 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Param$Δ$ for Direct Weight Mixing: Post-Train Large Language Model at Zero Cost
Apr 23, 2025The post-training phase of large language models is essential for enhancing capabilities such as instruction-following, reasoning, and alignment with human preferences. However, it demands extensive high-quality data and poses risks like overfitting, alongside significant computational costs due to repeated post-training and evaluation after each base model update. This paper introduces $Param\Delta$, a novel method that streamlines post-training by transferring knowledge from an existing post-trained model to a newly updated base model with ZERO additional training. By computing the difference between post-trained model weights ($\Theta_\text{post}$) and base model weights ($\Theta_\text{base}$), and adding this to the updated base model ($\Theta'_\text{base}$), we define $Param\Delta$ Model as: $\Theta_{\text{Param}\Delta} = \Theta_\text{post} - \Theta_\text{base} + \Theta'_\text{base}$. This approach surprisingly equips the new base model with post-trained capabilities, achieving performance comparable to direct post-training. We did analysis on LLama3, Llama3.1, Qwen, and DeepSeek-distilled models. Results indicate $Param\Delta$ Model effectively replicates traditional post-training. For example, the $Param\Delta$ Model obtained from 70B Llama3-inst, Llama3-base, Llama3.1-base models attains approximately 95\% of Llama3.1-inst model's performance on average. $Param\Delta$ brings a new perspective on how to fully leverage models in the open-weight community, where checkpoints for base and instruct models are readily available and frequently updated, by providing a cost-free framework to accelerate the iterative cycle of model development.
* Published as a conference paper at ICLR 2025
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Pruning Compact ConvNets for Efficient Inference
Jan 11, 2023Neural network pruning is frequently used to compress over-parameterized networks by large amounts, while incurring only marginal drops in generalization performance. However, the impact of pruning on networks that have been highly optimized for efficient inference has not received the same level of attention. In this paper, we analyze the effect of pruning for computer vision, and study state-of-the-art ConvNets, such as the FBNetV3 family of models. We show that model pruning approaches can be used to further optimize networks trained through NAS (Neural Architecture Search). The resulting family of pruned models can consistently obtain better performance than existing FBNetV3 models at the same level of computation, and thus provide state-of-the-art results when trading off between computational complexity and generalization performance on the ImageNet benchmark. In addition to better generalization performance, we also demonstrate that when limited computation resources are available, pruning FBNetV3 models incur only a fraction of GPU-hours involved in running a full-scale NAS.
Reconciling Security and Communication Efficiency in Federated Learning
Jul 26, 2022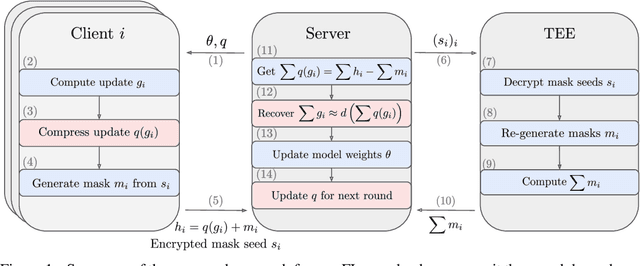

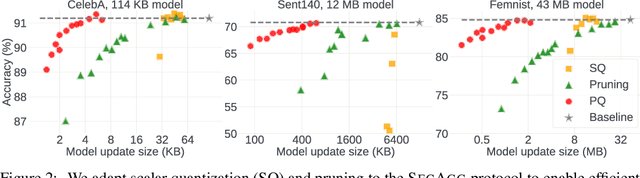
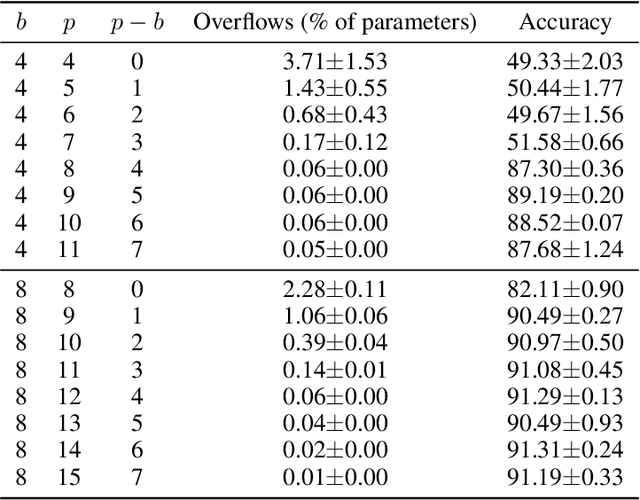
Cross-device Federated Learning is an increasingly popular machine learning setting to train a model by leveraging a large population of client devices with high privacy and security guarantees. However, communication efficiency remains a major bottleneck when scaling federated learning to production environments, particularly due to bandwidth constraints during uplink communication. In this paper, we formalize and address the problem of compressing client-to-server model updates under the Secure Aggregation primitive, a core component of Federated Learning pipelines that allows the server to aggregate the client updates without accessing them individually. In particular, we adapt standard scalar quantization and pruning methods to Secure Aggregation and propose Secure Indexing, a variant of Secure Aggregation that supports quantization for extreme compression. We establish state-of-the-art results on LEAF benchmarks in a secure Federated Learning setup with up to 40$\times$ compression in uplink communication with no meaningful loss in utility compared to uncompressed baselines.
Opacus: User-Friendly Differential Privacy Library in PyTorch
Oct 05, 2021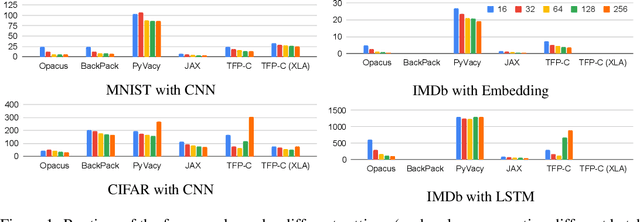
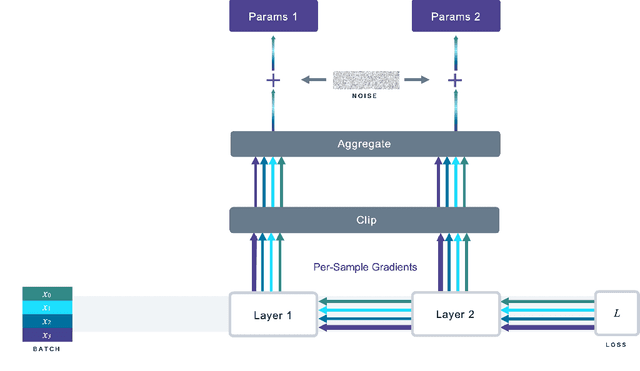
We introduce Opacus, a free, open-source PyTorch library for training deep learning models with differential privacy (hosted at opacus.ai). Opacus is designed for simplicity, flexibility, and speed. It provides a simple and user-friendly API, and enables machine learning practitioners to make a training pipeline private by adding as little as two lines to their code. It supports a wide variety of layers, including multi-head attention, convolution, LSTM, and embedding, right out of the box, and it also provides the means for supporting other user-defined layers. Opacus computes batched per-sample gradients, providing better efficiency compared to the traditional "micro batch" approach. In this paper we present Opacus, detail the principles that drove its implementation and unique features, and compare its performance against other frameworks for differential privacy in ML.
Antipodes of Label Differential Privacy: PATE and ALIBI
Jun 07, 2021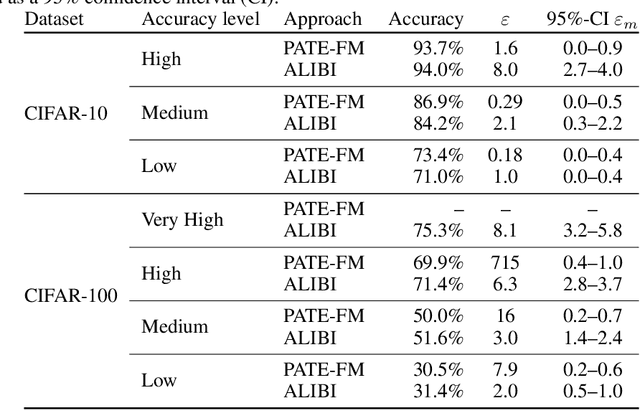
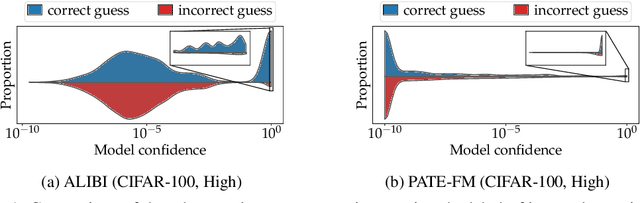
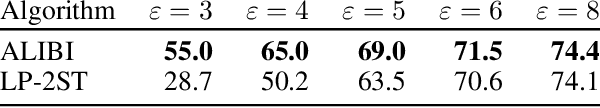
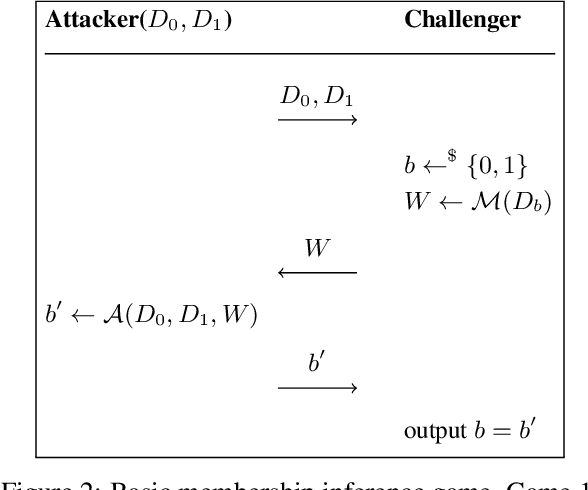
We consider the privacy-preserving machine learning (ML) setting where the trained model must satisfy differential privacy (DP) with respect to the labels of the training examples. We propose two novel approaches based on, respectively, the Laplace mechanism and the PATE framework, and demonstrate their effectiveness on standard benchmarks. While recent work by Ghazi et al. proposed Label DP schemes based on a randomized response mechanism, we argue that additive Laplace noise coupled with Bayesian inference (ALIBI) is a better fit for typical ML tasks. Moreover, we show how to achieve very strong privacy levels in some regimes, with our adaptation of the PATE framework that builds on recent advances in semi-supervised learning. We complement theoretical analysis of our algorithms' privacy guarantees with empirical evaluation of their memorization properties. Our evaluation suggests that comparing different algorithms according to their provable DP guarantees can be misleading and favor a less private algorithm with a tighter analysis.