 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient Selection for Federated Policy Optimization with Environment Heterogeneity
Paper and Code
May 24, 2023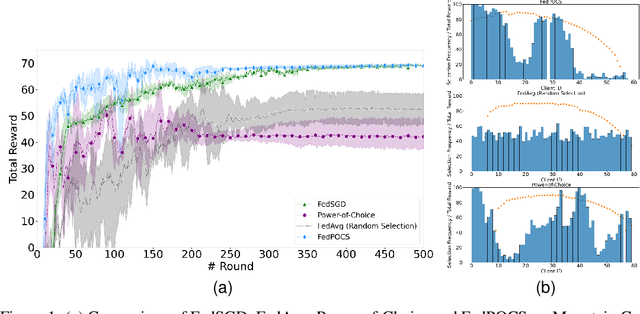
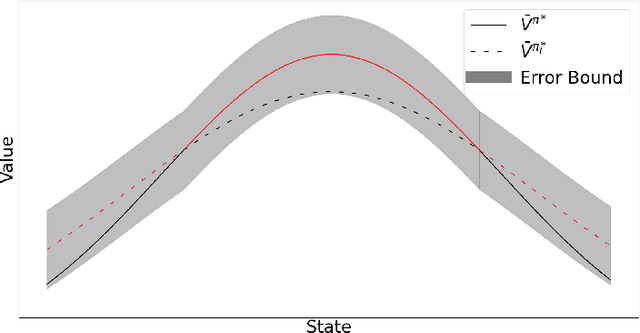
The development of Policy Iteration (PI) has inspired many recent algorithms for Reinforcement Learning (RL), including several policy gradient methods, that gained both theoretical soundness and empirical success on a variety of tasks. The theory of PI is rich in the context of centralized learning, but its study is still in the infant stage under the federated setting. This paper explores the federated version of Approximate PI (API) and derives its error bound, taking into account the approximation error introduced by environment heterogeneity. We theoretically prove that a proper client selection scheme can reduce this error bound. Based on the theoretical result, we propose a client selection algorithm to alleviate the additional approximation error caused by environment heterogeneity. Experiment results show that the proposed algorithm outperforms other biased and unbiased client selection methods on the federated mountain car problem by effectively selecting clients with a lower level of heterogeneity from the population distribution.