 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Probabilistic Image Colorization
Sep 29, 2021
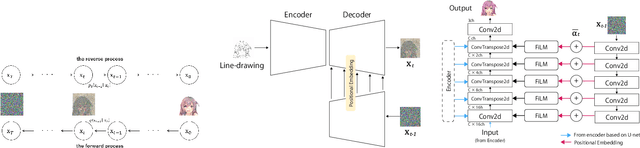
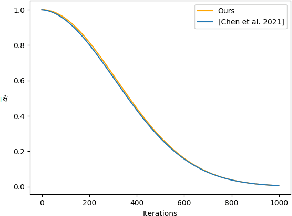
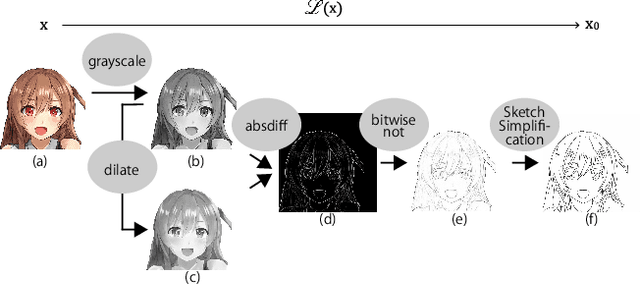
We propose Generative Probabilistic Image Colorization, a diffusion-based generative process that trains a sequence of probabilistic models to reverse each step of noise corruption. Given a line-drawing image as input, our method suggests multiple candidate colorized images. Therefore, our method accounts for the ill-posed nature of the colorization problem. We conducted comprehensive experiments investigating the colorization of line-drawing images, report the influence of a score-based MCMC approach that corrects the marginal distribution of estimated samples, and further compare different combinations of models and the similarity of their generated images. Despite using only a relatively small training dataset, we experimentally develop a method to generate multiple diverse colorization candidates which avoids mode collapse and does not require any additional constraints, losses, or re-training with alternative training conditions. Our proposed approach performed well not only on color-conditional image generation tasks using biased initial values, but also on some practical image completion and inpainting tasks.
Unsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations
Mar 22, 2018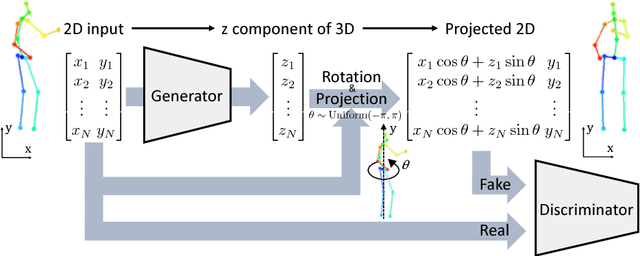


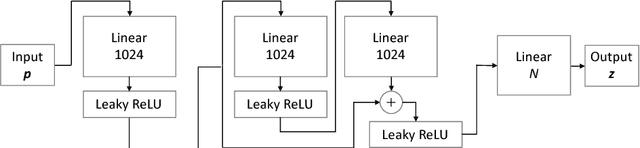
The task of three-dimensional (3D) human pose estimation from a single image can be divided into two parts: (1) Two-dimensional (2D) human joint detection from the image and (2) estimating a 3D pose from the 2D joints. Herein, we focus on the second part, i.e., a 3D pose estimation from 2D joint locations. The problem with existing methods is that they require either (1) a 3D pose dataset or (2) 2D joint locations in consecutive frames taken from a video sequence. We aim to solve these problems. For the first time, we propose a method that learns a 3D human pose without any 3D datasets. Our method can predict a 3D pose from 2D joint locations in a single image. Our system is based on the generative adversarial networks, and the networks are trained in an unsupervised manner. Our primary idea is that, if the network can predict a 3D human pose correctly, the 3D pose that is projected onto a 2D plane should not collapse even if it is rotated perpendicularly. We evaluated the performance of our method using Human3.6M and the MPII dataset and showed that our network can predict a 3D pose well even if the 3D dataset is not available during training.
Comicolorization: Semi-Automatic Manga Colorization
Sep 28, 2017
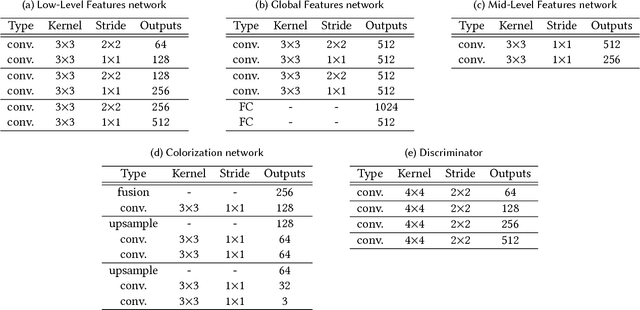

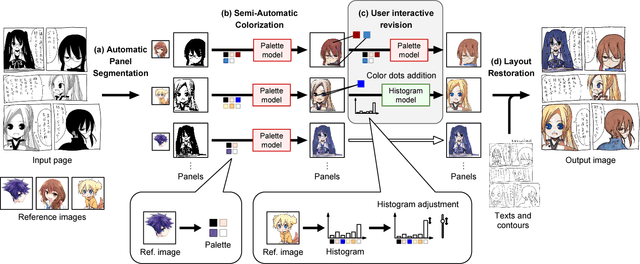
We developed "Comicolorization", a semi-automatic colorization system for manga images. Given a monochrome manga and reference images as inputs, our system generates a plausible color version of the manga. This is the first work to address the colorization of an entire manga title (a set of manga pages). Our method colorizes a whole page (not a single panel) semi-automatically, with the same color for the same character across multiple panels. To colorize the target character by the color from the reference image, we extract a color feature from the reference and feed it to the colorization network to help the colorization. Our approach employs adversarial loss to encourage the effect of the color features. Optionally, our tool allows users to revise the colorization result interactively. By feeding the color features to our deep colorization network, we accomplish colorization of the entire manga using the desired colors for each panel.