 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Remember: A Synaptic Plasticity Driven Framework for Continual Learning
May 28, 2019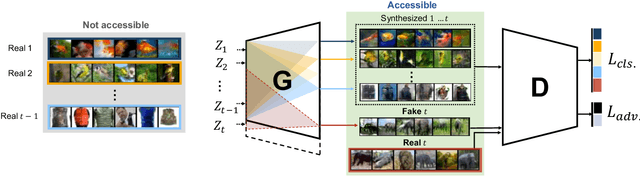
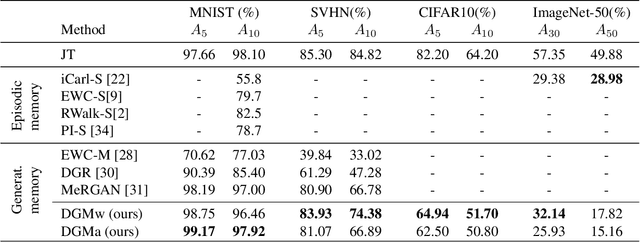
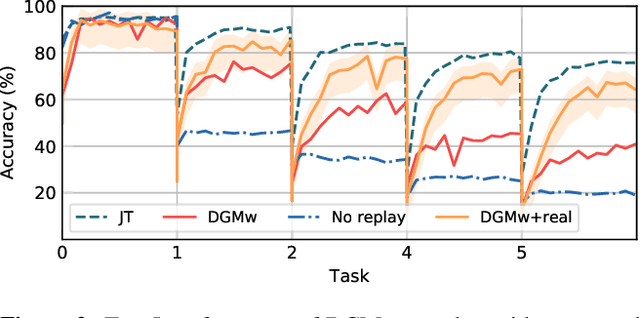
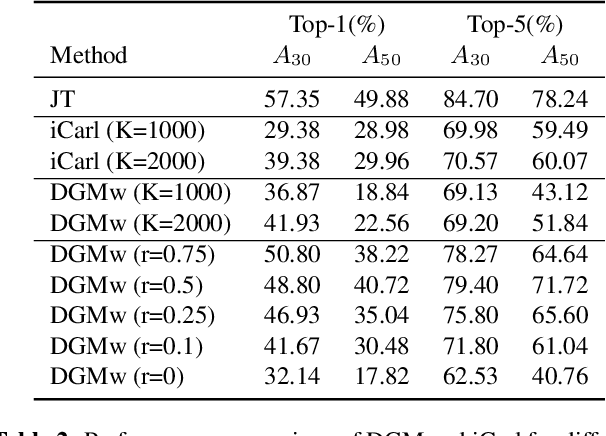
Models trained in the context of continual learning (CL) should be able to learn from a stream of data over an undefined period of time. The main challenges herein are: 1) maintaining old knowledge while simultaneously benefiting from it when learning new tasks, and 2) guaranteeing model scalability with a growing amount of data to learn from. In order to tackle these challenges, we introduce Dynamic Generative Memory (DGM) - a synaptic plasticity driven framework for continual learning. DGM relies on conditional generative adversarial networks with learnable connection plasticity realized with neural masking. Specifically, we evaluate two variants of neural masking: applied to (i) layer activations and (ii) to connection weights directly. Furthermore, we propose a dynamic network expansion mechanism that ensures sufficient model capacity to accommodate for continually incoming tasks. The amount of added capacity is determined dynamically from the learned binary mask. We evaluate DGM in the continual class-incremental setup on visual classification tasks.
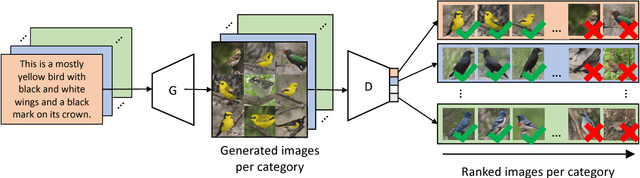
Self Paced Adversarial Training for Multimodal Few-shot Learning
Nov 22, 2018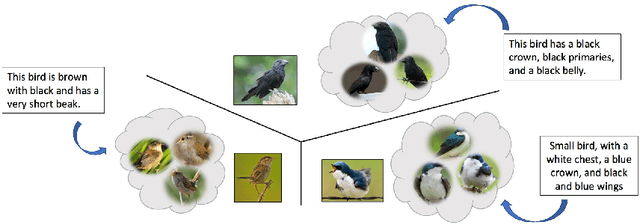
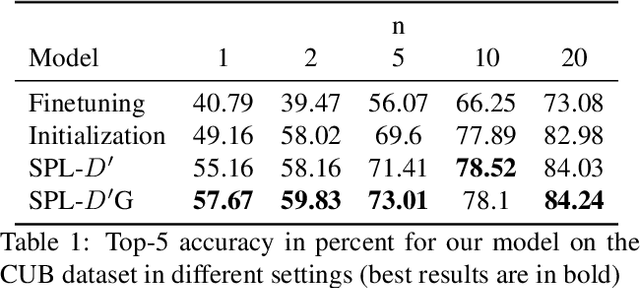
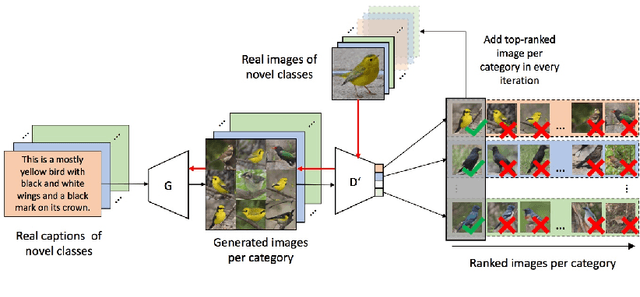
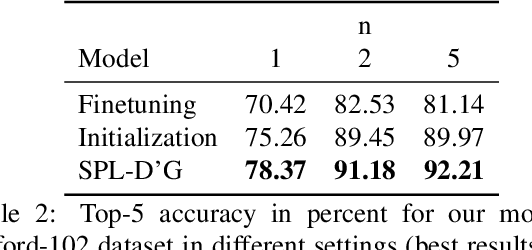
State-of-the-art deep learning algorithms yield remarkable results in many visual recognition tasks. However, they still fail to provide satisfactory results in scarce data regimes. To a certain extent this lack of data can be compensated by multimodal information. Missing information in one modality of a single data point (e.g. an image) can be made up for in another modality (e.g. a textual description). Therefore, we design a few-shot learning task that is multimodal during training (i.e. image and text) and single-modal during test time (i.e. image). In this regard, we propose a self-paced class-discriminative generative adversarial network incorporating multimodality in the context of few-shot learning. The proposed approach builds upon the idea of cross-modal data generation in order to alleviate the data sparsity problem. We improve few-shot learning accuracies on the finegrained CUB and Oxford-102 datasets.
Cross-modal Hallucination for Few-shot Fine-grained Recognition
Jun 14, 2018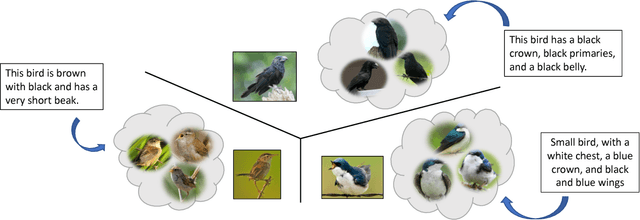

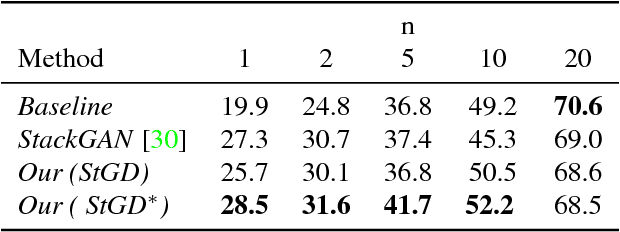
State-of-the-art deep learning algorithms generally require large amounts of data for model training. Lack thereof can severely deteriorate the performance, particularly in scenarios with fine-grained boundaries between categories. To this end, we propose a multimodal approach that facilitates bridging the information gap by means of meaningful joint embeddings. Specifically, we present a benchmark that is multimodal during training (i.e. images and texts) and single-modal in testing time (i.e. images), with the associated task to utilize multimodal data in base classes (with many samples), to learn explicit visual classifiers for novel classes (with few samples). Next, we propose a framework built upon the idea of cross-modal data hallucination. In this regard, we introduce a discriminative text-conditional GAN for sample generation with a simple self-paced strategy for sample selection. We show the results of our proposed discriminative hallucinated method for 1-, 2-, and 5- shot learning on the CUB dataset, where the accuracy is improved by employing multimodal data.
Scalable Generalized Dynamic Topic Models
Mar 21, 2018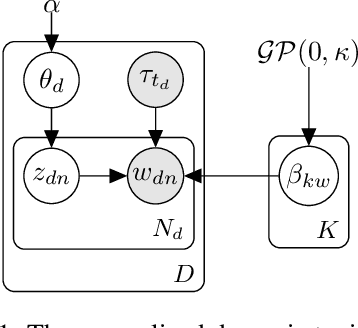
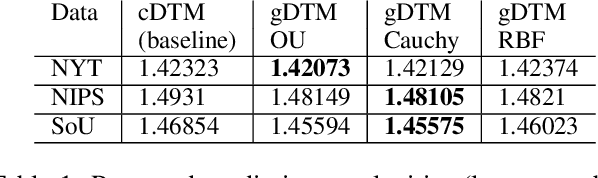
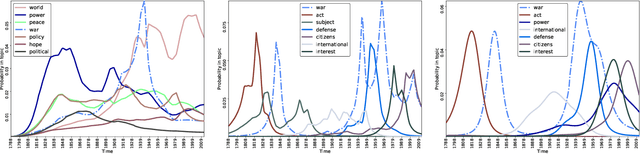
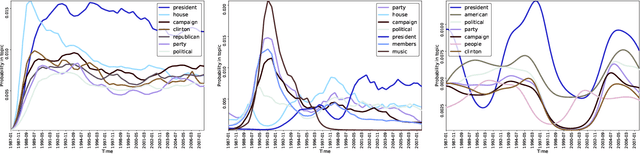
Dynamic topic models (DTMs) model the evolution of prevalent themes in literature, online media, and other forms of text over time. DTMs assume that word co-occurrence statistics change continuously and therefore impose continuous stochastic process priors on their model parameters. These dynamical priors make inference much harder than in regular topic models, and also limit scalability. In this paper, we present several new results around DTMs. First, we extend the class of tractable priors from Wiener processes to the generic class of Gaussian processes (GPs). This allows us to explore topics that develop smoothly over time, that have a long-term memory or are temporally concentrated (for event detection). Second, we show how to perform scalable approximate inference in these models based on ideas around stochastic variational inference and sparse Gaussian processes. This way we can train a rich family of DTMs to massive data. Our experiments on several large-scale datasets show that our generalized model allows us to find interesting patterns that were not accessible by previous approaches.