 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Cross-domain Generative Models applied to Cartoon Series
Paper and Code
Sep 29, 2017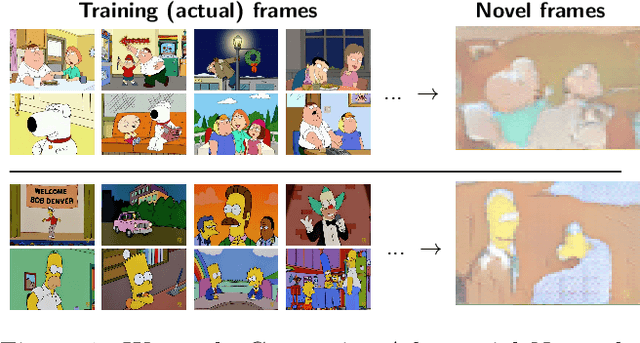



We investigate Generative Adversarial Networks (GANs) to model one particular kind of image: frames from TV cartoons. Cartoons are particularly interesting because their visual appearance emphasizes the important semantic information about a scene while abstracting out the less important details, but each cartoon series has a distinctive artistic style that performs this abstraction in different ways. We consider a dataset consisting of images from two popular television cartoon series, Family Guy and The Simpsons. We examine the ability of GANs to generate images from each of these two domains, when trained independently as well as on both domains jointly. We find that generative models may be capable of finding semantic-level correspondences between these two image domains despite the unsupervised setting, even when the training data does not give labeled alignments between them.