 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Mental Workload through On-Demand Human Assistance for Physical Action Failures in LLM-based Multi-Robot Coordination
Mar 30, 2026Multi-robot coordination based on large language models (LLMs) has attracted growing attention, since LLMs enable the direct translation of natural language instructions into robot action plans by decomposing tasks and generating high-level plans. However, recovering from physical execution failures remains difficult, and tasks often stagnate due to the repetition of the same unsuccessful actions. While frameworks for remote robot operation using Mixed Reality were proposed, there have been few attempts to implement remote error resolution specifically for physical failures in multi-robot environments. In this study, we propose REPAIR (Robot Execution with Planned And Interactive Recovery), a human-in-the-loop framework that integrates remote error resolution into LLM-based multi-robot planning. In this method, robots execute tasks autonomously; however, when an irrecoverable failure occurs, the LLM requests assistance from an operator, enabling task continuity through remote intervention. Evaluations using a multi-robot trash collection task in a real-world environment confirmed that REPAIR significantly improves task progress (the number of items cleared within a time limit) compared to fully autonomous methods. Furthermore, for easily collectable items, it achieved task progress equivalent to full remote control. The results also suggested that the mental workload on the operator may differ in terms of physical demand and effort. The project website is https://emergentsystemlabstudent.github.io/REPAIR/.
Toward Ownership Understanding of Objects: Active Question Generation with Large Language Model and Probabilistic Generative Model
Sep 16, 2025Robots operating in domestic and office environments must understand object ownership to correctly execute instructions such as ``Bring me my cup.'' However, ownership cannot be reliably inferred from visual features alone. To address this gap, we propose Active Ownership Learning (ActOwL), a framework that enables robots to actively generate and ask ownership-related questions to users. ActOwL employs a probabilistic generative model to select questions that maximize information gain, thereby acquiring ownership knowledge efficiently to improve learning efficiency. Additionally, by leveraging commonsense knowledge from Large Language Models (LLM), objects are pre-classified as either shared or owned, and only owned objects are targeted for questioning. Through experiments in a simulated home environment and a real-world laboratory setting, ActOwL achieved significantly higher ownership clustering accuracy with fewer questions than baseline methods. These findings demonstrate the effectiveness of combining active inference with LLM-guided commonsense reasoning, advancing the capability of robots to acquire ownership knowledge for practical and socially appropriate task execution.
Multi-Robot Task Planning for Multi-Object Retrieval Tasks with Distributed On-Site Knowledge via Large Language Models
Sep 16, 2025



It is crucial to efficiently execute instructions such as "Find an apple and a banana" or "Get ready for a field trip," which require searching for multiple objects or understanding context-dependent commands. This study addresses the challenging problem of determining which robot should be assigned to which part of a task when each robot possesses different situational on-site knowledge-specifically, spatial concepts learned from the area designated to it by the user. We propose a task planning framework that leverages large language models (LLMs) and spatial concepts to decompose natural language instructions into subtasks and allocate them to multiple robots. We designed a novel few-shot prompting strategy that enables LLMs to infer required objects from ambiguous commands and decompose them into appropriate subtasks. In our experiments, the proposed method achieved 47/50 successful assignments, outperforming random (28/50) and commonsense-based assignment (26/50). Furthermore, we conducted qualitative evaluations using two actual mobile manipulators. The results demonstrated that our framework could handle instructions, including those involving ad hoc categories such as "Get ready for a field trip," by successfully performing task decomposition, assignment, sequential planning, and execution.
Real-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning
Apr 15, 2024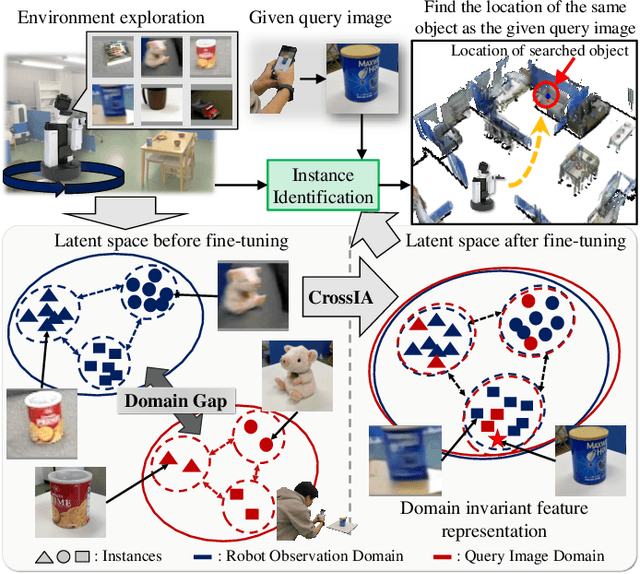

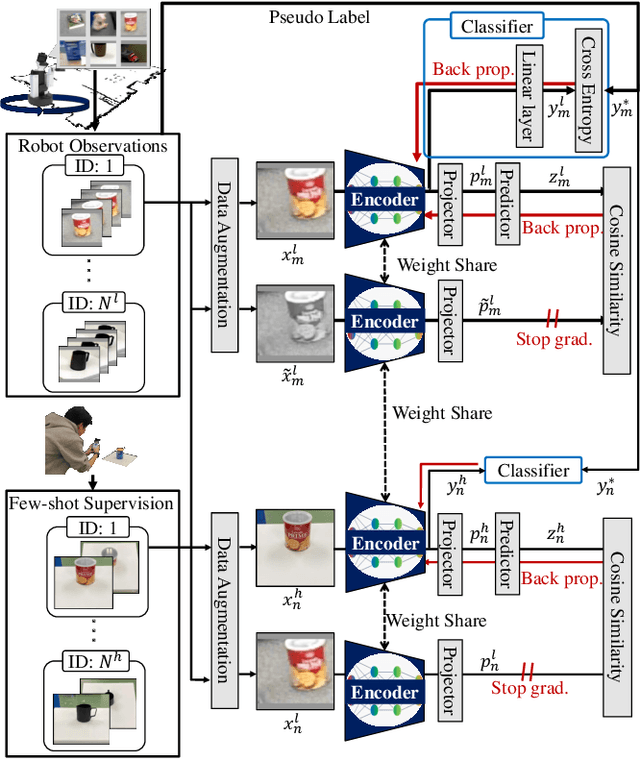
Improving instance-specific image goal navigation (InstanceImageNav), which locates the identical object in a real-world environment from a query image, is essential for robotic systems to assist users in finding desired objects. The challenge lies in the domain gap between low-quality images observed by the moving robot, characterized by motion blur and low-resolution, and high-quality query images provided by the user. Such domain gaps could significantly reduce the task success rate but have not been the focus of previous work. To address this, we propose a novel method called Few-shot Cross-quality Instance-aware Adaptation (CrossIA), which employs contrastive learning with an instance classifier to align features between massive low- and few high-quality images. This approach effectively reduces the domain gap by bringing the latent representations of cross-quality images closer on an instance basis. Additionally, the system integrates an object image collection with a pre-trained deblurring model to enhance the observed image quality. Our method fine-tunes the SimSiam model, pre-trained on ImageNet, using CrossIA. We evaluated our method's effectiveness through an InstanceImageNav task with 20 different types of instances, where the robot identifies the same instance in a real-world environment as a high-quality query image. Our experiments showed that our method improves the task success rate by up to three times compared to the baseline, a conventional approach based on SuperGlue. These findings highlight the potential of leveraging contrastive learning and image enhancement techniques to bridge the domain gap and improve object localization in robotic applications. The project website is https://emergentsystemlabstudent.github.io/DomainBridgingNav/.
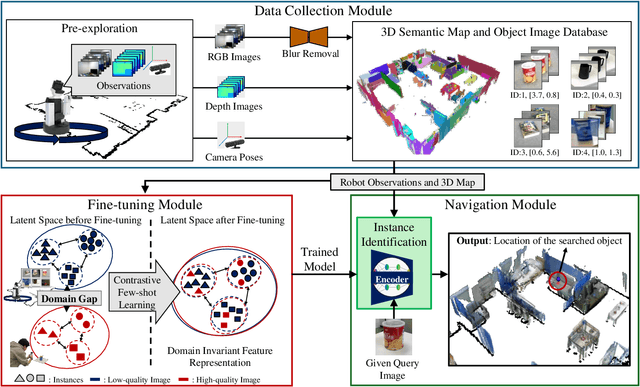
Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
Apr 15, 2024



Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.
Active Exploration based on Information Gain by Particle Filter for Efficient Spatial Concept Formation
Nov 20, 2022Autonomous robots are required to actively and adaptively learn the categories and words of various places by exploring the surrounding environment and interacting with users. In semantic mapping and spatial language acquisition conducted using robots, it is costly and labor-intensive to prepare training datasets that contain linguistic instructions from users. Therefore, we aimed to enable mobile robots to learn spatial concepts through autonomous active exploration. This study is characterized by interpreting the `action' of the robot that asks the user the question `What kind of place is this?' in the context of active inference. We propose an active inference method, spatial concept formation with information gain-based active exploration (SpCoAE), that combines sequential Bayesian inference by particle filters and position determination based on information gain in a probabilistic generative model. Our experiment shows that the proposed method can efficiently determine a position to form appropriate spatial concepts in home environments. In particular, it is important to conduct efficient exploration that leads to appropriate concept formation and quickly covers the environment without adopting a haphazard exploration strategy.
Map completion from partial observation using the global structure of multiple environmental maps
Mar 16, 2021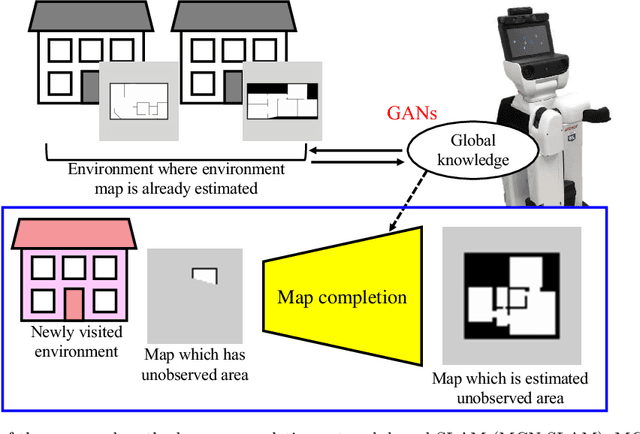
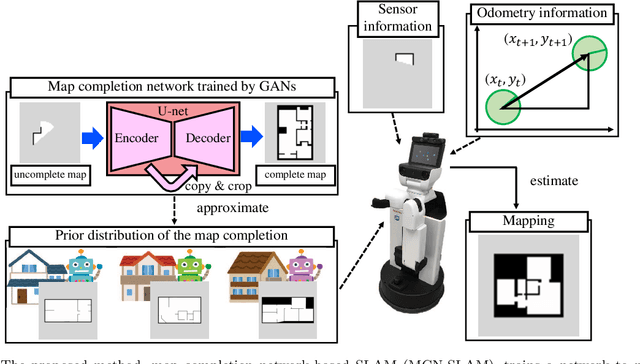
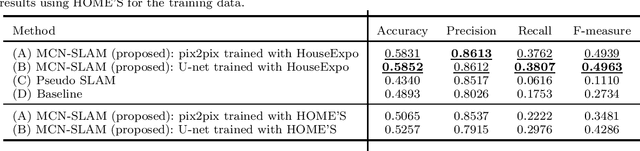
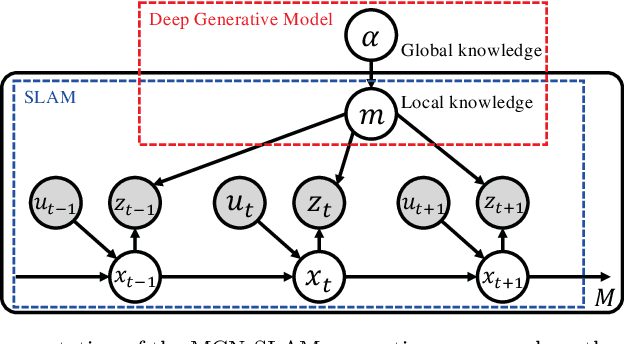
Using the spatial structure of various indoor environments as prior knowledge, the robot would construct the map more efficiently. Autonomous mobile robots generally apply simultaneous localization and mapping (SLAM) methods to understand the reachable area in newly visited environments. However, conventional mapping approaches are limited by only considering sensor observation and control signals to estimate the current environment map. This paper proposes a novel SLAM method, map completion network-based SLAM (MCN-SLAM), based on a probabilistic generative model incorporating deep neural networks for map completion. These map completion networks are primarily trained in the framework of generative adversarial networks (GANs) to extract the global structure of large amounts of existing map data. We show in experiments that the proposed method can estimate the environment map 1.3 times better than the previous SLAM methods in the situation of partial observation.
Autonomous Planning Based on Spatial Concepts to Tidy Up Home Environments with Service Robots
Feb 10, 2020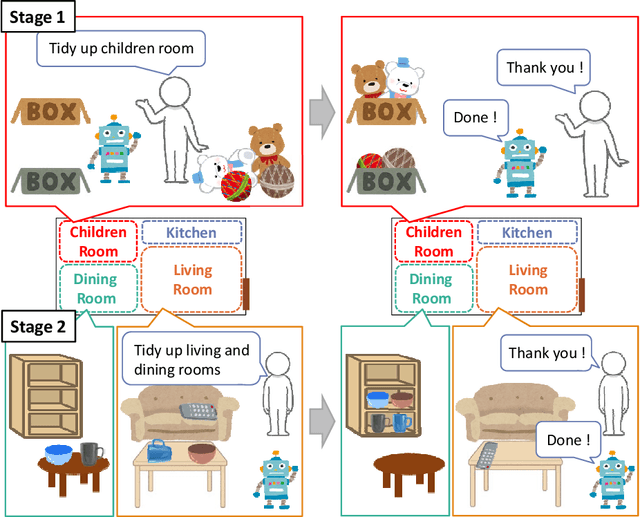

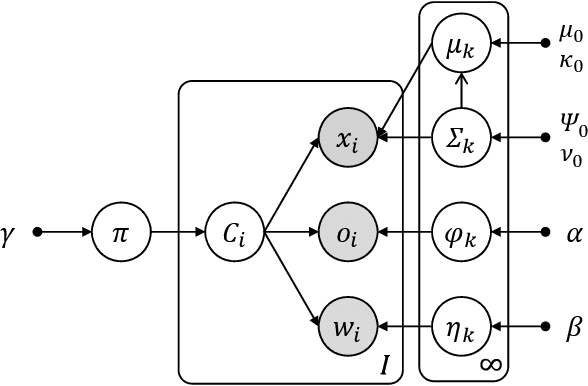
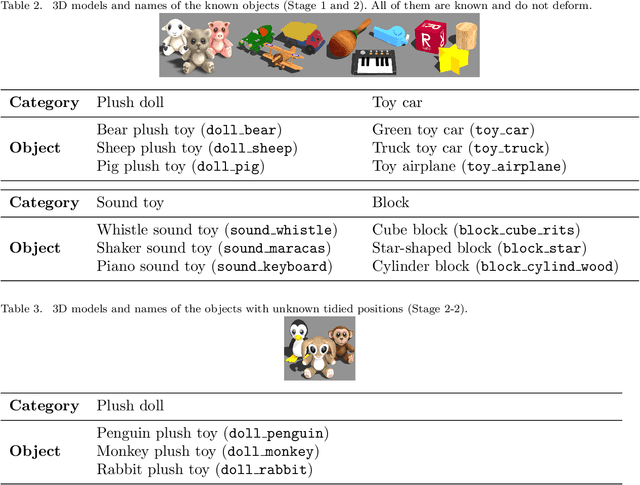
Tidy-up tasks by service robots in home environments are challenging in the application of robotics because they involve various interactions with the environment. In particular, robots are required not only to grasp, move, and release various home objects, but also plan the order and positions where to put them away. In this paper, we propose a novel planning method that can efficiently estimate the order and positions of the objects to be tidied up based on the learning of the parameters of a probabilistic generative model. The model allows the robot to learn the distributions of co-occurrence probability of objects and places to tidy up by using multimodal sensor information collected in a tidied environment. Additionally, we develop an autonomous robotic system to perform the tidy-up operation. We evaluate the effectiveness of the proposed method in an experimental simulation that reproduces the conditions of the Tidy Up Here task of the World Robot Summit international robotics competition. The simulation results showed that the proposed method enables the robot to successively tidy up several objects and achieves the best task score compared to baseline tidy-up methods.