 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomical 3D Style Transfer Enabling Efficient Federated Learning with Extremely Low Communication Costs
Oct 26, 2024In this study, we propose a novel federated learning (FL) approach that utilizes 3D style transfer for the multi-organ segmentation task. The multi-organ dataset, obtained by integrating multiple datasets, has high scalability and can improve generalization performance as the data volume increases. However, the heterogeneity of data owing to different clients with diverse imaging conditions and target organs can lead to severe overfitting of local models. To align models that overfit to different local datasets, existing methods require frequent communication with the central server, resulting in higher communication costs and risk of privacy leakage. To achieve an efficient and safe FL, we propose an Anatomical 3D Frequency Domain Generalization (A3DFDG) method for FL. A3DFDG utilizes structural information of human organs and clusters the 3D styles based on the location of organs. By mixing styles based on these clusters, it preserves the anatomical information and leads models to learn intra-organ diversity, while aligning the optimization of each local model. Experiments indicate that our method can maintain its accuracy even in cases where the communication cost is highly limited (=1.25% of the original cost) while achieving a significant difference compared to baselines, with a higher global dice similarity coefficient score of 4.3%. Despite its simplicity and minimal computational overhead, these results demonstrate that our method has high practicality in real-world scenarios where low communication costs and a simple pipeline are required. The code used in this project will be publicly available.
Warp-Refine Propagation: Semi-Supervised Auto-labeling via Cycle-consistency
Sep 28, 2021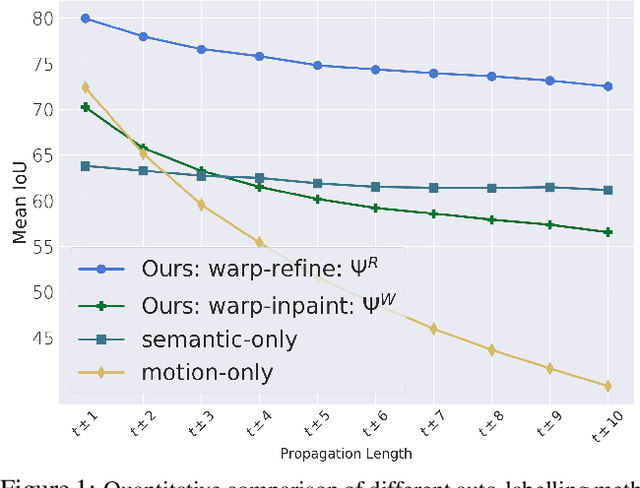
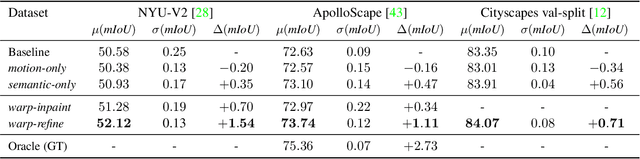
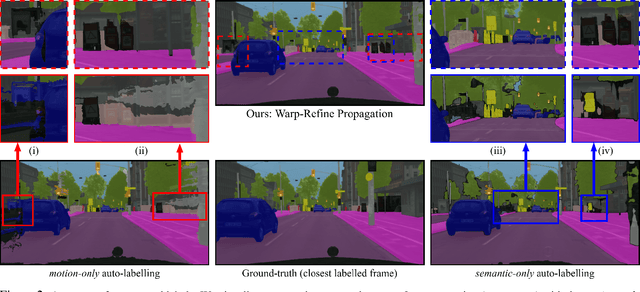

Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes.
Hierarchical Lovász Embeddings for Proposal-free Panoptic Segmentation
Jun 08, 2021
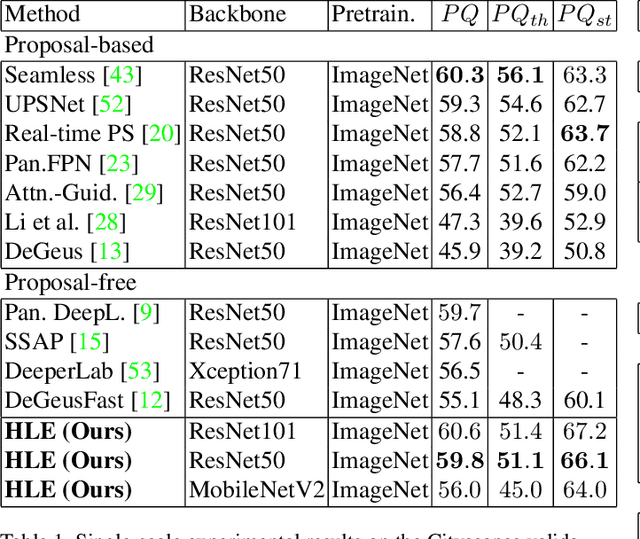
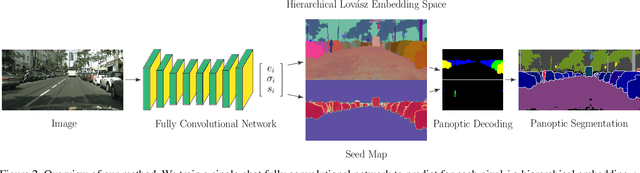

Panoptic segmentation brings together two separate tasks: instance and semantic segmentation. Although they are related, unifying them faces an apparent paradox: how to learn simultaneously instance-specific and category-specific (i.e. instance-agnostic) representations jointly. Hence, state-of-the-art panoptic segmentation methods use complex models with a distinct stream for each task. In contrast, we propose Hierarchical Lov\'asz Embeddings, per pixel feature vectors that simultaneously encode instance- and category-level discriminative information. We use a hierarchical Lov\'asz hinge loss to learn a low-dimensional embedding space structured into a unified semantic and instance hierarchy without requiring separate network branches or object proposals. Besides modeling instances precisely in a proposal-free manner, our Hierarchical Lov\'asz Embeddings generalize to categories by using a simple Nearest-Class-Mean classifier, including for non-instance "stuff" classes where instance segmentation methods are not applicable. Our simple model achieves state-of-the-art results compared to existing proposal-free panoptic segmentation methods on Cityscapes, COCO, and Mapillary Vistas. Furthermore, our model demonstrates temporal stability between video frames.
Unsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations
Mar 22, 2018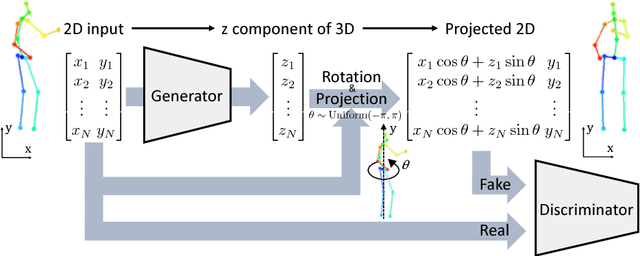


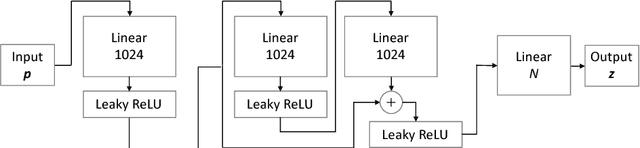
The task of three-dimensional (3D) human pose estimation from a single image can be divided into two parts: (1) Two-dimensional (2D) human joint detection from the image and (2) estimating a 3D pose from the 2D joints. Herein, we focus on the second part, i.e., a 3D pose estimation from 2D joint locations. The problem with existing methods is that they require either (1) a 3D pose dataset or (2) 2D joint locations in consecutive frames taken from a video sequence. We aim to solve these problems. For the first time, we propose a method that learns a 3D human pose without any 3D datasets. Our method can predict a 3D pose from 2D joint locations in a single image. Our system is based on the generative adversarial networks, and the networks are trained in an unsupervised manner. Our primary idea is that, if the network can predict a 3D human pose correctly, the 3D pose that is projected onto a 2D plane should not collapse even if it is rotated perpendicularly. We evaluated the performance of our method using Human3.6M and the MPII dataset and showed that our network can predict a 3D pose well even if the 3D dataset is not available during training.