 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025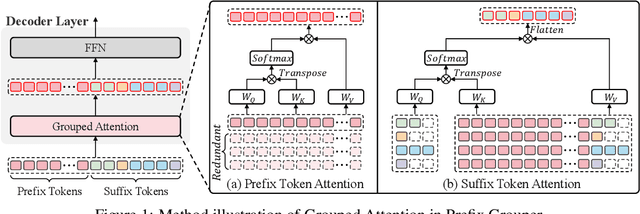
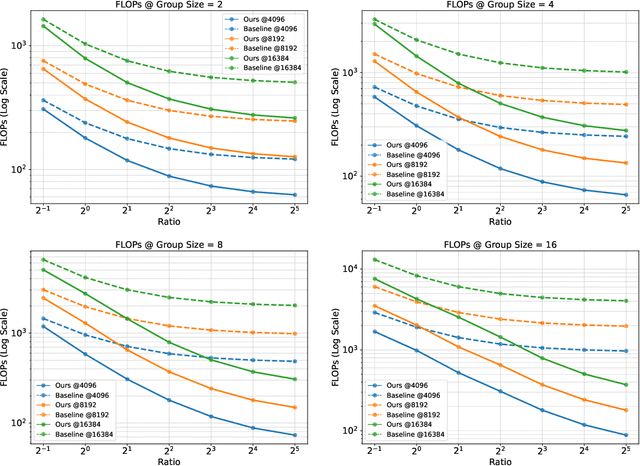
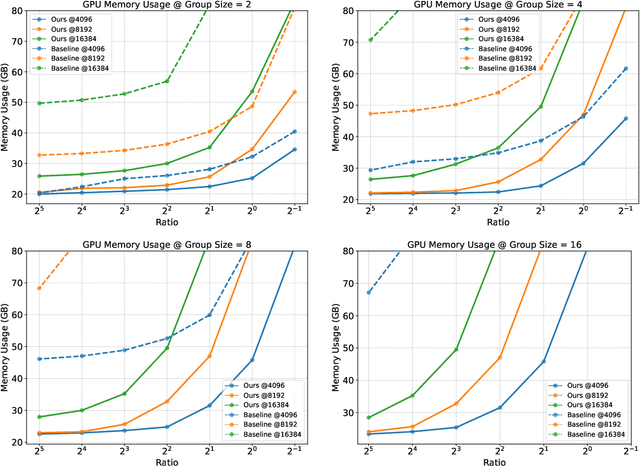
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Improving Phishing Email Detection Performance of Small Large Language Models
Apr 29, 2025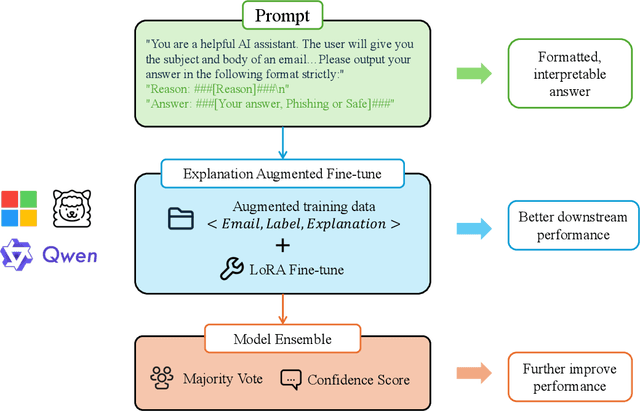



Large language models(LLMs) have demonstrated remarkable performance on many natural language processing(NLP) tasks and have been employed in phishing email detection research. However, in current studies, well-performing LLMs typically contain billions or even tens of billions of parameters, requiring enormous computational resources. To reduce computational costs, we investigated the effectiveness of small-parameter LLMs for phishing email detection. These LLMs have around 3 billion parameters and can run on consumer-grade GPUs. However, small LLMs often perform poorly in phishing email detection task. To address these issues, we designed a set of methods including Prompt Engineering, Explanation Augmented Fine-tuning, and Model Ensemble to improve phishing email detection capabilities of small LLMs. We validated the effectiveness of our approach through experiments, significantly improving accuracy on the SpamAssassin dataset from around 0.5 for baseline models like Qwen2.5-1.5B-Instruct to 0.976.
Do we Really Need Visual Instructions? Towards Visual Instruction-Free Fine-tuning for Large Vision-Language Models
Feb 17, 2025Visual instruction tuning has become the predominant technology in eliciting the multimodal task-solving capabilities of large vision-language models (LVLMs). Despite the success, as visual instructions require images as the input, it would leave the gap in inheriting the task-solving capabilities from the backbone LLMs, and make it costly to collect a large-scale dataset. To address it, we propose ViFT, a visual instruction-free fine-tuning framework for LVLMs. In ViFT, we only require the text-only instructions and image caption data during training, to separately learn the task-solving and visual perception abilities. During inference, we extract and combine the representations of the text and image inputs, for fusing the two abilities to fulfill multimodal tasks. Experimental results demonstrate that ViFT can achieve state-of-the-art performance on several visual reasoning and visual instruction following benchmarks, with rather less training data. Our code and data will be publicly released.
VRoPE: Rotary Position Embedding for Video Large Language Models
Feb 17, 2025Rotary Position Embedding (RoPE) has shown strong performance in text-based Large Language Models (LLMs), but extending it to video remains a challenge due to the intricate spatiotemporal structure of video frames. Existing adaptations, such as RoPE-3D, attempt to encode spatial and temporal dimensions separately but suffer from two major limitations: positional bias in attention distribution and disruptions in video-text transitions. To overcome these issues, we propose Video Rotary Position Embedding (VRoPE), a novel positional encoding method tailored for Video-LLMs. Our approach restructures positional indices to preserve spatial coherence and ensure a smooth transition between video and text tokens. Additionally, we introduce a more balanced encoding strategy that mitigates attention biases, ensuring a more uniform distribution of spatial focus. Extensive experiments on Vicuna and Qwen2 across different model scales demonstrate that VRoPE consistently outperforms previous RoPE variants, achieving significant improvements in video understanding, temporal reasoning, and retrieval tasks. Code will be available at https://github.com/johncaged/VRoPE
Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
Jan 03, 2025Recently, slow-thinking reasoning systems, built upon large language models (LLMs), have garnered widespread attention by scaling the thinking time during inference. There is also growing interest in adapting this capability to multimodal large language models (MLLMs). Given that MLLMs handle more complex data semantics across different modalities, it is intuitively more challenging to implement multimodal slow-thinking systems. To address this issue, in this paper, we explore a straightforward approach by fine-tuning a capable MLLM with a small amount of textual long-form thought data, resulting in a multimodal slow-thinking system, Virgo (Visual reasoning with long thought). We find that these long-form reasoning processes, expressed in natural language, can be effectively transferred to MLLMs. Moreover, it seems that such textual reasoning data can be even more effective than visual reasoning data in eliciting the slow-thinking capacities of MLLMs. While this work is preliminary, it demonstrates that slow-thinking capacities are fundamentally associated with the language model component, which can be transferred across modalities or domains. This finding can be leveraged to guide the development of more powerful slow-thinking reasoning systems. We release our resources at https://github.com/RUCAIBox/Virgo.
Less is More: Data Value Estimation for Visual Instruction Tuning
Mar 21, 2024Visual instruction tuning is the key to building multimodal large language models (MLLMs), which greatly improves the reasoning capabilities of large language models (LLMs) in vision scenario. However, existing MLLMs mostly rely on a mixture of multiple highly diverse visual instruction datasets for training (even more than a million instructions), which may introduce data redundancy. To investigate this issue, we conduct a series of empirical studies, which reveal a significant redundancy within the visual instruction datasets, and show that greatly reducing the amount of several instruction dataset even do not affect the performance. Based on the findings, we propose a new data selection approach TIVE, to eliminate redundancy within visual instruction data. TIVE first estimates the task-level and instance-level value of the visual instructions based on computed gradients. Then, according to the estimated values, TIVE determines the task proportion within the visual instructions, and selects representative instances to compose a smaller visual instruction subset for training. Experiments on LLaVA-1.5 show that our approach using only about 7.5% data can achieve comparable performance as the full-data fine-tuned model across seven benchmarks, even surpassing it on four of the benchmarks. Our code and data will be publicly released.
Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study
Jul 26, 2023Despite the superior performance, Large Language Models~(LLMs) require significant computational resources for deployment and use. To overcome this issue, quantization methods have been widely applied to reduce the memory footprint of LLMs as well as increasing the inference rate. However, a major challenge is that low-bit quantization methods often lead to performance degradation. It is important to understand how quantization impacts the capacity of LLMs. Different from previous studies focused on overall performance, this work aims to investigate the impact of quantization on \emph{emergent abilities}, which are important characteristics that distinguish LLMs from small language models. Specially, we examine the abilities of in-context learning, chain-of-thought reasoning, and instruction-following in quantized LLMs. Our empirical experiments show that these emergent abilities still exist in 4-bit quantization models, while 2-bit models encounter severe performance degradation on the test of these abilities. To improve the performance of low-bit models, we conduct two special experiments: (1) fine-gained impact analysis that studies which components (or substructures) are more sensitive to quantization, and (2) performance compensation through model fine-tuning. Our work derives a series of important findings to understand the impact of quantization on emergent abilities, and sheds lights on the possibilities of extremely low-bit quantization for LLMs.
VLAB: Enhancing Video Language Pre-training by Feature Adapting and Blending
May 22, 2023Large-scale image-text contrastive pre-training models, such as CLIP, have been demonstrated to effectively learn high-quality multimodal representations. However, there is limited research on learning video-text representations for general video multimodal tasks based on these powerful features. Towards this goal, we propose a novel video-text pre-training method dubbed VLAB: Video Language pre-training by feature Adapting and Blending, which transfers CLIP representations to video pre-training tasks and develops unified video multimodal models for a wide range of video-text tasks. Specifically, VLAB is founded on two key strategies: feature adapting and feature blending. In the former, we introduce a new video adapter module to address CLIP's deficiency in modeling temporal information and extend the model's capability to encompass both contrastive and generative tasks. In the latter, we propose an end-to-end training method that further enhances the model's performance by exploiting the complementarity of image and video features. We validate the effectiveness and versatility of VLAB through extensive experiments on highly competitive video multimodal tasks, including video text retrieval, video captioning, and video question answering. Remarkably, VLAB outperforms competing methods significantly and sets new records in video question answering on MSRVTT, MSVD, and TGIF datasets. It achieves an accuracy of 49.6, 61.0, and 79.0, respectively. Codes and models will be released.
Enhancing Vision-Language Pre-Training with Jointly Learned Questioner and Dense Captioner
May 19, 2023Large pre-trained multimodal models have demonstrated significant success in a range of downstream tasks, including image captioning, image-text retrieval, visual question answering (VQA), etc. However, many of these methods rely on image-text pairs collected from the web as pre-training data and unfortunately overlook the need for fine-grained feature alignment between vision and language modalities, which requires detailed understanding of images and language expressions. While integrating VQA and dense captioning (DC) into pre-training can address this issue, acquiring image-question-answer as well as image-location-caption triplets is challenging and time-consuming. Additionally, publicly available datasets for VQA and dense captioning are typically limited in scale due to manual data collection and labeling efforts. In this paper, we propose a novel method called Joint QA and DC GEneration (JADE), which utilizes a pre-trained multimodal model and easily-crawled image-text pairs to automatically generate and filter large-scale VQA and dense captioning datasets. We apply this method to the Conceptual Caption (CC3M) dataset to generate a new dataset called CC3M-QA-DC. Experiments show that when used for pre-training in a multi-task manner, CC3M-QA-DC can improve the performance with various backbones on various downstream tasks. Furthermore, our generated CC3M-QA-DC can be combined with larger image-text datasets (e.g., CC15M) and achieve competitive results compared with models using much more data. Code and dataset will be released.