 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM+: Scalable State-of-the-Art Private Synthetic Data with Generator Networks
Nov 12, 2025
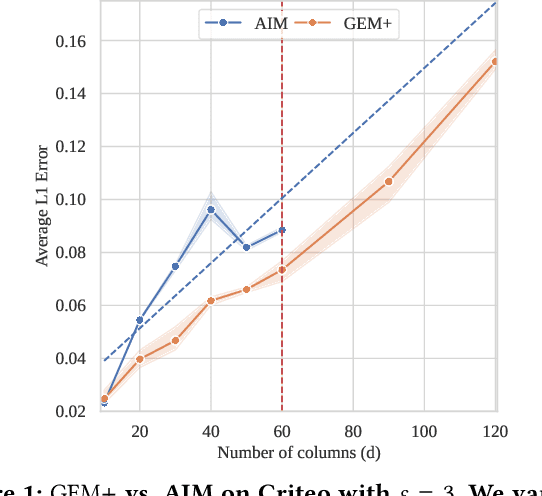
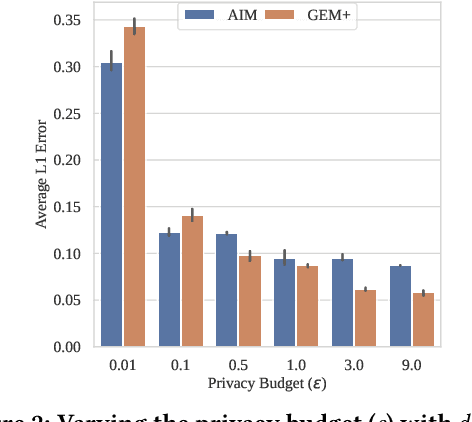

State-of-the-art differentially private synthetic tabular data has been defined by adaptive 'select-measure-generate' frameworks, exemplified by methods like AIM. These approaches iteratively measure low-order noisy marginals and fit graphical models to produce synthetic data, enabling systematic optimisation of data quality under privacy constraints. Graphical models, however, are inefficient for high-dimensional data because they require substantial memory and must be retrained from scratch whenever the graph structure changes, leading to significant computational overhead. Recent methods, like GEM, overcome these limitations by using generator neural networks for improved scalability. However, empirical comparisons have mostly focused on small datasets, limiting real-world applicability. In this work, we introduce GEM+, which integrates AIM's adaptive measurement framework with GEM's scalable generator network. Our experiments show that GEM+ outperforms AIM in both utility and scalability, delivering state-of-the-art results while efficiently handling datasets with over a hundred columns, where AIM fails due to memory and computational overheads.
Leveraging Vertical Public-Private Split for Improved Synthetic Data Generation
Apr 15, 2025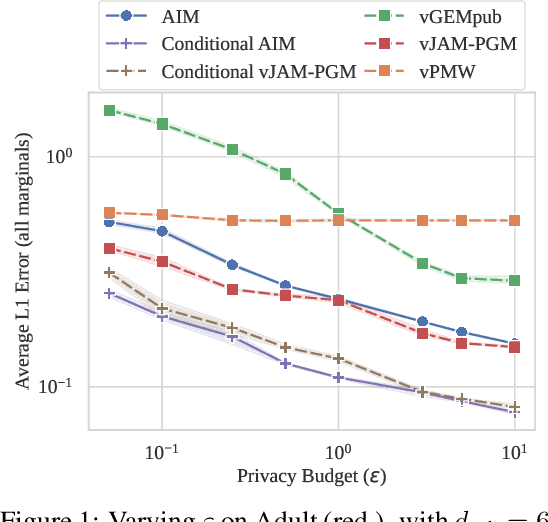


Differentially Private Synthetic Data Generation (DP-SDG) is a key enabler of private and secure tabular-data sharing, producing artificial data that carries through the underlying statistical properties of the input data. This typically involves adding carefully calibrated statistical noise to guarantee individual privacy, at the cost of synthetic data quality. Recent literature has explored scenarios where a small amount of public data is used to help enhance the quality of synthetic data. These methods study a horizontal public-private partitioning which assumes access to a small number of public rows that can be used for model initialization, providing a small utility gain. However, realistic datasets often naturally consist of public and private attributes, making a vertical public-private partitioning relevant for practical synthetic data deployments. We propose a novel framework that adapts horizontal public-assisted methods into the vertical setting. We compare this framework against our alternative approach that uses conditional generation, highlighting initial limitations of public-data assisted methods and proposing future research directions to address these challenges.