 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Action Quality Assessment using ResNets and Weighted Aggregation
Paper and Code
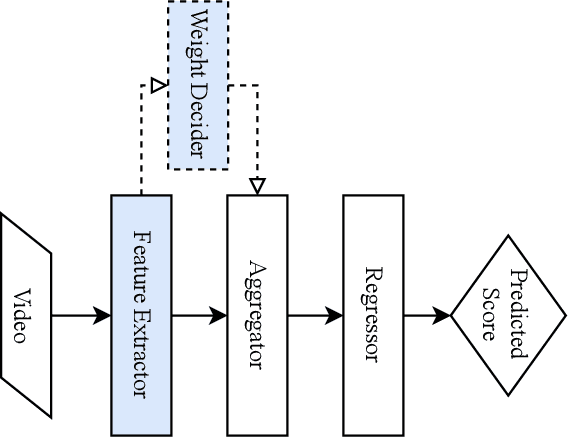
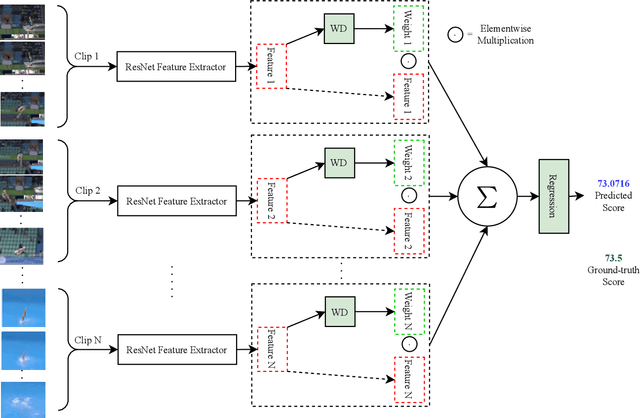
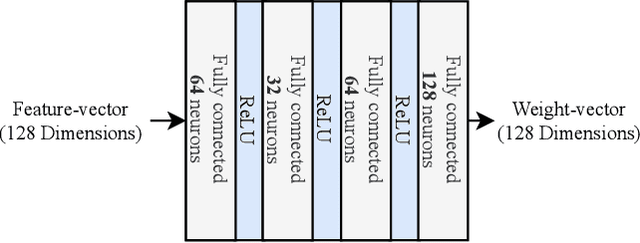
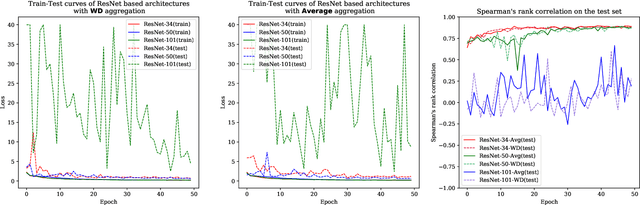
Action quality assessment (AQA) aims at automatically judging human action based on a video of the said action and assigning a performance score to it. The majority of works in the existing literature on AQA transform RGB videos to higher-level representations using C3D networks. These higher-level representations are used to perform action quality assessment. Due to the relatively shallow nature of C3D, the quality of extracted features is lower than what could be extracted using a deeper convolutional neural network. In this paper, we experiment with deeper convolutional neural networks with residual connections for learning representations for action quality assessment. We assess the effects of the depth and the input clip size of the convolutional neural network on the quality of action score predictions. We also look at the effect of using (2+1)D convolutions instead of 3D convolutions for feature extraction. We find that the current clip level feature representation aggregation technique of averaging is insufficient to capture the relative importance of features. To overcome this, we propose a learning-based weighted-averaging technique that can perform better. We achieve a new state-of-the-art Spearman's rank correlation of 0.9315 (an increase of 0.45%) on the MTL-AQA dataset using a 34 layer (2+1)D convolutional neural network with the capability of processing 32 frame clips, using our proposed aggregation technique.