each robot possesses different situational on-site knowledge-specifically, spatial concepts learned from the area designated to it by the user. We propose a task planning framework that leverages large language models (LLMs) and spatial concepts to decompose natural language instructions into subtasks and allocate them to multiple robots. We designed a novel few-shot prompting strategy that enables LLMs to infer required objects from ambiguous commands and decompose them into appropriate subtasks. In our experiments, the proposed method achieved 47/50 successful assignments, outperforming random (28/50) and commonsense-based assignment (26/50). Furthermore, we conducted qualitative evaluations using two actual mobile manipulators. The results demonstrated that our framework could handle instructions, including those involving ad hoc categories such as "Get ready for a field trip," by successfully performing task decomposition, assignment, sequential planning, and execution.
Toward Ownership Understanding of Objects: Active Question Generation with Large Language Model and Probabilistic Generative Model
Sep 16, 2025Robots operating in domestic and office environments must understand object ownership to correctly execute instructions such as ``Bring me my cup.'' However, ownership cannot be reliably inferred from visual features alone. To address this gap, we propose Active Ownership Learning (ActOwL), a framework that enables robots to actively generate and ask ownership-related questions to users. ActOwL employs a probabilistic generative model to select questions that maximize information gain, thereby acquiring ownership knowledge efficiently to improve learning efficiency. Additionally, by leveraging commonsense knowledge from Large Language Models (LLM), objects are pre-classified as either shared or owned, and only owned objects are targeted for questioning. Through experiments in a simulated home environment and a real-world laboratory setting, ActOwL achieved significantly higher ownership clustering accuracy with fewer questions than baseline methods. These findings demonstrate the effectiveness of combining active inference with LLM-guided commonsense reasoning, advancing the capability of robots to acquire ownership knowledge for practical and socially appropriate task execution.
Co-Creative Learning via Metropolis-Hastings Interaction between Humans and AI
Jun 18, 2025



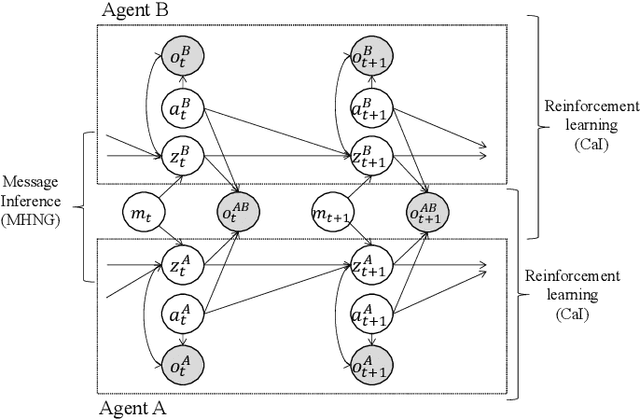
We propose co-creative learning as a novel paradigm where humans and AI, i.e., biological and artificial agents, mutually integrate their partial perceptual information and knowledge to construct shared external representations, a process we interpret as symbol emergence. Unlike traditional AI teaching based on unilateral knowledge transfer, this addresses the challenge of integrating information from inherently different modalities. We empirically test this framework using a human-AI interaction model based on the Metropolis-Hastings naming game (MHNG), a decentralized Bayesian inference mechanism. In an online experiment, 69 participants played a joint attention naming game (JA-NG) with one of three computer agent types (MH-based, always-accept, or always-reject) under partial observability. Results show that human-AI pairs with an MH-based agent significantly improved categorization accuracy through interaction and achieved stronger convergence toward a shared sign system. Furthermore, human acceptance behavior aligned closely with the MH-derived acceptance probability. These findings provide the first empirical evidence for co-creative learning emerging in human-AI dyads via MHNG-based interaction. This suggests a promising path toward symbiotic AI systems that learn with humans, rather than from them, by dynamically aligning perceptual experiences, opening a new venue for symbiotic AI alignment.
Generative Emergent Communication: Large Language Model is a Collective World Model
Dec 31, 2024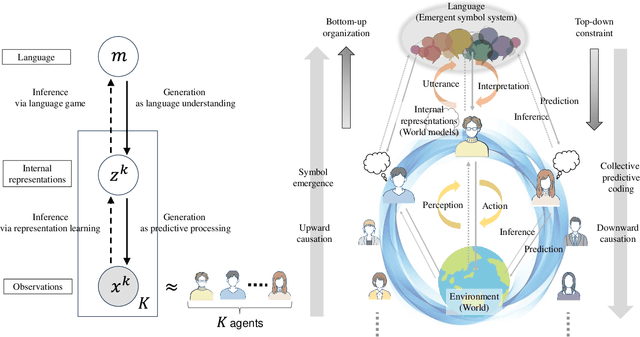


This study proposes a unifying theoretical framework called generative emergent communication (generative EmCom) that bridges emergent communication, world models, and large language models (LLMs) through the lens of collective predictive coding (CPC). The proposed framework formalizes the emergence of language and symbol systems through decentralized Bayesian inference across multiple agents, extending beyond conventional discriminative model-based approaches to emergent communication. This study makes the following two key contributions: First, we propose generative EmCom as a novel framework for understanding emergent communication, demonstrating how communication emergence in multi-agent reinforcement learning (MARL) can be derived from control as inference while clarifying its relationship to conventional discriminative approaches. Second, we propose a mathematical formulation showing the interpretation of LLMs as collective world models that integrate multiple agents' experiences through CPC. The framework provides a unified theoretical foundation for understanding how shared symbol systems emerge through collective predictive coding processes, bridging individual cognitive development and societal language evolution. Through mathematical formulations and discussion on prior works, we demonstrate how this framework explains fundamental aspects of language emergence and offers practical insights for understanding LLMs and developing sophisticated AI systems for improving human-AI interaction and multi-agent systems.
SimSiam Naming Game: A Unified Approach for Representation Learning and Emergent Communication
Oct 29, 2024



Emergent communication, driven by generative models, enables agents to develop a shared language for describing their individual views of the same objects through interactions. Meanwhile, self-supervised learning (SSL), particularly SimSiam, uses discriminative representation learning to make representations of augmented views of the same data point closer in the representation space. Building on the prior work of VI-SimSiam, which incorporates a generative and Bayesian perspective into the SimSiam framework via variational inference (VI) interpretation, we propose SimSiam+VAE, a unified approach for both representation learning and emergent communication. SimSiam+VAE integrates a variational autoencoder (VAE) into the predictor of the SimSiam network to enhance representation learning and capture uncertainty. Experimental results show that SimSiam+VAE outperforms both SimSiam and VI-SimSiam. We further extend this model into a communication framework called the SimSiam Naming Game (SSNG), which applies the generative and Bayesian approach based on VI to develop internal representations and emergent language, while utilizing the discriminative process of SimSiam to facilitate mutual understanding between agents. In experiments with established models, despite the dynamic alternation of agent roles during interactions, SSNG demonstrates comparable performance to the referential game and slightly outperforms the Metropolis-Hastings naming game.
DEQ-MCL: Discrete-Event Queue-based Monte-Carlo Localization
Apr 22, 2024



Spatial cognition in hippocampal formation is posited to play a crucial role in the development of self-localization techniques for robots. In this paper, we propose a self-localization approach, DEQ-MCL, based on the discrete event queue hypothesis associated with phase precession within the hippocampal formation. Our method effectively estimates the posterior distribution of states, encompassing both past, present, and future states that are organized as a queue. This approach enables the smoothing of the posterior distribution of past states using current observations and the weighting of the joint distribution by considering the feasibility of future states. Our findings indicate that the proposed method holds promise for augmenting self-localization performance in indoor environments.
Real-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning
Apr 15, 2024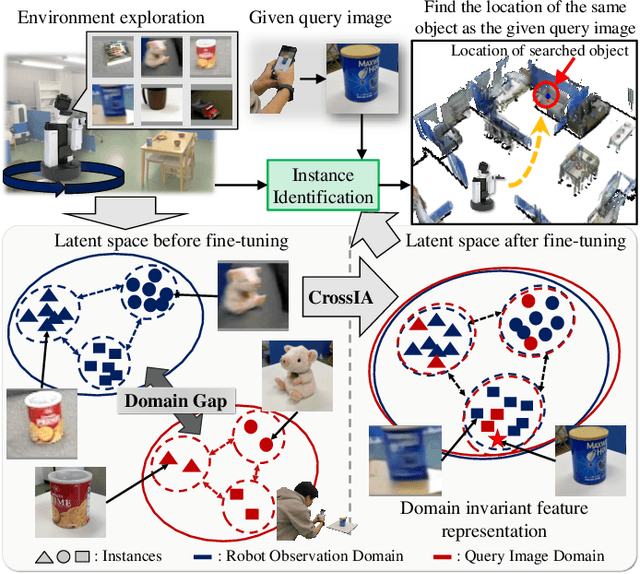

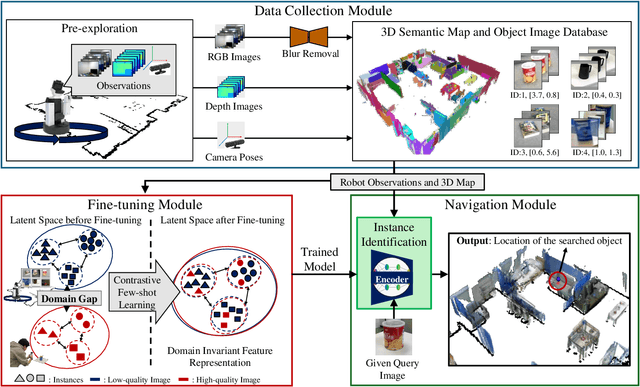
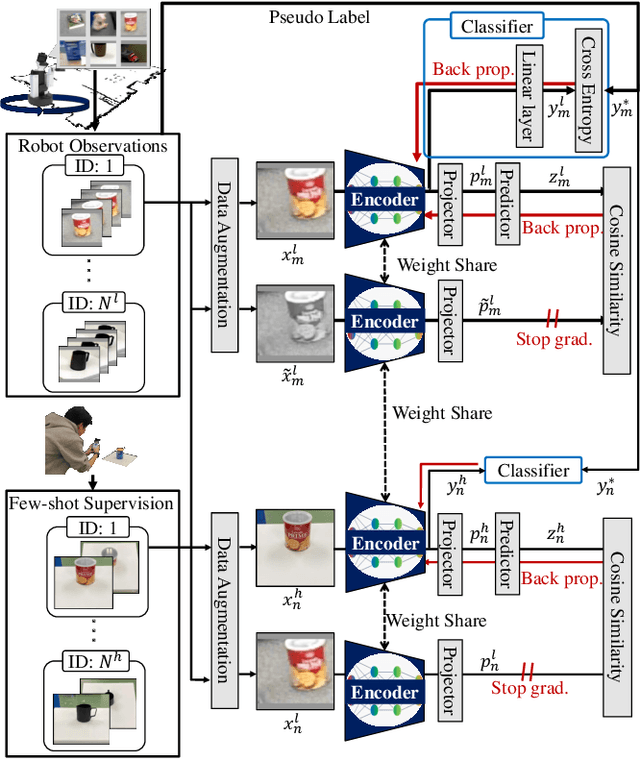
Improving instance-specific image goal navigation (InstanceImageNav), which locates the identical object in a real-world environment from a query image, is essential for robotic systems to assist users in finding desired objects. The challenge lies in the domain gap between low-quality images observed by the moving robot, characterized by motion blur and low-resolution, and high-quality query images provided by the user. Such domain gaps could significantly reduce the task success rate but have not been the focus of previous work. To address this, we propose a novel method called Few-shot Cross-quality Instance-aware Adaptation (CrossIA), which employs contrastive learning with an instance classifier to align features between massive low- and few high-quality images. This approach effectively reduces the domain gap by bringing the latent representations of cross-quality images closer on an instance basis. Additionally, the system integrates an object image collection with a pre-trained deblurring model to enhance the observed image quality. Our method fine-tunes the SimSiam model, pre-trained on ImageNet, using CrossIA. We evaluated our method's effectiveness through an InstanceImageNav task with 20 different types of instances, where the robot identifies the same instance in a real-world environment as a high-quality query image. Our experiments showed that our method improves the task success rate by up to three times compared to the baseline, a conventional approach based on SuperGlue. These findings highlight the potential of leveraging contrastive learning and image enhancement techniques to bridge the domain gap and improve object localization in robotic applications. The project website is https://emergentsystemlabstudent.github.io/DomainBridgingNav/.
Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
Apr 15, 2024



Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.