 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring to learn visual saliency: The RL-IAC approach
Paper and Code
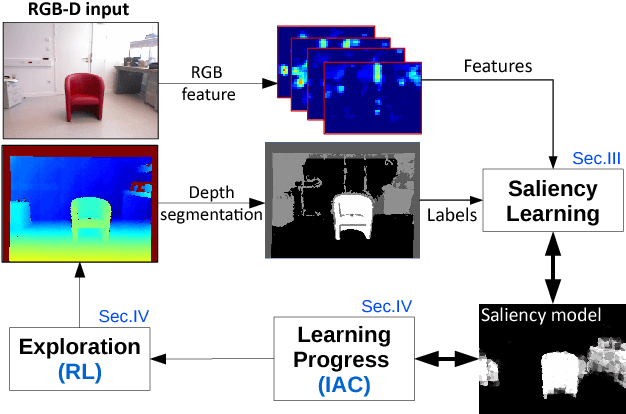
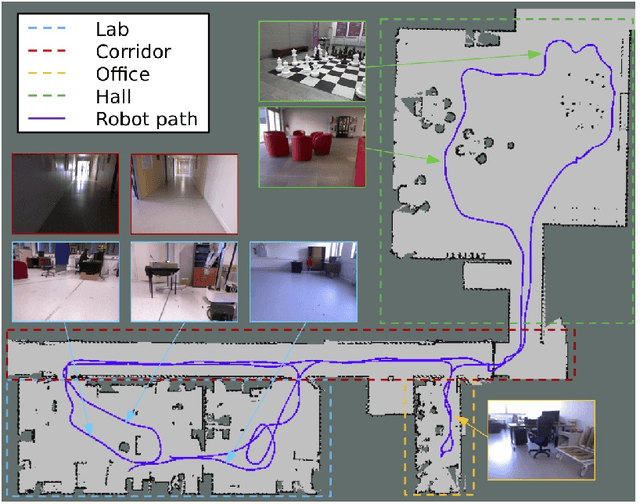

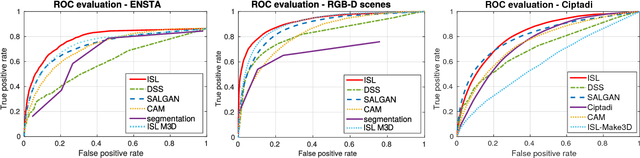
The problem of object localization and recognition on autonomous mobile robots is still an active topic. In this context, we tackle the problem of learning a model of visual saliency directly on a robot. This model, learned and improved on-the-fly during the robot's exploration provides an efficient tool for localizing relevant objects within their environment. The proposed approach includes two intertwined components. On the one hand, we describe a method for learning and incrementally updating a model of visual saliency from a depth-based object detector. This model of saliency can also be exploited to produce bounding box proposals around objects of interest. On the other hand, we investigate an autonomous exploration technique to efficiently learn such a saliency model. The proposed exploration, called Reinforcement Learning-Intelligent Adaptive Curiosity (RL-IAC) is able to drive the robot's exploration so that samples selected by the robot are likely to improve the current model of saliency. We then demonstrate that such a saliency model learned directly on a robot outperforms several state-of-the-art saliency techniques, and that RL-IAC can drastically decrease the required time for learning a reliable saliency model.