 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Paper and Code
Oct 04, 2022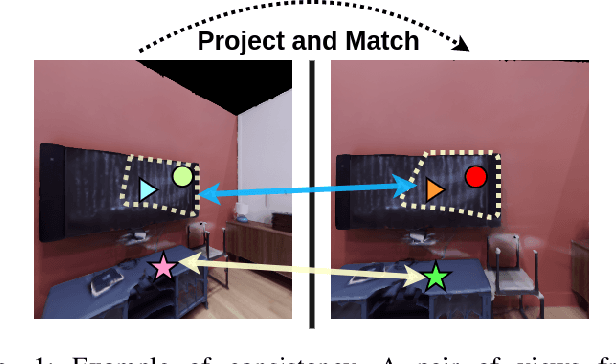
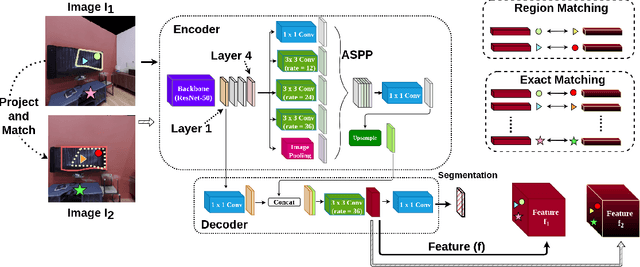

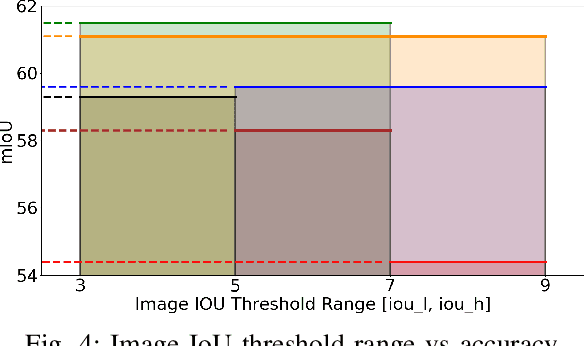
The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.