 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSpark: Adaptive Sparsity for Efficient Long-Video Understanding
Apr 09, 2026Processing long-form videos with Video Large Language Models (Video-LLMs) is computationally prohibitive. Current efficiency methods often compromise fine-grained perception through irreversible information disposal or inhibit long-range temporal modeling via rigid, predefined sparse patterns. This paper introduces AdaSpark, an adaptive sparsity framework designed to address these limitations. AdaSpark first partitions video inputs into 3D spatio-temporal cubes. It then employs two co-designed, context-aware components: (1) Adaptive Cube-Selective Attention (AdaS-Attn), which adaptively selects a subset of relevant video cubes to attend for each query token, and (2) Adaptive Token-Selective FFN (AdaS-FFN), which selectively processes only the most salient tokens within each cube. An entropy-based (Top-p) selection mechanism adaptively allocates computational resources based on input complexity. Experiments demonstrate that AdaSpark significantly reduces computational load by up to 57% FLOPs while maintaining comparable performance to dense models and preserving fine-grained, long-range dependencies, as validated on challenging hour-scale video benchmarks.
EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Mar 24, 2026Video understanding with multimodal large language models (MLLMs) remains challenging due to the long token sequences of videos, which contain extensive temporal dependencies and redundant frames. Existing approaches typically treat MLLMs as passive recognizers, processing entire videos or uniformly sampled frames without adaptive reasoning. Recent agent-based methods introduce external tools, yet still depend on manually designed workflows and perception-first strategies, resulting in inefficiency on long videos. We present EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agent, which enables planning-before-perception through iterative summary-plan-action-reflection reasoning. EVA autonomously decides what to watch, when to watch, and how to watch, achieving query-driven and efficient video understanding. To train such agents, we design a simple yet effective three-stage learning pipeline - comprising supervised fine-tuning (SFT), Kahneman-Tversky Optimization (KTO), and Generalized Reward Policy Optimization (GRPO) - that bridges supervised imitation and reinforcement learning. We further construct high-quality datasets for each stage, supporting stable and reproducible training. We evaluate EVA on six video understanding benchmarks, demonstrating its comprehensive capabilities. Compared with existing baselines, EVA achieves a substantial improvement of 6-12% over general MLLM baselines and a further 1-3% gain over prior adaptive agent methods. Our code and model are available at https://github.com/wangruohui/EfficientVideoAgent.
ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Aug 29, 2025

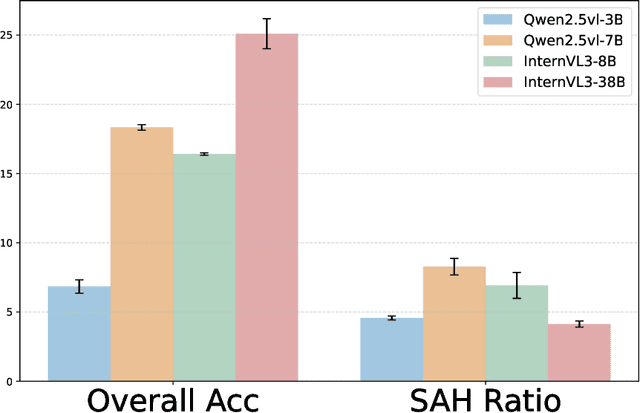
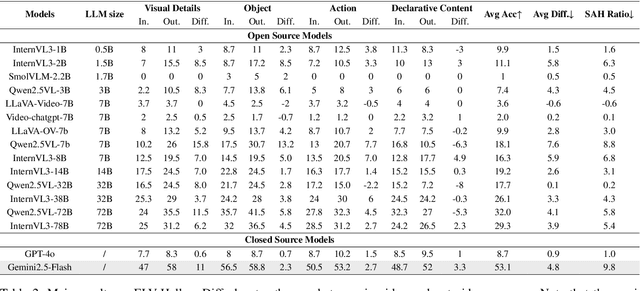
Video multimodal large language models (Video-MLLMs) have achieved remarkable progress in video understanding. However, they remain vulnerable to hallucination-producing content inconsistent with or unrelated to video inputs. Previous video hallucination benchmarks primarily focus on short-videos. They attribute hallucinations to factors such as strong language priors, missing frames, or vision-language biases introduced by the visual encoder. While these causes indeed account for most hallucinations in short videos, they still oversimplify the cause of hallucinations. Sometimes, models generate incorrect outputs but with correct frame-level semantics. We refer to this type of hallucination as Semantic Aggregation Hallucination (SAH), which arises during the process of aggregating frame-level semantics into event-level semantic groups. Given that SAH becomes particularly critical in long videos due to increased semantic complexity across multiple events, it is essential to separate and thoroughly investigate the causes of this type of hallucination. To address the above issues, we introduce ELV-Halluc, the first benchmark dedicated to long-video hallucination, enabling a systematic investigation of SAH. Our experiments confirm the existence of SAH and show that it increases with semantic complexity. Additionally, we find that models are more prone to SAH on rapidly changing semantics. Moreover, we discuss potential approaches to mitigate SAH. We demonstrate that positional encoding strategy contributes to alleviating SAH, and further adopt DPO strategy to enhance the model's ability to distinguish semantics within and across events. To support this, we curate a dataset of 8K adversarial data pairs and achieve improvements on both ELV-Halluc and Video-MME, including a substantial 27.7% reduction in SAH ratio.
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025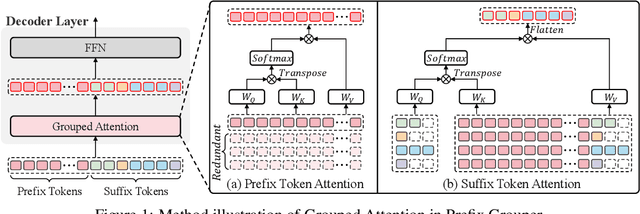
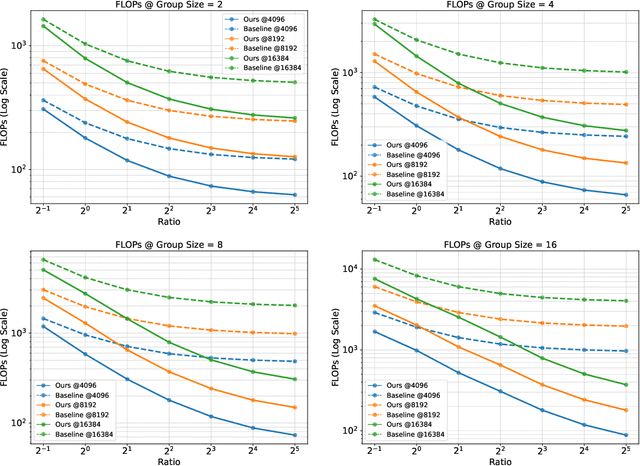
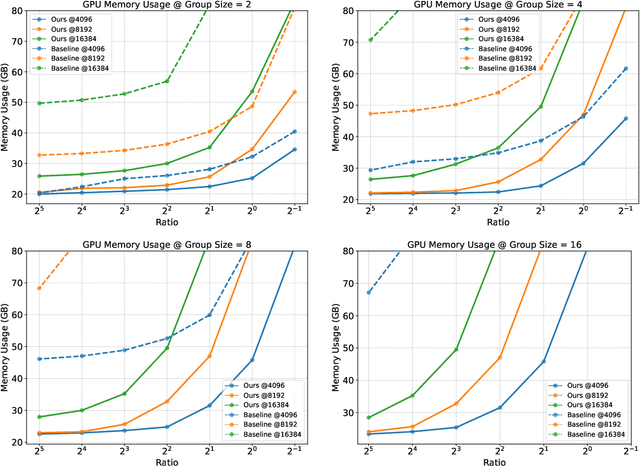
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.
Image Difference Grounding with Natural Language
Apr 02, 2025Visual grounding (VG) typically focuses on locating regions of interest within an image using natural language, and most existing VG methods are limited to single-image interpretations. This limits their applicability in real-world scenarios like automatic surveillance, where detecting subtle but meaningful visual differences across multiple images is crucial. Besides, previous work on image difference understanding (IDU) has either focused on detecting all change regions without cross-modal text guidance, or on providing coarse-grained descriptions of differences. Therefore, to push towards finer-grained vision-language perception, we propose Image Difference Grounding (IDG), a task designed to precisely localize visual differences based on user instructions. We introduce DiffGround, a large-scale and high-quality dataset for IDG, containing image pairs with diverse visual variations along with instructions querying fine-grained differences. Besides, we present a baseline model for IDG, DiffTracker, which effectively integrates feature differential enhancement and common suppression to precisely locate differences. Experiments on the DiffGround dataset highlight the importance of our IDG dataset in enabling finer-grained IDU. To foster future research, both DiffGround data and DiffTracker model will be publicly released.
VRoPE: Rotary Position Embedding for Video Large Language Models
Feb 17, 2025Rotary Position Embedding (RoPE) has shown strong performance in text-based Large Language Models (LLMs), but extending it to video remains a challenge due to the intricate spatiotemporal structure of video frames. Existing adaptations, such as RoPE-3D, attempt to encode spatial and temporal dimensions separately but suffer from two major limitations: positional bias in attention distribution and disruptions in video-text transitions. To overcome these issues, we propose Video Rotary Position Embedding (VRoPE), a novel positional encoding method tailored for Video-LLMs. Our approach restructures positional indices to preserve spatial coherence and ensure a smooth transition between video and text tokens. Additionally, we introduce a more balanced encoding strategy that mitigates attention biases, ensuring a more uniform distribution of spatial focus. Extensive experiments on Vicuna and Qwen2 across different model scales demonstrate that VRoPE consistently outperforms previous RoPE variants, achieving significant improvements in video understanding, temporal reasoning, and retrieval tasks. Code will be available at https://github.com/johncaged/VRoPE
Diffusion Feedback Helps CLIP See Better
Jul 29, 2024Contrastive Language-Image Pre-training (CLIP), which excels at abstracting open-world representations across domains and modalities, has become a foundation for a variety of vision and multimodal tasks. However, recent studies reveal that CLIP has severe visual shortcomings, such as which can hardly distinguish orientation, quantity, color, structure, etc. These visual shortcomings also limit the perception capabilities of multimodal large language models (MLLMs) built on CLIP. The main reason could be that the image-text pairs used to train CLIP are inherently biased, due to the lack of the distinctiveness of the text and the diversity of images. In this work, we present a simple post-training approach for CLIP models, which largely overcomes its visual shortcomings via a self-supervised diffusion process. We introduce DIVA, which uses the DIffusion model as a Visual Assistant for CLIP. Specifically, DIVA leverages generative feedback from text-to-image diffusion models to optimize CLIP representations, with only images (without corresponding text). We demonstrate that DIVA improves CLIP's performance on the challenging MMVP-VLM benchmark which assesses fine-grained visual abilities to a large extent (e.g., 3-7%), and enhances the performance of MLLMs and vision models on multimodal understanding and segmentation tasks. Extensive evaluation on 29 image classification and retrieval benchmarks confirms that our framework preserves CLIP's strong zero-shot capabilities. The code will be available at https://github.com/baaivision/DIVA.