 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Matching Data Synthesis for Non-IID Federated Learning
Aug 09, 2023Federated learning (FL) has emerged as a privacy-preserving paradigm that trains neural networks on edge devices without collecting data at a central server. However, FL encounters an inherent challenge in dealing with non-independent and identically distributed (non-IID) data among devices. To address this challenge, this paper proposes a hard feature matching data synthesis (HFMDS) method to share auxiliary data besides local models. Specifically, synthetic data are generated by learning the essential class-relevant features of real samples and discarding the redundant features, which helps to effectively tackle the non-IID issue. For better privacy preservation, we propose a hard feature augmentation method to transfer real features towards the decision boundary, with which the synthetic data not only improve the model generalization but also erase the information of real features. By integrating the proposed HFMDS method with FL, we present a novel FL framework with data augmentation to relieve data heterogeneity. The theoretical analysis highlights the effectiveness of our proposed data synthesis method in solving the non-IID challenge. Simulation results further demonstrate that our proposed HFMDS-FL algorithm outperforms the baselines in terms of accuracy, privacy preservation, and computational cost on various benchmark datasets.
pFedSim: Similarity-Aware Model Aggregation Towards Personalized Federated Learning
May 25, 2023The federated learning (FL) paradigm emerges to preserve data privacy during model training by only exposing clients' model parameters rather than original data. One of the biggest challenges in FL lies in the non-IID (not identical and independently distributed) data (a.k.a., data heterogeneity) distributed on clients. To address this challenge, various personalized FL (pFL) methods are proposed such as similarity-based aggregation and model decoupling. The former one aggregates models from clients of a similar data distribution. The later one decouples a neural network (NN) model into a feature extractor and a classifier. Personalization is captured by classifiers which are obtained by local training. To advance pFL, we propose a novel pFedSim (pFL based on model similarity) algorithm in this work by combining these two kinds of methods. More specifically, we decouple a NN model into a personalized feature extractor, obtained by aggregating models from similar clients, and a classifier, which is obtained by local training and used to estimate client similarity. Compared with the state-of-the-art baselines, the advantages of pFedSim include: 1) significantly improved model accuracy; 2) low communication and computation overhead; 3) a low risk of privacy leakage; 4) no requirement for any external public information. To demonstrate the superiority of pFedSim, extensive experiments are conducted on real datasets. The results validate the superb performance of our algorithm which can significantly outperform baselines under various heterogeneous data settings.
Federated Learning with GAN-based Data Synthesis for Non-IID Clients
Jun 11, 2022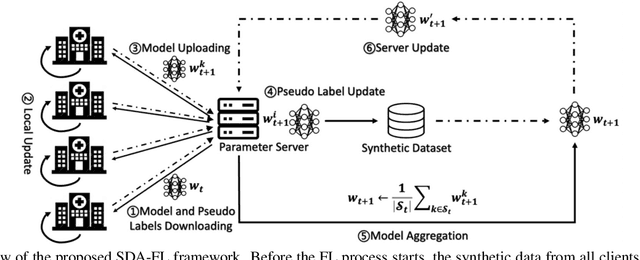
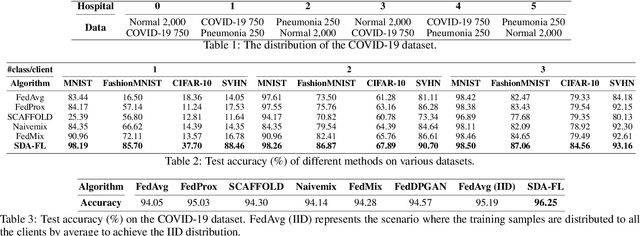

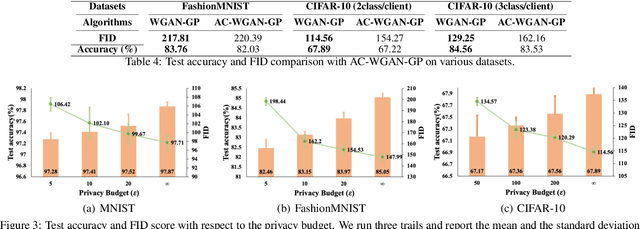
Federated learning (FL) has recently emerged as a popular privacy-preserving collaborative learning paradigm. However, it suffers from the non-independent and identically distributed (non-IID) data among clients. In this paper, we propose a novel framework, named Synthetic Data Aided Federated Learning (SDA-FL), to resolve this non-IID challenge by sharing synthetic data. Specifically, each client pretrains a local generative adversarial network (GAN) to generate differentially private synthetic data, which are uploaded to the parameter server (PS) to construct a global shared synthetic dataset. To generate confident pseudo labels for the synthetic dataset, we also propose an iterative pseudo labeling mechanism performed by the PS. A combination of the local private dataset and synthetic dataset with confident pseudo labels leads to nearly identical data distributions among clients, which improves the consistency among local models and benefits the global aggregation. Extensive experiments evidence that the proposed framework outperforms the baseline methods by a large margin in several benchmark datasets under both the supervised and semi-supervised settings.
Decentralized Stochastic Proximal Gradient Descent with Variance Reduction over Time-varying Networks
Jan 23, 2022
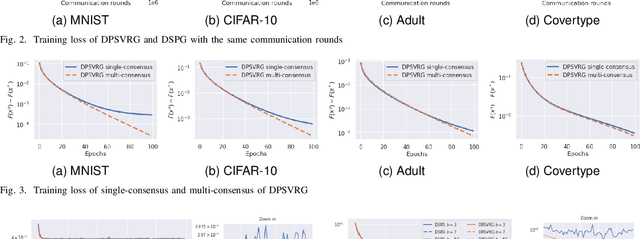

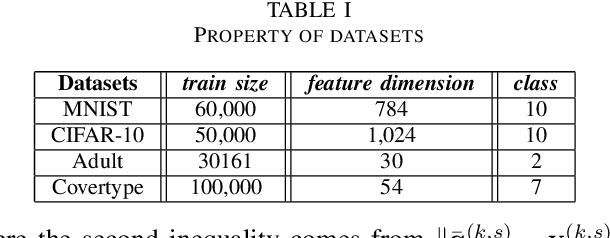
In decentralized learning, a network of nodes cooperate to minimize an overall objective function that is usually the finite-sum of their local objectives, and incorporates a non-smooth regularization term for the better generalization ability. Decentralized stochastic proximal gradient (DSPG) method is commonly used to train this type of learning models, while the convergence rate is retarded by the variance of stochastic gradients. In this paper, we propose a novel algorithm, namely DPSVRG, to accelerate the decentralized training by leveraging the variance reduction technique. The basic idea is to introduce an estimator in each node, which tracks the local full gradient periodically, to correct the stochastic gradient at each iteration. By transforming our decentralized algorithm into a centralized inexact proximal gradient algorithm with variance reduction, and controlling the bounds of error sequences, we prove that DPSVRG converges at the rate of $O(1/T)$ for general convex objectives plus a non-smooth term with $T$ as the number of iterations, while DSPG converges at the rate $O(\frac{1}{\sqrt{T}})$. Our experiments on different applications, network topologies and learning models demonstrate that DPSVRG converges much faster than DSPG, and the loss function of DPSVRG decreases smoothly along with the training epochs.
Semi-Decentralized Federated Edge Learning with Data and Device Heterogeneity
Dec 20, 2021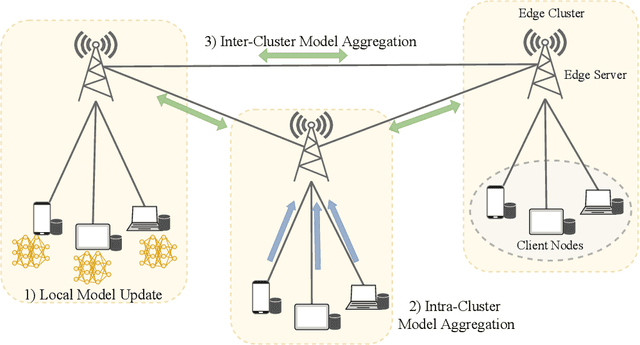


Federated edge learning (FEEL) has attracted much attention as a privacy-preserving paradigm to effectively incorporate the distributed data at the network edge for training deep learning models. Nevertheless, the limited coverage of a single edge server results in an insufficient number of participated client nodes, which may impair the learning performance. In this paper, we investigate a novel framework of FEEL, namely semi-decentralized federated edge learning (SD-FEEL), where multiple edge servers are employed to collectively coordinate a large number of client nodes. By exploiting the low-latency communication among edge servers for efficient model sharing, SD-FEEL can incorporate more training data, while enjoying much lower latency compared with conventional federated learning. We detail the training algorithm for SD-FEEL with three main steps, including local model update, intra-cluster, and inter-cluster model aggregations. The convergence of this algorithm is proved on non-independent and identically distributed (non-IID) data, which also helps to reveal the effects of key parameters on the training efficiency and provides practical design guidelines. Meanwhile, the heterogeneity of edge devices may cause the straggler effect and deteriorate the convergence speed of SD-FEEL. To resolve this issue, we propose an asynchronous training algorithm with a staleness-aware aggregation scheme for SD-FEEL, of which, the convergence performance is also analyzed. The simulation results demonstrate the effectiveness and efficiency of the proposed algorithms for SD-FEEL and corroborate our analysis.
Faster Activity and Data Detection in Massive Random Access: A Multi-armed Bandit Approach
Jan 28, 2020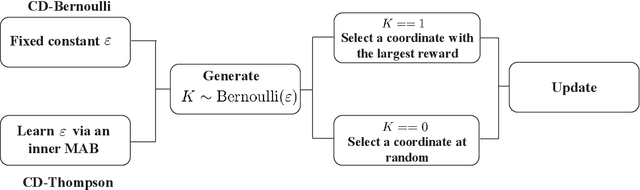
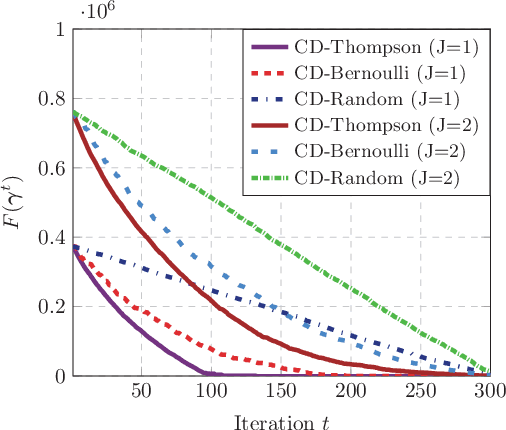
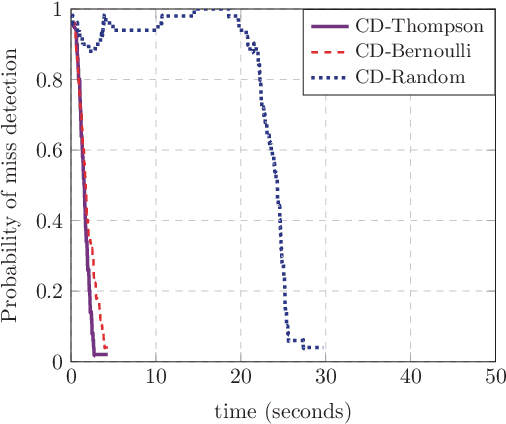
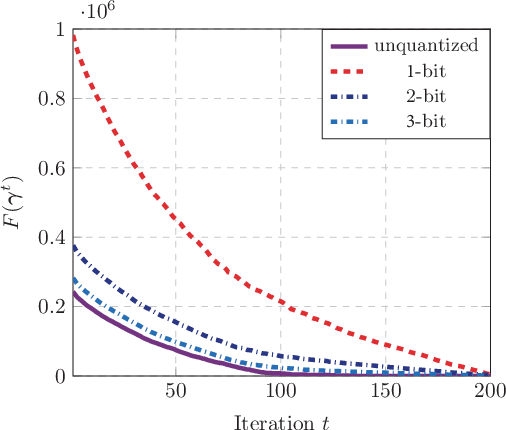
This paper investigates the grant-free random access with massive IoT devices. By embedding the data symbols in the signature sequences, joint device activity detection and data decoding can be achieved, which, however, significantly increases the computational complexity. Coordinate descent algorithms that enjoy a low per-iteration complexity have been employed to solve the detection problem, but previous works typically employ a random coordinate selection policy which leads to slow convergence. In this paper, we develop multi-armed bandit approaches for more efficient detection via coordinate descent, which make a delicate trade-off between exploration and exploitation in coordinate selection. Specifically, we first propose a bandit based strategy, i.e., Bernoulli sampling, to speed up the convergence rate of coordinate descent, by learning which coordinates will result in more aggressive descent of the objective function. To further improve the convergence rate, an inner multi-armed bandit problem is established to learn the exploration policy of Bernoulli sampling. Both convergence rate analysis and simulation results are provided to show that the proposed bandit based algorithms enjoy faster convergence rates with a lower time complexity compared with the state-of-the-art algorithm. Furthermore, our proposed algorithms are applicable to different scenarios, e.g., massive random access with low-precision analog-to-digital converters (ADCs).