 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Prototypical Networks for Few-shot Learning
Nov 17, 2020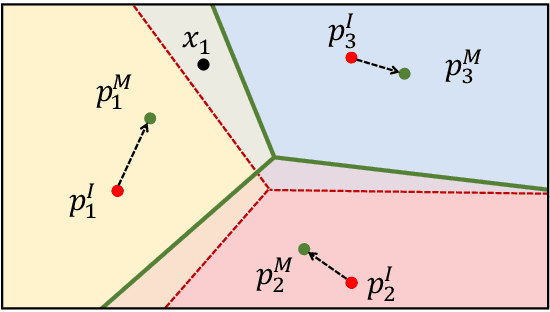
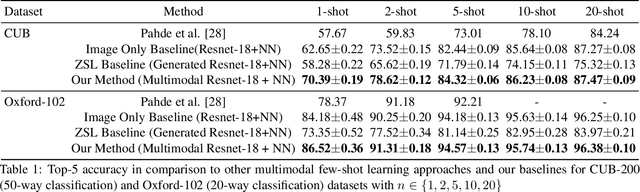
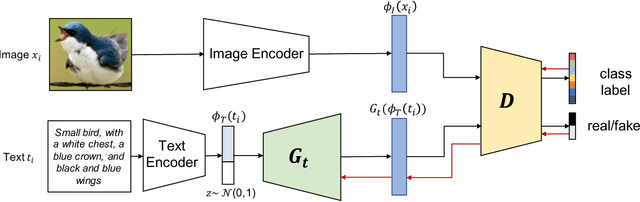
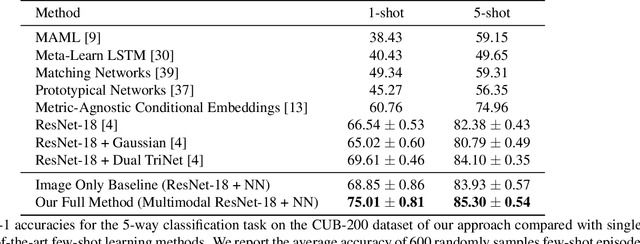
Although providing exceptional results for many computer vision tasks, state-of-the-art deep learning algorithms catastrophically struggle in low data scenarios. However, if data in additional modalities exist (e.g. text) this can compensate for the lack of data and improve the classification results. To overcome this data scarcity, we design a cross-modal feature generation framework capable of enriching the low populated embedding space in few-shot scenarios, leveraging data from the auxiliary modality. Specifically, we train a generative model that maps text data into the visual feature space to obtain more reliable prototypes. This allows to exploit data from additional modalities (e.g. text) during training while the ultimate task at test time remains classification with exclusively visual data. We show that in such cases nearest neighbor classification is a viable approach and outperform state-of-the-art single-modal and multimodal few-shot learning methods on the CUB-200 and Oxford-102 datasets.
Learning to Remember: A Synaptic Plasticity Driven Framework for Continual Learning
May 28, 2019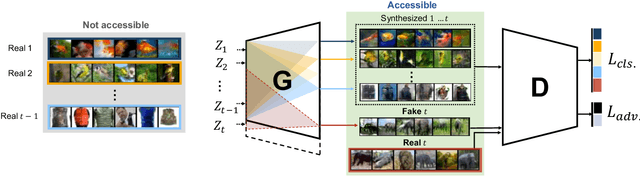
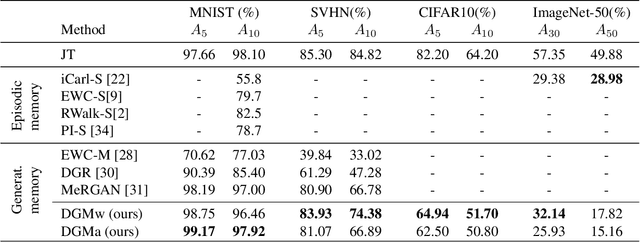
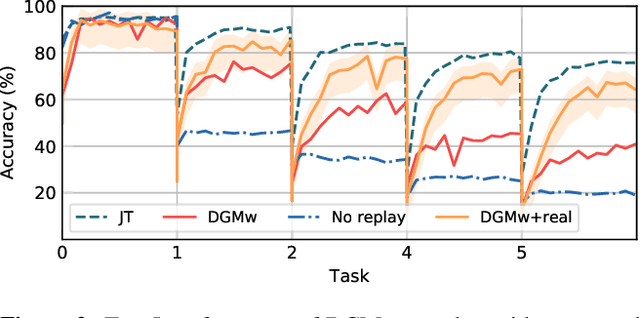
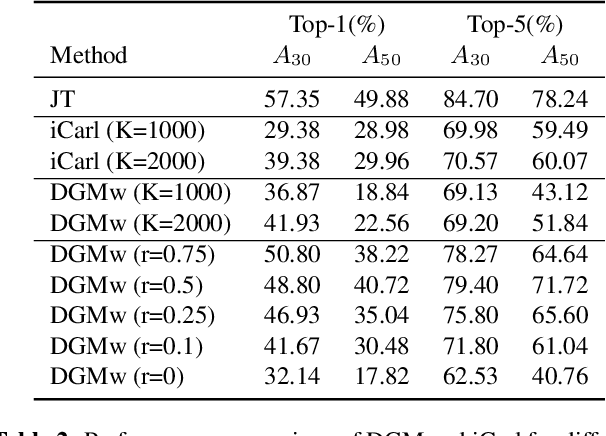
Models trained in the context of continual learning (CL) should be able to learn from a stream of data over an undefined period of time. The main challenges herein are: 1) maintaining old knowledge while simultaneously benefiting from it when learning new tasks, and 2) guaranteeing model scalability with a growing amount of data to learn from. In order to tackle these challenges, we introduce Dynamic Generative Memory (DGM) - a synaptic plasticity driven framework for continual learning. DGM relies on conditional generative adversarial networks with learnable connection plasticity realized with neural masking. Specifically, we evaluate two variants of neural masking: applied to (i) layer activations and (ii) to connection weights directly. Furthermore, we propose a dynamic network expansion mechanism that ensures sufficient model capacity to accommodate for continually incoming tasks. The amount of added capacity is determined dynamically from the learned binary mask. We evaluate DGM in the continual class-incremental setup on visual classification tasks.
Low-Shot Learning from Imaginary 3D Model
Jan 04, 2019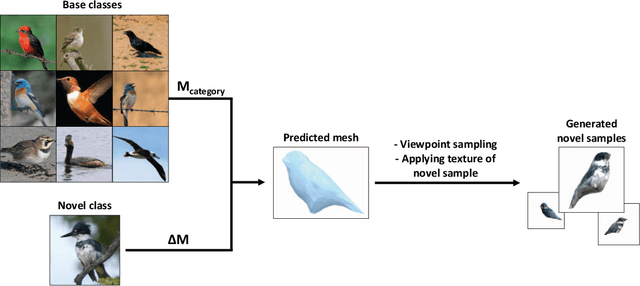
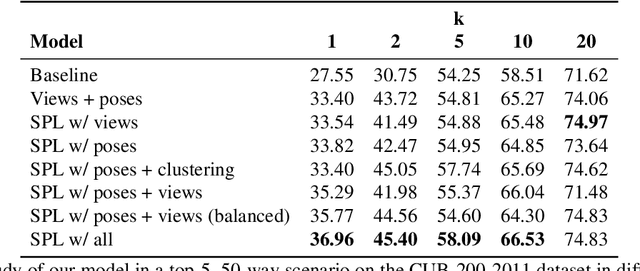
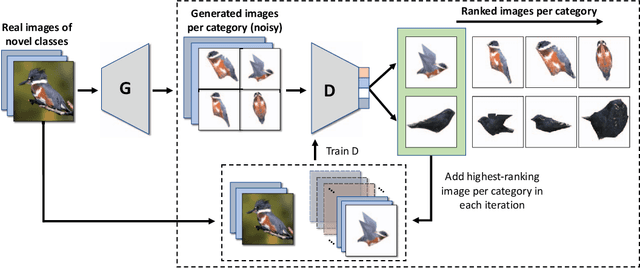

Since the advent of deep learning, neural networks have demonstrated remarkable results in many visual recognition tasks, constantly pushing the limits. However, the state-of-the-art approaches are largely unsuitable in scarce data regimes. To address this shortcoming, this paper proposes employing a 3D model, which is derived from training images. Such a model can then be used to hallucinate novel viewpoints and poses for the scarce samples of the few-shot learning scenario. A self-paced learning approach allows for the selection of a diverse set of high-quality images, which facilitates the training of a classifier. The performance of the proposed approach is showcased on the fine-grained CUB-200-2011 dataset in a few-shot setting and significantly improves our baseline accuracy.