 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Disinfection using Ultraviolet Lightwith a Mobile Manipulation Robot
Apr 21, 2021



Robots are being increasingly used in the fight against highly-infectious diseases such as Ebola, MERS, and SARS-COV-2. Many of the robots that are being used employ ultraviolet lights mounted on a mobile base to inactivate the pathogens. However, these lights are often mounted in a fixed configuration and do not provide adequate decontamination of horizontal surfaces, which can be a major source of cross-contamination. In the paper, we describe the design, implementation, and testing of an Ultraviolet Germicidal Irradiation (UVGI) system implemented on a mobile manipulation robot. A human supervisor designates a surface for disinfection, the robot autonomously plans and executes an end-effector trajectory to disinfect the surface to the required certainty, and then displays the results for the human supervisor to verify. We also provide some background information on UVGI and describe how we constructed and validated mathematical models of Ultraviolet (UV) radiation propagation and accumulation. Finally, we describe our implementation on a Fetch mobile manipulation platform, and discuss how the practicalities of implementation on a real robot affect our models.
Framing Effects on Privacy Concerns about a Home Telepresence Robot
Nov 12, 2019
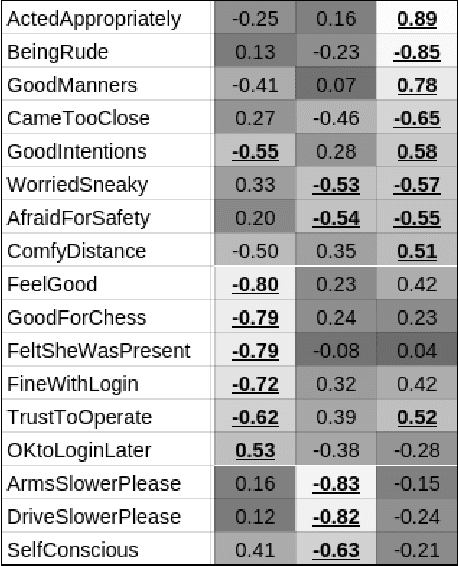
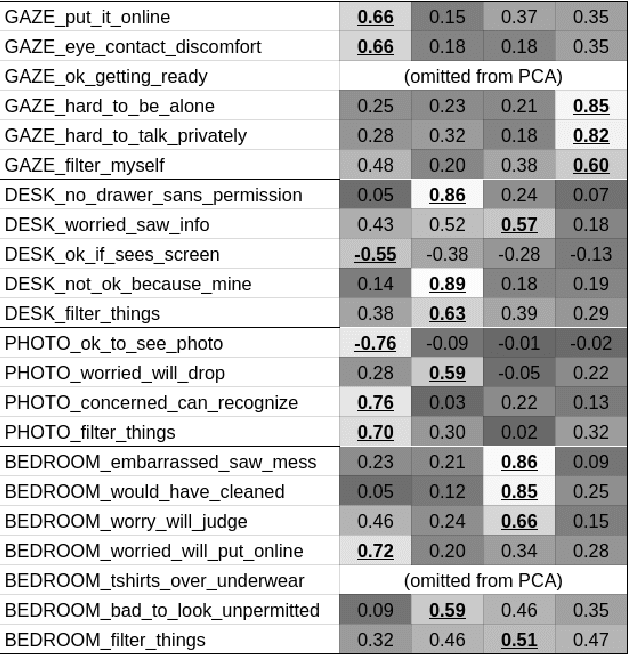
Privacy-sensitive robotics is an emerging area of HRI research. Judgments about privacy would seem to be context-dependent, but none of the promising work on contextual "frames" has focused on privacy concerns. This work studies the impact of contextual "frames" on local users' privacy judgments in a home telepresence setting. Our methodology consists of using an online questionnaire to collect responses to animated videos of a telepresence robot after framing people with an introductory paragraph. The results of four studies indicate a large effect of manipulating the robot operator's identity between a stranger and a close confidante. It also appears that this framing effect persists throughout several videos. These findings serve to caution HRI researchers that a change in frame could cause their results to fail to replicate or generalize. We also recommend that robots be designed to encourage or discourage certain frames.
A Critical Look at Smart Wheelchairs
Sep 02, 2018Research into smart wheelchairs has been conducted for decades, but we have yet to see the widespread use of this technology among full-time wheelchair users. We argue that the main reason for this is that there is a mismatch between research and the actualities of using a powered mobility device in the real world. Based on our own research experiences, we enumerate some of these disparities, and offer some suggestions for where work in smart wheelchairs might focus in the coming years.
A Taxonomy of Privacy Constructs for Privacy-Sensitive Robotics
Jan 03, 2017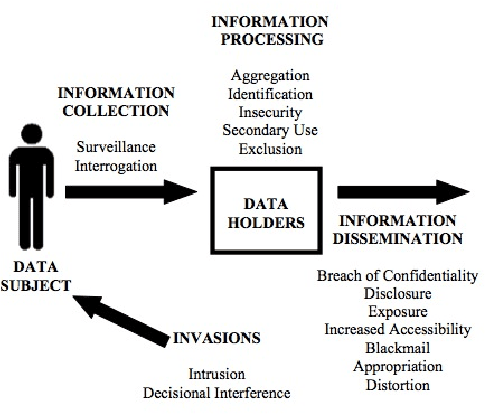
The introduction of robots into our society will also introduce new concerns about personal privacy. In order to study these concerns, we must do human-subject experiments that involve measuring privacy-relevant constructs. This paper presents a taxonomy of privacy constructs based on a review of the privacy literature. Future work in operationalizing privacy constructs for HRI studies is also discussed.
Video Manipulation Techniques for the Protection of Privacy in Remote Presence Systems
Jan 13, 2015

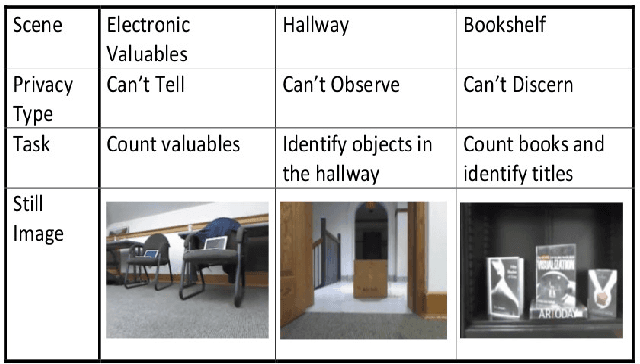
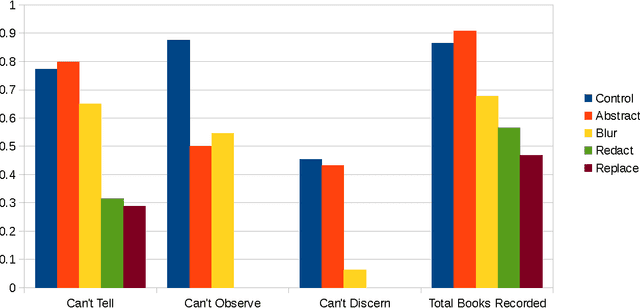
Systems that give control of a mobile robot to a remote user raise privacy concerns about what the remote user can see and do through the robot. We aim to preserve some of that privacy by manipulating the video data that the remote user sees. Through two user studies, we explore the effectiveness of different video manipulation techniques at providing different types of privacy. We simultaneously examine task performance in the presence of privacy protection. In the first study, participants were asked to watch a video captured by a robot exploring an office environment and to complete a series of observational tasks under differing video manipulation conditions. Our results show that using manipulations of the video stream can lead to fewer privacy violations for different privacy types. Through a second user study, it was demonstrated that these privacy-protecting techniques were effective without diminishing the task performance of the remote user.
Real-Time Scheduling via Reinforcement Learning
Mar 15, 2012
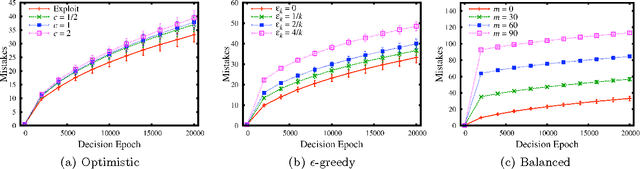
Cyber-physical systems, such as mobile robots, must respond adaptively to dynamic operating conditions. Effective operation of these systems requires that sensing and actuation tasks are performed in a timely manner. Additionally, execution of mission specific tasks such as imaging a room must be balanced against the need to perform more general tasks such as obstacle avoidance. This problem has been addressed by maintaining relative utilization of shared resources among tasks near a user-specified target level. Producing optimal scheduling strategies requires complete prior knowledge of task behavior, which is unlikely to be available in practice. Instead, suitable scheduling strategies must be learned online through interaction with the system. We consider the sample complexity of reinforcement learning in this domain, and demonstrate that while the problem state space is countably infinite, we may leverage the problem's structure to guarantee efficient learning.
A Scalable Method for Solving High-Dimensional Continuous POMDPs Using Local Approximation
Mar 15, 2012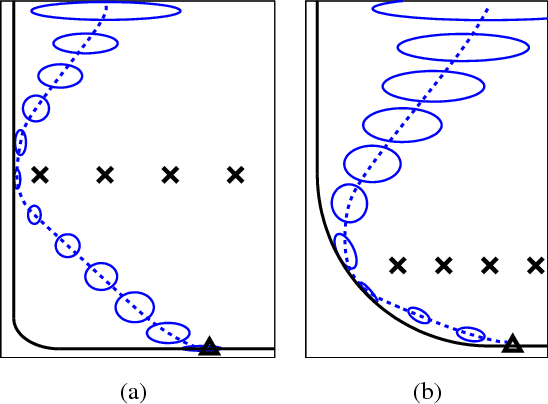
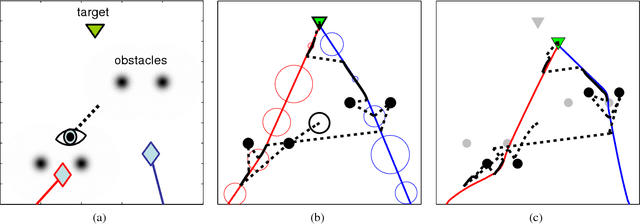
Partially-Observable Markov Decision Processes (POMDPs) are typically solved by finding an approximate global solution to a corresponding belief-MDP. In this paper, we offer a new planning algorithm for POMDPs with continuous state, action and observation spaces. Since such domains have an inherent notion of locality, we can find an approximate solution using local optimization methods. We parameterize the belief distribution as a Gaussian mixture, and use the Extended Kalman Filter (EKF) to approximate the belief update. Since the EKF is a first-order filter, we can marginalize over the observations analytically. By using feedback control and state estimation during policy execution, we recover a behavior that is effectively conditioned on incoming observations despite the unconditioned planning. Local optimization provides no guarantees of global optimality, but it allows us to tackle domains that are at least an order of magnitude larger than the current state-of-the-art. We demonstrate the scalability of our algorithm by considering a simulated hand-eye coordination domain with 16 continuous state dimensions and 6 continuous action dimensions.