 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning
Apr 15, 2024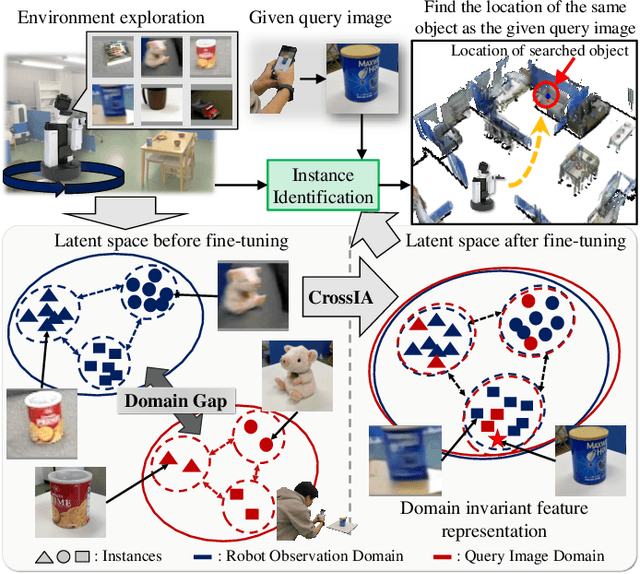

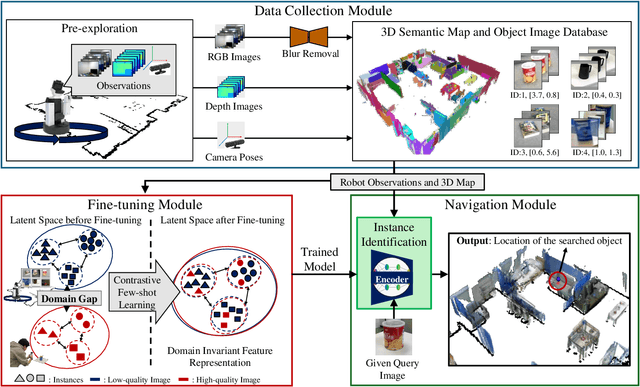
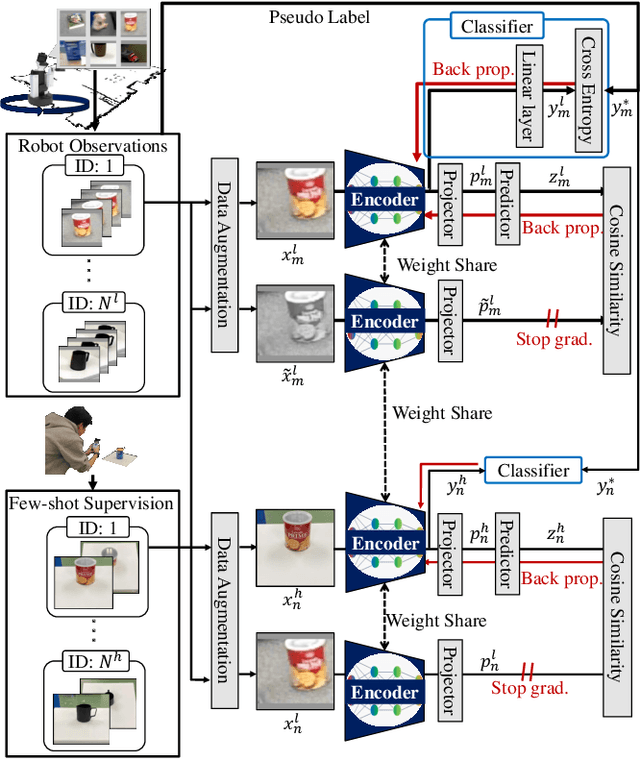
Improving instance-specific image goal navigation (InstanceImageNav), which locates the identical object in a real-world environment from a query image, is essential for robotic systems to assist users in finding desired objects. The challenge lies in the domain gap between low-quality images observed by the moving robot, characterized by motion blur and low-resolution, and high-quality query images provided by the user. Such domain gaps could significantly reduce the task success rate but have not been the focus of previous work. To address this, we propose a novel method called Few-shot Cross-quality Instance-aware Adaptation (CrossIA), which employs contrastive learning with an instance classifier to align features between massive low- and few high-quality images. This approach effectively reduces the domain gap by bringing the latent representations of cross-quality images closer on an instance basis. Additionally, the system integrates an object image collection with a pre-trained deblurring model to enhance the observed image quality. Our method fine-tunes the SimSiam model, pre-trained on ImageNet, using CrossIA. We evaluated our method's effectiveness through an InstanceImageNav task with 20 different types of instances, where the robot identifies the same instance in a real-world environment as a high-quality query image. Our experiments showed that our method improves the task success rate by up to three times compared to the baseline, a conventional approach based on SuperGlue. These findings highlight the potential of leveraging contrastive learning and image enhancement techniques to bridge the domain gap and improve object localization in robotic applications. The project website is https://emergentsystemlabstudent.github.io/DomainBridgingNav/.
Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
Apr 15, 2024



Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.
An Estimation Framework for Passerby Engagement Interacting with Social Robots
Jun 06, 2022

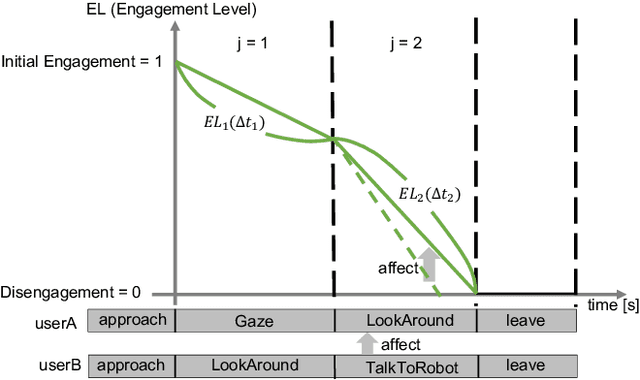
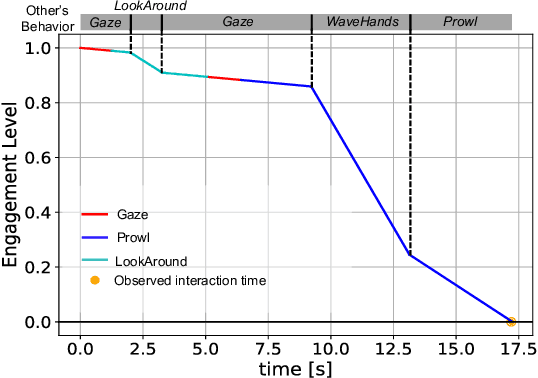
Social robots are expected to be a human labor support technology, and one application of them is an advertising medium in public spaces. When social robots provide information, such as recommended shops, adaptive communication according to the user's state is desired. User engagement, which is also defined as the level of interest in the robot, is likely to play an important role in adaptive communication. Therefore, in this paper, we propose a new framework to estimate user engagement. The proposed method focuses on four unsolved open problems: multi-party interactions, process of state change in engagement, difficulty in annotating engagement, and interaction dataset in the real world. The accuracy of the proposed method for estimating engagement was evaluated using interaction duration. The results show that the interaction duration can be accurately estimated by considering the influence of the behaviors of other people; this also implies that the proposed model accurately estimates the level of engagement during interaction with the robot.