 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations
Paper and Code
Mar 22, 2018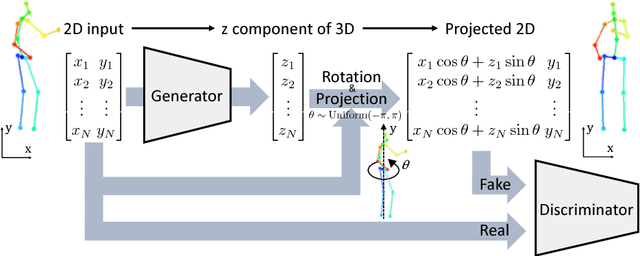


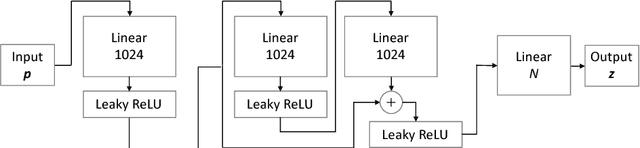
The task of three-dimensional (3D) human pose estimation from a single image can be divided into two parts: (1) Two-dimensional (2D) human joint detection from the image and (2) estimating a 3D pose from the 2D joints. Herein, we focus on the second part, i.e., a 3D pose estimation from 2D joint locations. The problem with existing methods is that they require either (1) a 3D pose dataset or (2) 2D joint locations in consecutive frames taken from a video sequence. We aim to solve these problems. For the first time, we propose a method that learns a 3D human pose without any 3D datasets. Our method can predict a 3D pose from 2D joint locations in a single image. Our system is based on the generative adversarial networks, and the networks are trained in an unsupervised manner. Our primary idea is that, if the network can predict a 3D human pose correctly, the 3D pose that is projected onto a 2D plane should not collapse even if it is rotated perpendicularly. We evaluated the performance of our method using Human3.6M and the MPII dataset and showed that our network can predict a 3D pose well even if the 3D dataset is not available during training.