 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Paper and Code


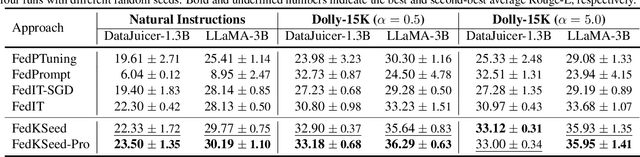

Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.