 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Method for Solving High-Dimensional Continuous POMDPs Using Local Approximation
Paper and Code
Mar 15, 2012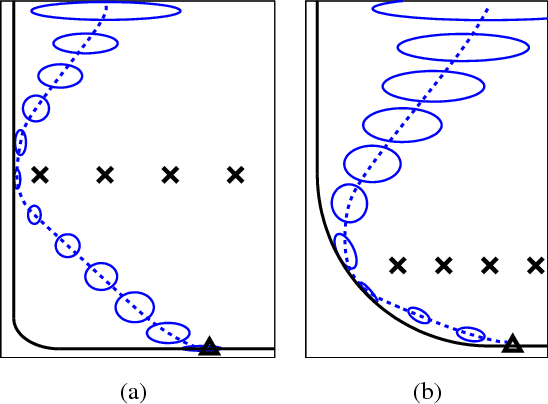
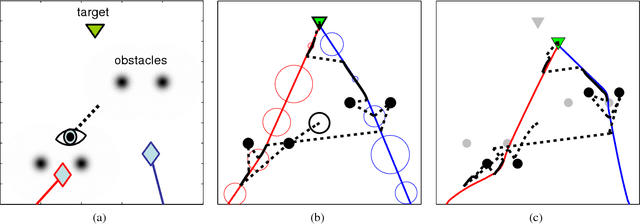
Partially-Observable Markov Decision Processes (POMDPs) are typically solved by finding an approximate global solution to a corresponding belief-MDP. In this paper, we offer a new planning algorithm for POMDPs with continuous state, action and observation spaces. Since such domains have an inherent notion of locality, we can find an approximate solution using local optimization methods. We parameterize the belief distribution as a Gaussian mixture, and use the Extended Kalman Filter (EKF) to approximate the belief update. Since the EKF is a first-order filter, we can marginalize over the observations analytically. By using feedback control and state estimation during policy execution, we recover a behavior that is effectively conditioned on incoming observations despite the unconditioned planning. Local optimization provides no guarantees of global optimality, but it allows us to tackle domains that are at least an order of magnitude larger than the current state-of-the-art. We demonstrate the scalability of our algorithm by considering a simulated hand-eye coordination domain with 16 continuous state dimensions and 6 continuous action dimensions.