 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Transformers for Fast Small Intestine Grounding in Capsule Endoscope Video
Paper and Code
Apr 07, 2021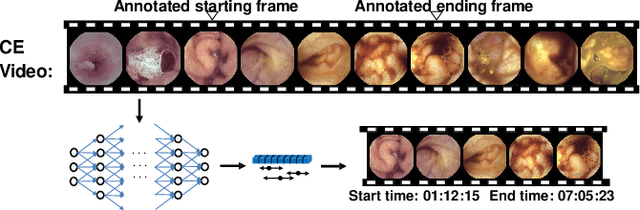
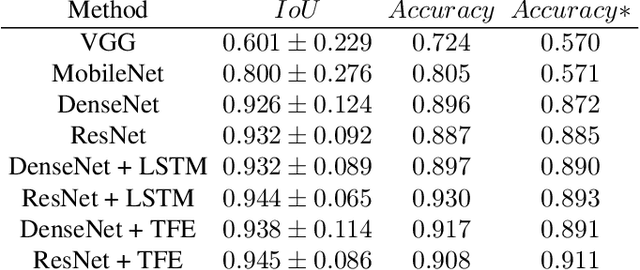
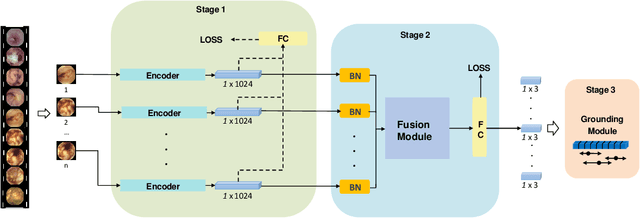
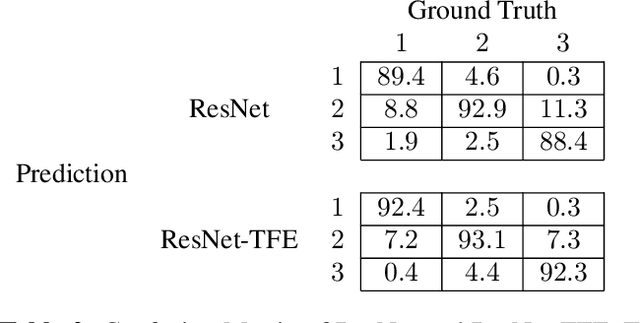
Capsule endoscopy is an evolutional technique for examining and diagnosing intractable gastrointestinal diseases. Because of the huge amount of data, analyzing capsule endoscope videos is very time-consuming and labor-intensive for gastrointestinal medicalists. The development of intelligent long video analysis algorithms for regional positioning and analysis of capsule endoscopic video is therefore essential to reduce the workload of clinicians and assist in improving the accuracy of disease diagnosis. In this paper, we propose a deep model to ground shooting range of small intestine from a capsule endoscope video which has duration of tens of hours. This is the first attempt to attack the small intestine grounding task using deep neural network method. We model the task as a 3-way classification problem, in which every video frame is categorized into esophagus/stomach, small intestine or colorectum. To explore long-range temporal dependency, a transformer module is built to fuse features of multiple neighboring frames. Based on the classification model, we devise an efficient search algorithm to efficiently locate the starting and ending shooting boundaries of the small intestine. Without searching the small intestine exhaustively in the full video, our method is implemented via iteratively separating the video segment along the direction to the target boundary in the middle. We collect 113 videos from a local hospital to validate our method. In the 5-fold cross validation, the average IoU between the small intestine segments located by our method and the ground-truths annotated by broad-certificated gastroenterologists reaches 0.945.