 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Data Barrier: Robust Few-Shot 3D Vessel Segmentation using Foundation Models
Feb 27, 2026State-of-the-art vessel segmentation methods typically require large-scale annotated datasets and suffer from severe performance degradation under domain shifts. In clinical practice, however, acquiring extensive annotations for every new scanner or protocol is unfeasible. To address this, we propose a novel framework leveraging a pre-trained Vision Foundation Model (DINOv3) adapted for volumetric vessel segmentation. We introduce a lightweight 3D Adapter for volumetric consistency, a multi-scale 3D Aggregator for hierarchical feature fusion, and Z-channel embedding to effectively bridge the gap between 2D pre-training and 3D medical modalities, enabling the model to capture continuous vascular structures from limited data. We validated our method on the TopCoW (in-domain) and Lausanne (out-of-distribution) datasets. In the extreme few-shot regime with 5 training samples, our method achieved a Dice score of 43.42%, marking a 30% relative improvement over the state-of-the-art nnU-Net (33.41%) and outperforming other Transformer-based baselines, such as SwinUNETR and UNETR, by up to 45%. Furthermore, in the out-of-distribution setting, our model demonstrated superior robustness, achieving a 50% relative improvement over nnU-Net (21.37% vs. 14.22%), which suffered from severe domain overfitting. Ablation studies confirmed that our 3D adaptation mechanism and multi-scale aggregation strategy are critical for vascular continuity and robustness. Our results suggest foundation models offer a viable cold-start solution, improving clinical reliability under data scarcity or domain shifts.
Frequency-Calibrated Membership Inference Attacks on Medical Image Diffusion Models
Jun 17, 2025The increasing use of diffusion models for image generation, especially in sensitive areas like medical imaging, has raised significant privacy concerns. Membership Inference Attack (MIA) has emerged as a potential approach to determine if a specific image was used to train a diffusion model, thus quantifying privacy risks. Existing MIA methods often rely on diffusion reconstruction errors, where member images are expected to have lower reconstruction errors than non-member images. However, applying these methods directly to medical images faces challenges. Reconstruction error is influenced by inherent image difficulty, and diffusion models struggle with high-frequency detail reconstruction. To address these issues, we propose a Frequency-Calibrated Reconstruction Error (FCRE) method for MIAs on medical image diffusion models. By focusing on reconstruction errors within a specific mid-frequency range and excluding both high-frequency (difficult to reconstruct) and low-frequency (less informative) regions, our frequency-selective approach mitigates the confounding factor of inherent image difficulty. Specifically, we analyze the reverse diffusion process, obtain the mid-frequency reconstruction error, and compute the structural similarity index score between the reconstructed and original images. Membership is determined by comparing this score to a threshold. Experiments on several medical image datasets demonstrate that our FCRE method outperforms existing MIA methods.
Symbolic integration by integrating learning models with different strengths and weaknesses
Mar 09, 2021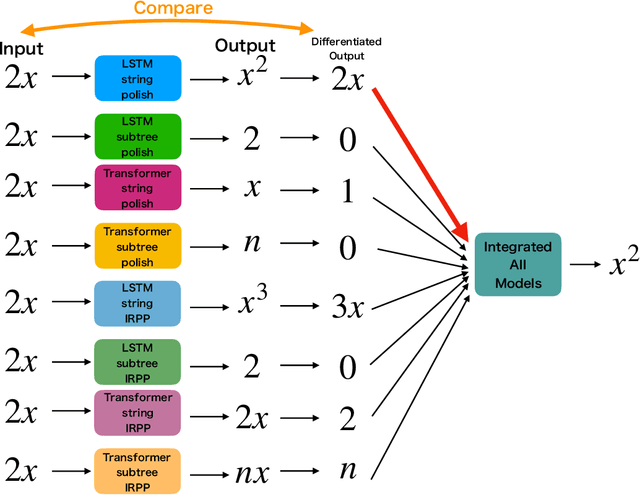
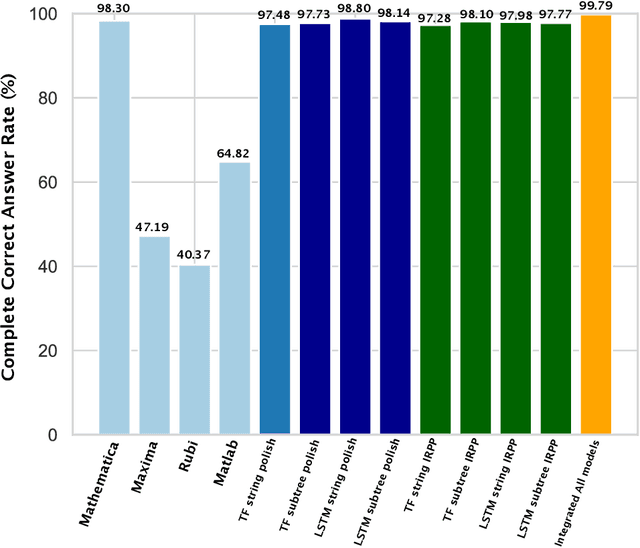
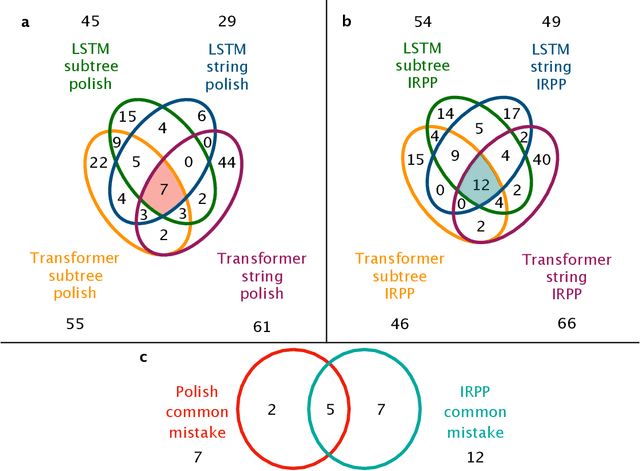
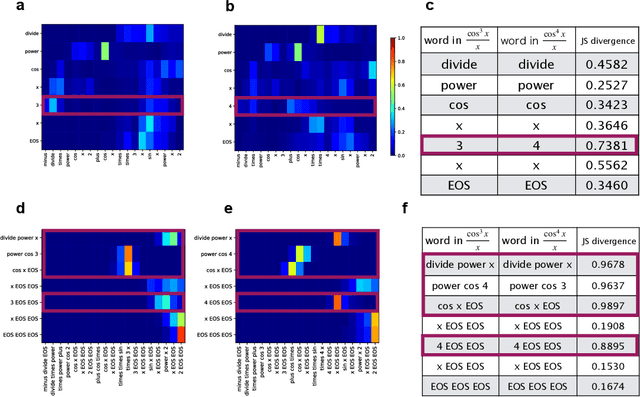
Integration is indispensable, not only in mathematics, but also in a wide range of other fields. A deep learning method has recently been developed and shown to be capable of integrating mathematical functions that could not previously be integrated on a computer. However, that method treats integration as equivalent to natural language translation and does not reflect mathematical information. In this study, we adjusted the learning model to take mathematical information into account and developed a wide range of learning models that learn the order of numerical operations more robustly. In this way, we achieved a 98.80% correct answer rate with symbolic integration, a higher rate than that of any existing method. We judged the correctness of the integration based on whether the derivative of the primitive function was consistent with the integrand. By building an integrated model based on this strategy, we achieved a 99.79% rate of correct answers with symbolic integration.
An Inductive Transfer Learning Approach using Cycle-consistent Adversarial Domain Adaptation with Application to Brain Tumor Segmentation
May 11, 2020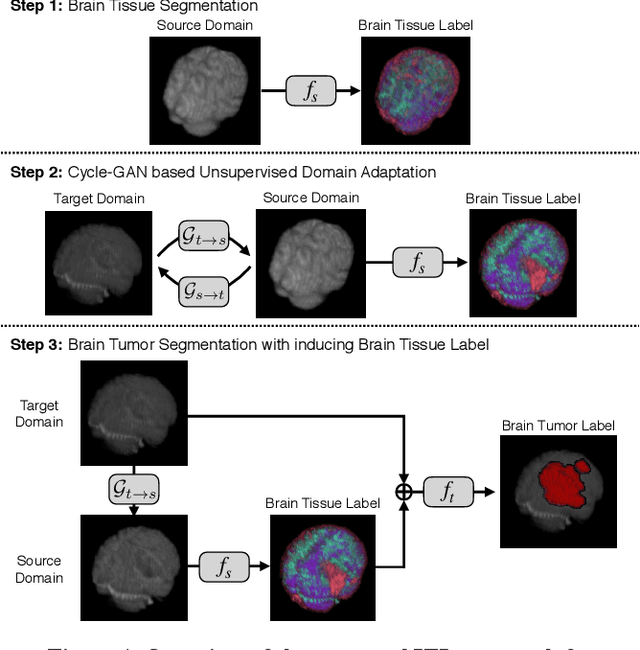
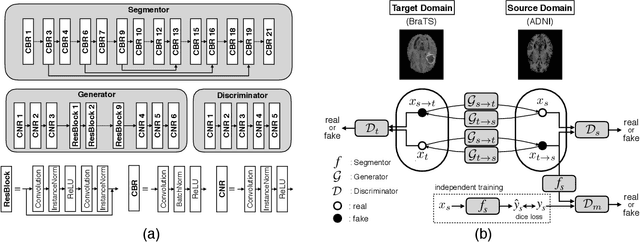
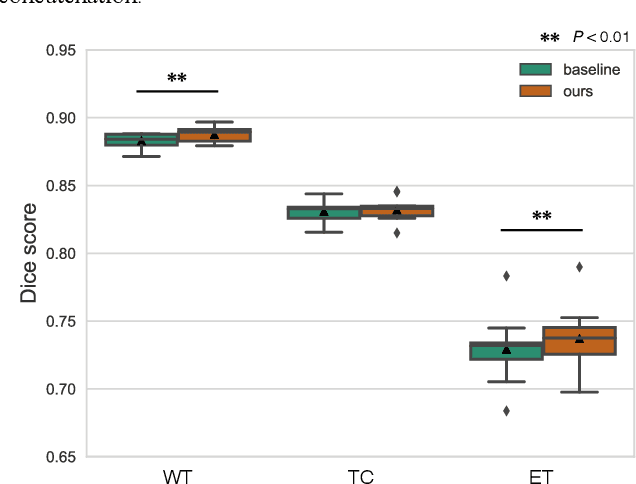
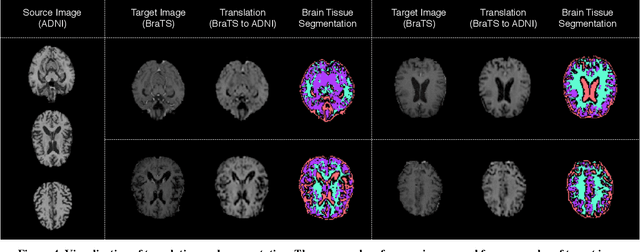
With recent advances in supervised machine learning for medical image analysis applications, the annotated medical image datasets of various domains are being shared extensively. Given that the annotation labelling requires medical expertise, such labels should be applied to as many learning tasks as possible. However, the multi-modal nature of each annotated image renders it difficult to share the annotation label among diverse tasks. In this work, we provide an inductive transfer learning (ITL) approach to adopt the annotation label of the source domain datasets to tasks of the target domain datasets using Cycle-GAN based unsupervised domain adaptation (UDA). To evaluate the applicability of the ITL approach, we adopted the brain tissue annotation label on the source domain dataset of Magnetic Resonance Imaging (MRI) images to the task of brain tumor segmentation on the target domain dataset of MRI. The results confirm that the segmentation accuracy of brain tumor segmentation improved significantly. The proposed ITL approach can make significant contribution to the field of medical image analysis, as we develop a fundamental tool to improve and promote various tasks using medical images.