 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS: Open Suturing Skills Vision-Based Assessment Challenge 2024-2025
May 21, 2026Achieving high levels of surgical skill through effective training is essential for optimal patient outcomes. Automated, data-driven skill assessment holds significant potential to improve surgical training. While machine learning-based methods are increasingly popular for assessing skills in minimally invasive surgery, their application to open surgery remains limited. We present the results of a dedicated MICCAI challenge designed to benchmark and advance vision-based skill assessment in open surgery. The challenge dataset comprises videos of an open suturing training task recorded with a static GoPro camera in a dry-lab setting, with instrument trajectories available in addition to the primary video modality. The OSS Challenge was hosted over two consecutive years, comprising two and three independent tasks, respectively: (1) classifying skill level into four classes, (2) predicting the full Objective Structured Assessment of Technical Skills across eight categories, and (3) tracking hands and surgical tools. Participants submitted diverse solutions including deep learning-based video models, tracking-driven methods, and hybrid approaches. General-purpose spatiotemporal video models consistently achieved the strongest performance, though conceptually diverse approaches reached competitive levels when well-executed. Predicting fine-grained OSATS scores remains challenging but benefits substantially from increased training data. Keypoint tracking proves difficult given frequent occlusions and out-of-frame instances, limiting current applicability for motion-based skill analysis. This work benchmarks innovative and diverse solutions for surgical skill assessment, highlighting both the promise and current limitations of video-based evaluation in open surgery and identifying critical directions for advancing automated skill assessment toward clinical impact.
Frequency-Calibrated Membership Inference Attacks on Medical Image Diffusion Models
Jun 17, 2025The increasing use of diffusion models for image generation, especially in sensitive areas like medical imaging, has raised significant privacy concerns. Membership Inference Attack (MIA) has emerged as a potential approach to determine if a specific image was used to train a diffusion model, thus quantifying privacy risks. Existing MIA methods often rely on diffusion reconstruction errors, where member images are expected to have lower reconstruction errors than non-member images. However, applying these methods directly to medical images faces challenges. Reconstruction error is influenced by inherent image difficulty, and diffusion models struggle with high-frequency detail reconstruction. To address these issues, we propose a Frequency-Calibrated Reconstruction Error (FCRE) method for MIAs on medical image diffusion models. By focusing on reconstruction errors within a specific mid-frequency range and excluding both high-frequency (difficult to reconstruct) and low-frequency (less informative) regions, our frequency-selective approach mitigates the confounding factor of inherent image difficulty. Specifically, we analyze the reverse diffusion process, obtain the mid-frequency reconstruction error, and compute the structural similarity index score between the reconstructed and original images. Membership is determined by comparing this score to a threshold. Experiments on several medical image datasets demonstrate that our FCRE method outperforms existing MIA methods.
Cross-level Contrastive Learning and Consistency Constraint for Semi-supervised Medical Image Segmentation
Feb 13, 2022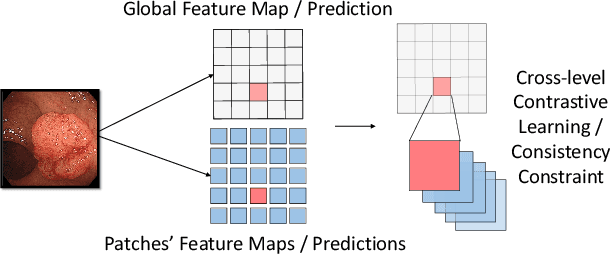
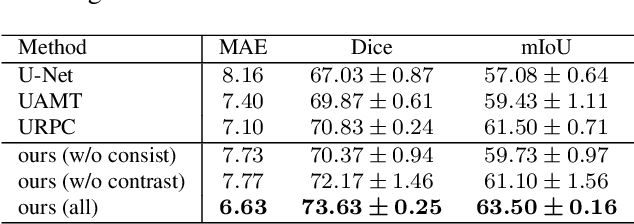
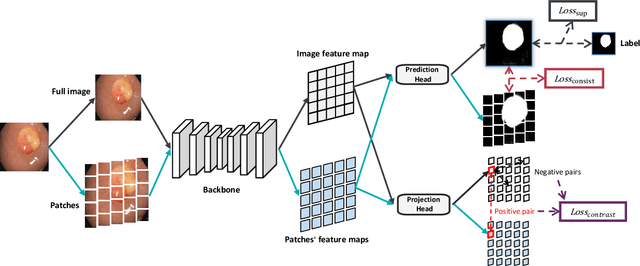
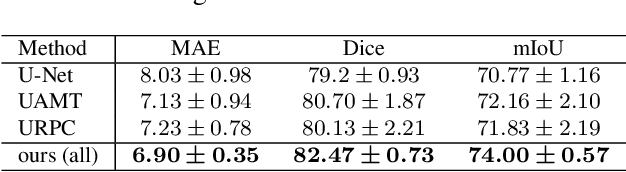
Semi-supervised learning (SSL), which aims at leveraging a few labeled images and a large number of unlabeled images for network training, is beneficial for relieving the burden of data annotation in medical image segmentation. According to the experience of medical imaging experts, local attributes such as texture, luster and smoothness are very important factors for identifying target objects like lesions and polyps in medical images. Motivated by this, we propose a cross-level contrastive learning scheme to enhance representation capacity for local features in semi-supervised medical image segmentation. Compared to existing image-wise, patch-wise and point-wise contrastive learning algorithms, our devised method is capable of exploring more complex similarity cues, namely the relational characteristics between global and local patch-wise representations. Additionally, for fully making use of cross-level semantic relations, we devise a novel consistency constraint that compares the predictions of patches against those of the full image. With the help of the cross-level contrastive learning and consistency constraint, the unlabelled data can be effectively explored to improve segmentation performance on two medical image datasets for polyp and skin lesion segmentation respectively. Code of our approach is available.
Deep Transformers for Fast Small Intestine Grounding in Capsule Endoscope Video
Apr 07, 2021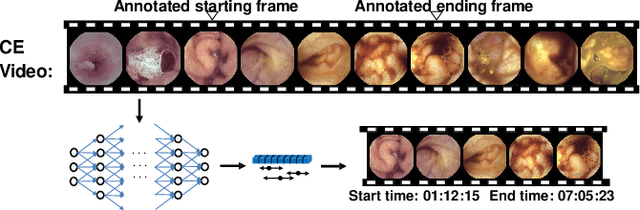
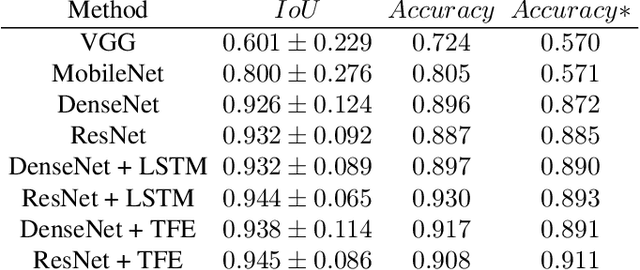
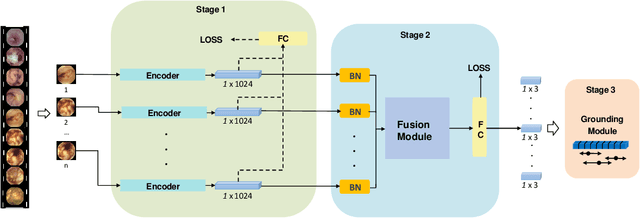
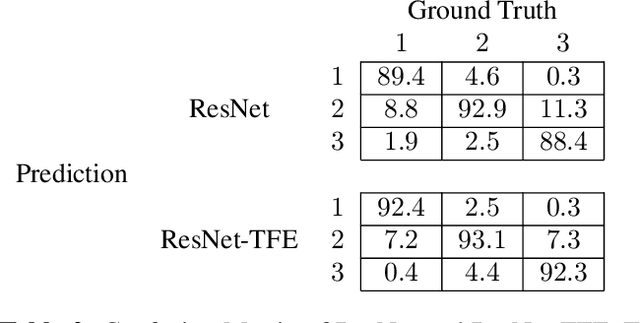
Capsule endoscopy is an evolutional technique for examining and diagnosing intractable gastrointestinal diseases. Because of the huge amount of data, analyzing capsule endoscope videos is very time-consuming and labor-intensive for gastrointestinal medicalists. The development of intelligent long video analysis algorithms for regional positioning and analysis of capsule endoscopic video is therefore essential to reduce the workload of clinicians and assist in improving the accuracy of disease diagnosis. In this paper, we propose a deep model to ground shooting range of small intestine from a capsule endoscope video which has duration of tens of hours. This is the first attempt to attack the small intestine grounding task using deep neural network method. We model the task as a 3-way classification problem, in which every video frame is categorized into esophagus/stomach, small intestine or colorectum. To explore long-range temporal dependency, a transformer module is built to fuse features of multiple neighboring frames. Based on the classification model, we devise an efficient search algorithm to efficiently locate the starting and ending shooting boundaries of the small intestine. Without searching the small intestine exhaustively in the full video, our method is implemented via iteratively separating the video segment along the direction to the target boundary in the middle. We collect 113 videos from a local hospital to validate our method. In the 5-fold cross validation, the average IoU between the small intestine segments located by our method and the ground-truths annotated by broad-certificated gastroenterologists reaches 0.945.