 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreet-Level AI: Are Large Language Models Ready for Real-World Judgments?
Aug 11, 2025A surge of recent work explores the ethical and societal implications of large-scale AI models that make "moral" judgments. Much of this literature focuses either on alignment with human judgments through various thought experiments or on the group fairness implications of AI judgments. However, the most immediate and likely use of AI is to help or fully replace the so-called street-level bureaucrats, the individuals deciding to allocate scarce social resources or approve benefits. There is a rich history underlying how principles of local justice determine how society decides on prioritization mechanisms in such domains. In this paper, we examine how well LLM judgments align with human judgments, as well as with socially and politically determined vulnerability scoring systems currently used in the domain of homelessness resource allocation. Crucially, we use real data on those needing services (maintaining strict confidentiality by only using local large models) to perform our analyses. We find that LLM prioritizations are extremely inconsistent in several ways: internally on different runs, between different LLMs, and between LLMs and the vulnerability scoring systems. At the same time, LLMs demonstrate qualitative consistency with lay human judgments in pairwise testing. Findings call into question the readiness of current generation AI systems for naive integration in high-stakes societal decision-making.
A Survey of Multimodal Sarcasm Detection
Oct 24, 2024



Sarcasm is a rhetorical device that is used to convey the opposite of the literal meaning of an utterance. Sarcasm is widely used on social media and other forms of computer-mediated communication motivating the use of computational models to identify it automatically. While the clear majority of approaches to sarcasm detection have been carried out on text only, sarcasm detection often requires additional information present in tonality, facial expression, and contextual images. This has led to the introduction of multimodal models, opening the possibility to detect sarcasm in multiple modalities such as audio, images, text, and video. In this paper, we present the first comprehensive survey on multimodal sarcasm detection - henceforth MSD - to date. We survey papers published between 2018 and 2023 on the topic, and discuss the models and datasets used for this task. We also present future research directions in MSD.
Improving Action Quality Assessment using ResNets and Weighted Aggregation
Feb 21, 2021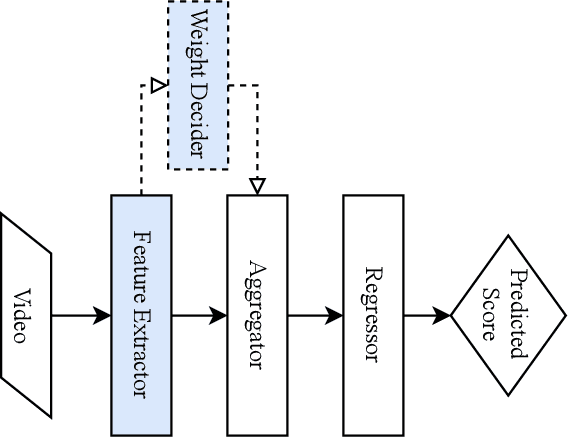
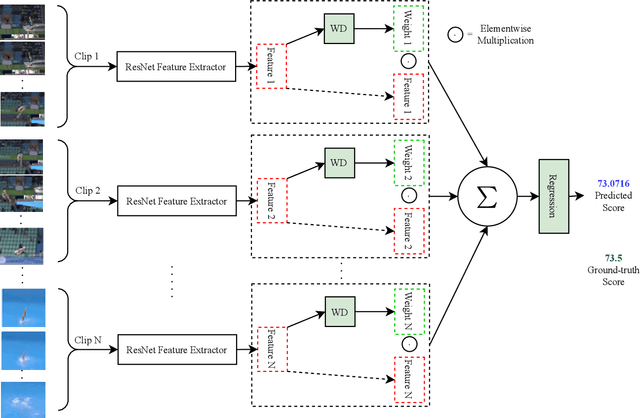
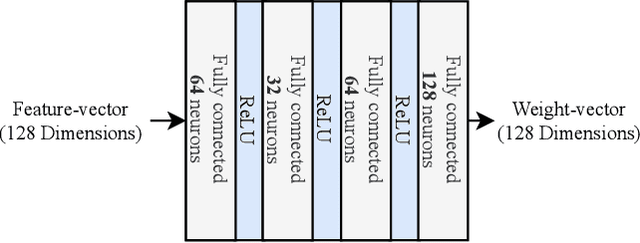
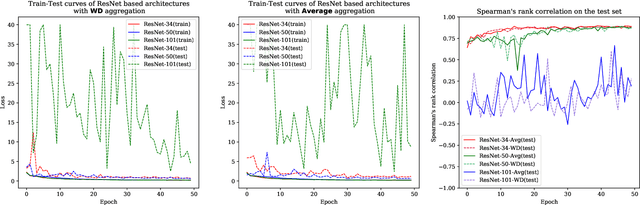
Action quality assessment (AQA) aims at automatically judging human action based on a video of the said action and assigning a performance score to it. The majority of works in the existing literature on AQA transform RGB videos to higher-level representations using C3D networks. These higher-level representations are used to perform action quality assessment. Due to the relatively shallow nature of C3D, the quality of extracted features is lower than what could be extracted using a deeper convolutional neural network. In this paper, we experiment with deeper convolutional neural networks with residual connections for learning representations for action quality assessment. We assess the effects of the depth and the input clip size of the convolutional neural network on the quality of action score predictions. We also look at the effect of using (2+1)D convolutions instead of 3D convolutions for feature extraction. We find that the current clip level feature representation aggregation technique of averaging is insufficient to capture the relative importance of features. To overcome this, we propose a learning-based weighted-averaging technique that can perform better. We achieve a new state-of-the-art Spearman's rank correlation of 0.9315 (an increase of 0.45%) on the MTL-AQA dataset using a 34 layer (2+1)D convolutional neural network with the capability of processing 32 frame clips, using our proposed aggregation technique.